Google Cloud Platform – User Defined Functions in BigQuery
Last Updated :
30 Mar, 2023
SQL has many built-in functions for performing calculations on data. But sometimes, your systems might need to handle data, such as string or date values, uniquely. User-defined functions are an efficient way to have these custom calculations at your fingertips when analyzing data.
In this article, we’re going to talk about how to create, store, and share user-defined functions in BigQuery. A User Defined Function or UDF lets you create a reusable function that you define, with either another SQL expression or with JavaScript. These functions accept input, perform actions, and then return a value as a result. Once you’ve created a UDF, you can reference it in queries or when creating logical views, just as you would with built-in functions.
Let’s see an example use case. Imagine an application that captures data from various sources and requires any text fields to be cleansed before they can be used for analytical purposes. We can write one UDF, we’ll call it cleanse_string to tackle this data cleansing problem. The SQL expression that defines the UDF does three things. It trims white spaces, converts text to lowercase, and removes symbols. After creating and defining the UDF, in the next part of the query statement, we can test three different strings of text through our new function. If we run the entire query. We will see the before and after results for each string of text. Once we are happy with the function’s performance, we could add it to the query statements that analyze data from our application.
#Standard_SQL
CREATE TEMP FUNCTION cleanse_string (text STRING)
RETURNS STRING
AS (REGEXP_REPLACE (LOWER (TRIM (text)), [a-zA-Z0-9]+', '')); WITH strings AS
(SELECT 'Hello, World!!!' AS text
UNION ALL
SELECT 'I am $Special$ STRING' AS text
UNION ALL
SELECT 'ABC, XYZ AS text)
SELECT text
,cleanse_string(text) AS clean_text
FROM strings;
This example includes what we call a temporary UDF, meaning it is created and used within one single query statement. However, BigQuery also supports persistent UDFs, which are defined and stored within a specific project and data set but can be reused across multiple queries and projects.
Let’s head into the console and see how to create, use, and share a persistent UDF.
Start in the Query Editor. Here you’ll define your UDF using SQL, following a specific syntax. The CREATE OR REPLACE FUNCTION indicates that you would like to create a persistent UDF. This is followed by your project ID and data set name where you want the UDF to live. Next is the name for the function itself. In this case, cleanse_string. Following in parentheses is a comma-separated list of all input parameters with their data types that your UDF requires. For cleanse_string, you have just one input, which is a string of text. On the next line, the return clause specifies the data type that the function will return. Now it’s time to provide a SQL expression that defines how to process the input. This expression uses the SQL functions TRIM to trim whitespace and LOWER to convert the text to lowercase. Then it uses a regular expression to remove any symbols. left-hand
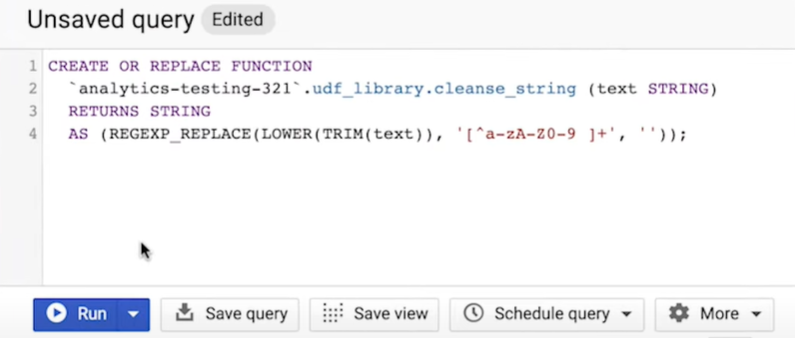
Now you’re ready to click Run to create the persistent UDF. You will see a populate under your data set in the left hand nav. Selecting the UDF allows you to view, edit, or delete it. Going forward, you can use this UDF just like you would any other SQL function, directly within your query statements. You will need to reference it with its full name, including the project and data set in which it resides. In fact, any user with adequate permission to the data set containing the UDF, such as the BigQuery data viewer role, can also reference it in their queries. By sharing data sets, you have the potential to create an org-wide library of UDFs, which in turn can ensure business logic is applied consistently and efficiently across your organization.
Share your thoughts in the comments
Please Login to comment...