Feature selection using SelectFromModel and LassoCV in Scikit Learn
Last Updated :
06 Mar, 2024
Feature selection is a critical step in machine learning and data analysis, aimed at identifying and retaining the most relevant variables in a dataset. It not only enhances model performance but also reduces overfitting and improves interpretability. In this guide, we delve into the world of feature selection using Scikit-Learn, a popular Python library for machine learning. Specifically, we explore the SelectFromModel class and the LassoCV model, showcasing their synergy for efficient feature selection.
Feature Selection
In machine learning, selecting the most significant and pertinent features from the initial set of variables is known as feature selection. Its objective is to improve interpretability, minimize overfitting, and reduce dimensionality to improve model performance. The model becomes more effective by choosing the most informative features, which results in quicker training times and improved generalization to new, untested data. Model-based procedures, feature importance scores, and statistical tests are common methodologies.
Concepts related to Feature selection using SelectFromModel and LassoCV
- L1 Regularization (Lasso): L1 regularization, also referred to as Lasso, is a machine-learning regularization technique that penalizes the absolute values of a model’s coefficients. By adding a regularization component to the cost function, it pushes some coefficients to exactly zero, which promotes sparsity. When it comes to feature selection, Lasso works well since it can automatically recognize and highlight the most important traits while lessening the impact of less important ones. This regularization adds to better generalization performance, improves the interpretability of the model, and inhibits overfitting.
- SelectFromModel: With the use of a pre-trained model’s feature importance scores, the scikit-learn feature selection method SelectFromModel automatically determines which features are the most significant. Following training, only features that meet a user-specified threshold of significance are retained by the model (either tree-based or linear). In addition to maintaining or even improving prediction performance, this strategy simplifies models by emphasizing the most informative aspects, encouraging efficiency, and improving interpretability.
- LassoCV: With a cross-validated selection of the regularization strength (alpha), LassoCV is a scikit-learn package that carries out L1 regularization (Lasso). It uses internal cross-validation to automate the process of alpha tuning by choosing the value that minimizes mean squared error. This makes it possible for linear models to choose features and regularize them effectively, balancing predictability and simplicity while reducing overfitting.
How SelectFromModel and LassoCV work together
SelectFromModel leverages the relevance rankings supplied by LassoCV. LassoCV first trains a Lasso regression model on the training data, computing significance scores for each feature by assessing the difference in model performance when the feature is eliminated. SelectFromModel then utilizes these relevance scores to choose the most significant features.
Feature selection using SelectFromModel and LassoCV in Scikit Learn
Importing necessary libraries
Python3
import numpy as np
import pandas as pd
from sklearn.linear_model import LassoCV
from sklearn.feature_selection import SelectFromModel
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.datasets import load_breast_cancer
from sklearn.ensemble import RandomForestClassifier
import matplotlib.pyplot as plt
import seaborn as sns
|
This code selects features using L1 regularization (LassoCV) on the Breast Cancer dataset using scikit-learn. After dividing the data into training and testing sets, SelectFromModel is used to save significant features based on L1 regularization, and a RandomForestClassifier is used to calculate feature importances. Lastly, it assesses the RandomForestClassifier’s classification report, offering an understanding of the model’s effectiveness.
Loading the Breast Cancer dataset and splitting the data
Python3
cancer = load_breast_cancer()
X, y = cancer.data, cancer.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
|
The load_breast_cancer function from scikit-learn is used in this code to load the Breast Cancer dataset. Then, using train_test_split from scikit-learn, it divides the data into training and testing sets, with 80% going to training and 20% to testing. By fixing the random seed used for the data split, the random_state parameter guarantees reproducibility.
Fitting the LassoCV model
Python3
lasso_cv = LassoCV(cv=5)
lasso_cv.fit(X_train, y_train)
|
Using 5-fold cross-validation (cv=5), this code fits a LassoCV model using the LassoCV class from scikit-learn. It automatically evaluates performance over several folds in order to get the ideal regularization strength (alpha). X_train and y_train, the training data, are used to train the model.
Feature selection using SelectFromModel
Python3
sfm = SelectFromModel(lasso_cv, prefit=True)
X_train_selected = sfm.transform(X_train)
X_test_selected = sfm.transform(X_test)
|
Using scikit-learn’s SelectFromModel, this code selects features. It selects the most significant features from the training and testing sets (X_train and X_test) using the pre-trained LassoCV model (lasso_cv). Only the features determined to be relevant by the L1 regularization are included in the final selected feature sets, which are saved in X_train_selected and X_test_selected.
Training a Random Forest Classifier using the selected features
Python3
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train_selected, y_train)
|
Using the RandomForestClassifier from scikit-learn, this code trains a Random Forest classifier. For reproducibility, a fixed random state (random_state=42) and 100 decision trees (n_estimators=100) are used in the classifier’s configuration. After that, it is fitted to the training set (X_train_selected and y_train) using just the features that were chosen during the LassoCV feature selection process.
Evaluating the model
Python3
y_pred = model.predict(X_test_selected)
print(classification_report(y_test, y_pred))
|
Output:
precision recall f1-score support
0 0.97 0.86 0.91 43
1 0.92 0.99 0.95 71
accuracy 0.94 114
macro avg 0.95 0.92 0.93 114
weighted avg 0.94 0.94 0.94 114
Using the trained Random Forest Classifier on the testing set (X_test_selected), this method produces predictions (y_pred). Afterwards, it uses the classification_report function from scikit-learn to print a classification report that includes detailed performance metrics for each class in the binary classification job, including F1-score, precision, and recall. This report facilitates the evaluation of the model’s performance on the hidden data.
Analyzing selected features and their importance
Python3
selected_feature_indices = np.where(sfm.get_support())[0]
selected_features = cancer.feature_names[selected_feature_indices]
coefficients = lasso_cv.coef_
print("Selected Features:", selected_features)
print("Feature Coefficients:", coefficients)
|
Output:
Selected Features: ['mean area' 'worst texture' 'worst perimeter' 'worst area']
Feature Coefficients: [-0. -0. -0. 0.00025492 -0. -0.
-0. -0. -0. -0. -0. -0.
-0. -0. -0. -0. -0. -0.
-0. -0. -0. -0.00999371 -0.01746145 0.00026856
-0. -0. -0. -0. -0. -0. ]
Using the LassoCV feature selection, this code evaluates the chosen features and their relative importance. Using sfm.get_support(), it obtains the indices of the chosen features and maps them to the relevant feature names in the Breast Cancer dataset. The coefficients from the LassoCV model (lasso_cv.coef_) are used to print the feature coefficients. This data sheds light on the applicability and value that each feature that was chosen has to the model.
Extracting selected features from the original dataset and creating a DataFrame
Python3
X_selected_features = X_train[:, selected_feature_indices]
selected_features_df = pd.DataFrame(X_selected_features, columns=selected_features)
selected_features_df['target'] = y_train
|
With the help of the feature selection indices, this method extracts the chosen features from the original training dataset (X_train). To better illustrate the chosen features, a DataFrame (selected_features_df) is subsequently created. Each chosen feature and the target variable (‘target’) for possible coloring are shown in columns of the DataFrame. In the context of the training data, this structured representation makes it easier to comprehend the correlations between the selected features and the target variable.
Plotting a scatter plot of the two most important features
Python3
sns.scatterplot(x='mean area', y='worst area', hue='target', data=selected_features_df, palette='viridis')
plt.xlabel('Mean Area')
plt.ylabel('Worst Area')
plt.title('Scatter Plot of Two Most Important Features - Breast Cancer Dataset')
plt.show()
|
Output:
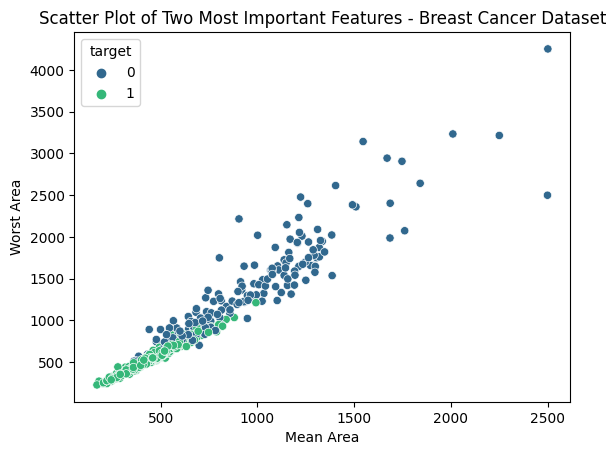
This code uses Seaborn to create a scatter plot that shows the association between the “mean area” and “worst area,” two features that were chosen from the Breast Cancer dataset. The target variable (“target”) determines the color of the points, making it possible to visually examine any potential patterns or separability between the two classes.
In this article, we discussed the concept of feature selection using SelectFromModel and LassoCV in scikit-learn. This method allows you to automatically select the most relevant features and improve the efficiency of your machine learning models. By incorporating L1 regularization and cross-validation, you can enhance the robustness and accuracy of your feature selection process.
Share your thoughts in the comments
Please Login to comment...