Google Cloud Platform- BigQuery(Running Queries, advantage and disadvantage)
Last Updated :
30 Mar, 2023
In this article, we’re going to look into how to run a query in BigQuery. Running queries is one of the most fundamental parts of discovering insights from your data.
So let’s ask an outrageous question to BigQuery here and ask it “what is the best jersey number you should choose in order to improve your basketball game?”
It’s no surprise that big data has made its way into the world of professional sports. Teams at every level are starting to gather, process, and analyze data so that they can get the most out of their players and find a competitive edge in the game. To see how this would work, let’s check out the NCAA basketball public data set available in BigQuery. The data set contains play-by-play data for several years’ worth of games. You can get information like fouls, free throws, scores, player numbers, timeouts, and basically, as much data as the pros have. So let’s see if we can use this data for today’s question and determine which jersey number is the best three-point shooter.
If you want to follow along, use the BigQuery sandbox where you can analyze data without needing a credit card.
Step 1: Once you’re in the BigQuery sandbox, head over to the Google Cloud Marketplace by clicking on Add Data and then Explore Data Sets.
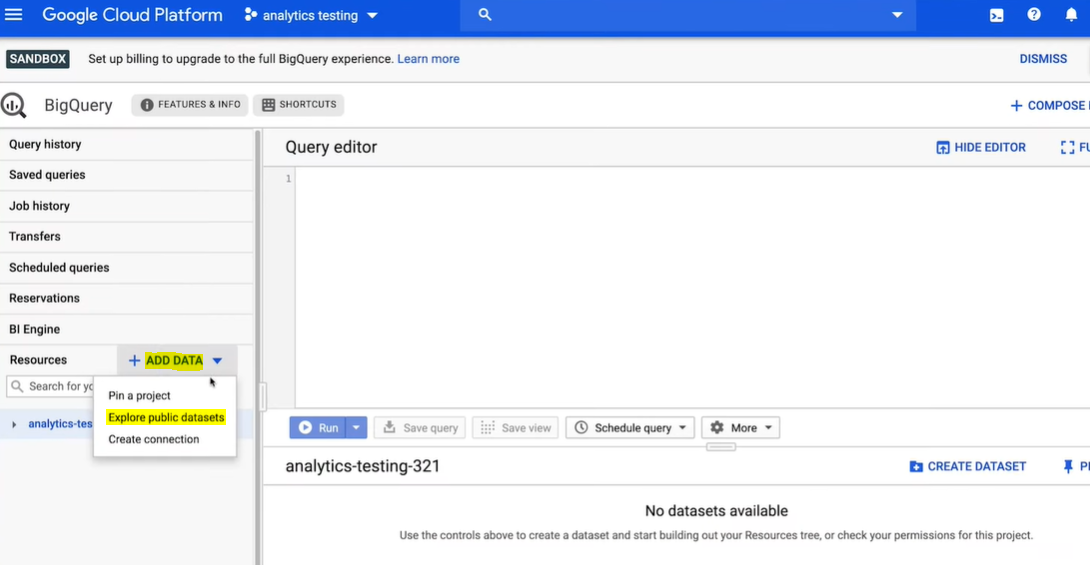
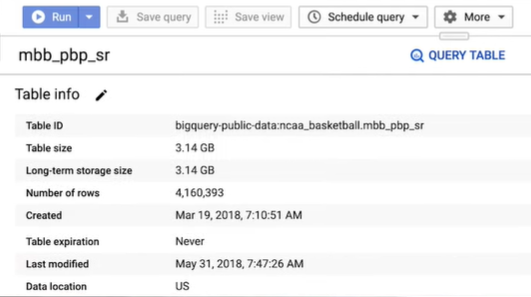
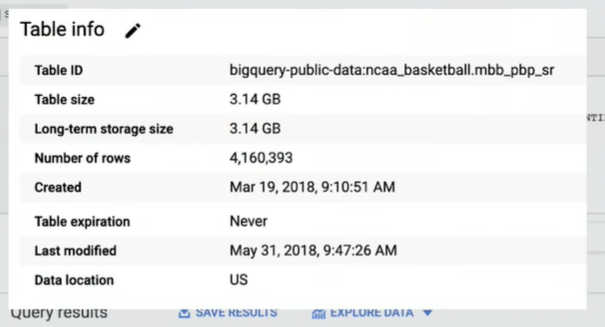
Step 2: Search for the NCAA basketball and click to launch the data set in the BigQuery UI. The NCAA basketball data set has a number of different tables. Clicking on the play-by-play table, you can first view the table details, which indicates that there are over four million rows of events. That’s a lot of basketball data.
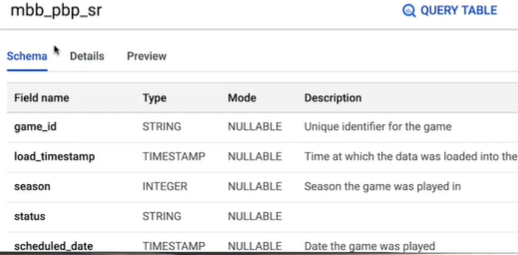
Check the table schema, and you’ll see each column or field of data that is available for each of those events.
But first, let’s look at what those events are. You can start to explore the data by clicking on the Preview tab to view a few rows of sample data. But to get a more comprehensive list of all the event types, the best way to find out is to run a query.
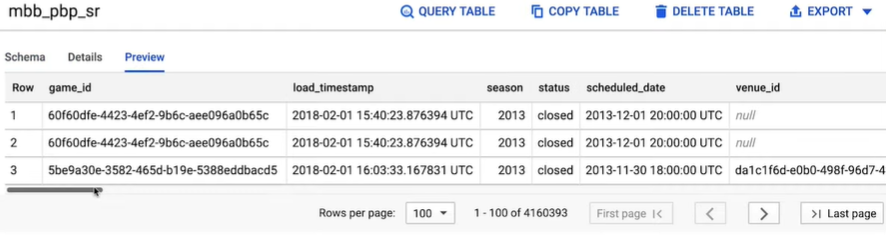
Step 3: Click Query Table and a blank query will appear in the editor with a table reference pre-populated.
Before we write our query, it’s important to know that the language used to communicate with BigQuery is SQL, or Structured Query Language. SQL is also the standard language for communicating with relational databases. BigQuery is ANSI SQL compliant.
Step 4: So now, let’s copy in a SQL query to explore the event types. backticks

The key command in SQL for retrieving data is SELECT, which we’ll use to pull in a list of all of the different event types and number of occurrences from the play-by-play table. Notice that the table reference is in the format of the GCP project name, then data set name, then table name, separated by dots and enclosed with backticks, not quotes. We’ll select all of the event types and group the results so that we can get the count of each event. The query would be as shown below:

Step 5: Once the SQL query is written, click on the green checkmark on the right-hand side of the window to open the query validator. A green checkmark means the query is valid and will show the estimated amount of data that the query will process when you run it. If the query is invalid, a red exclamation point icon is displayed. You can click on it and get some guidance on how to correct the problem.
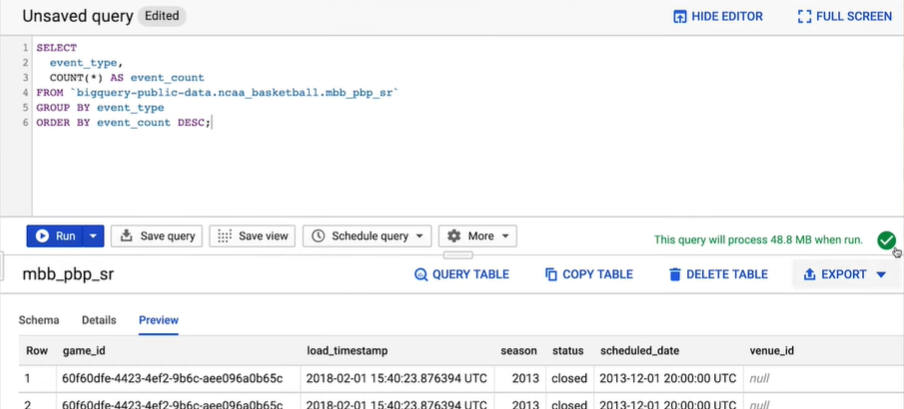
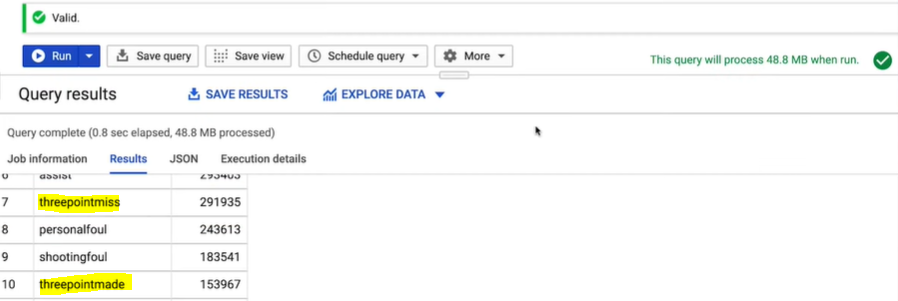
Step 6: Then click on the Run button and BigQuery gets to work. After the query execution is complete, the query service displays the results as a table on the web UI. You can see that the Event Type column has both three-point made and three-point miss events.
Step 7: Now we can write a new query that selects the jersey number for each play-by-play event and then uses the Event Types column to determine the three-point field goal accuracy for each jersey number. Click Run and then in less than a second we have the answer.
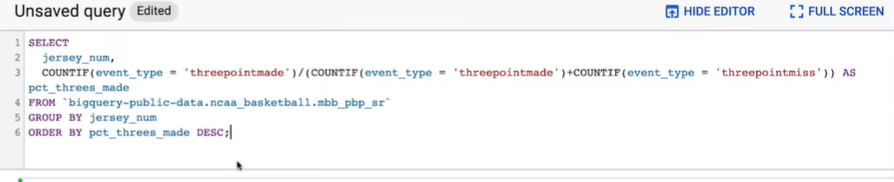
So according to BigQuery number 45 sinks the highest percentage of their three-pointer attempts.
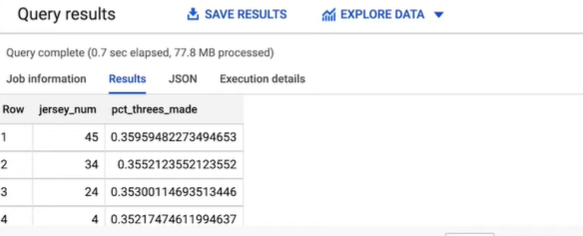
Note: We can see that the table we queried has three gigabytes of data. But BigQuery only read the columns needed and therefore just processed 78 megabytes of data.
BigQuery is a fully managed, cloud-native data warehousing platform that enables super-fast SQL queries using the processing power of Google’s infrastructure. It is a serverless, highly scalable, and cost-effective data storage and analytics service that allows you to analyze large and complex datasets quickly and efficiently. BigQuery is designed to handle large volumes of data, both structured and unstructured, and can process up to trillions of rows per second. It is a popular choice for data warehousing, analytics, and machine learning applications, and is often used to power business intelligence dashboards and reports. BigQuery is fully integrated with other Google Cloud Platform (GCP) services, making it easy to analyze data in conjunction with other GCP resources and tools.
BigQuery offers a number of features that make it a powerful and flexible data warehousing platform:
- Serverless: BigQuery is a fully managed service, which means that you don’t have to worry about infrastructure, capacity planning, or maintenance.
- Scalability: BigQuery is designed to handle very large datasets and can scale to petabyte-sized data warehouses.
- High performance: BigQuery uses a columnar storage format and advanced query optimization techniques to achieve fast query performance on large datasets.
- Integration with other GCP services: BigQuery is fully integrated with other GCP services, such as Cloud Storage, Cloud Functions, and Data Studio, making it easy to analyze data in conjunction with other GCP resources and tools.
- SQL support: BigQuery supports a variant of the standard SQL language, making it easy to query data using familiar SQL syntax.
- Data streaming: BigQuery allows you to stream data in real time, enabling real-time analysis of streaming data.
- Machine learning: BigQuery provides built-in machine learning functions and integration with TensorFlow, making it easy to build and deploy machine learning models on large datasets.
- Data security: BigQuery offers a number of security features, including encryption of data at rest and in transit, access control, and compliance with industry standards such as GDPR and HIPAA.
There are a few potential disadvantages to using BigQuery:
- Cost: While BigQuery is generally a cost-effective data warehousing solution, it can be expensive for certain types of workloads, such as those with a high volume of small queries or those that require a lot of data processing.
- Limited customization: As a fully managed service, BigQuery does not offer as much flexibility or customization as on-premises data warehousing solutions.
- Dependence on GCP: Because BigQuery is a part of the Google Cloud Platform (GCP), you will need to be comfortable using GCP and relying on it for your data warehousing needs.
- Limited integrations: While BigQuery is fully integrated with other GCP services, it may not have as many integrations with non-GCP tools and services as some other data warehousing solutions.
- Complexity: BigQuery can be complex to use, especially for users who are new to data warehousing or SQL. It may require a significant learning curve for users who are not familiar with these technologies.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...