FaceNet – Using Facial Recognition System
Last Updated :
13 Jun, 2022
FaceNet is the name of the facial recognition system that was proposed by Google Researchers in 2015 in the paper titled FaceNet: A Unified Embedding for Face Recognition and Clustering. It achieved state-of-the-art results in the many benchmark face recognition dataset such as Labeled Faces in the Wild (LFW) and Youtube Face Database.
They proposed an approach in which it generates a high-quality face mapping from the images using deep learning architectures such as ZF-Net and Inception Network. Then it used a method called triplet loss as a loss function to train this architecture. Let’s look at the architecture in more detail.
Architecture is as follows:

FaceNet architecture
FaceNet employs end-to-end learning in its architecture. It uses ZF-Net or Inception Network as its underlying architecture. It also adds several 1*1 convolutions to decrease the number of parameters. These deep learning models output an embedding of the image f(x) with L2 normalization performed on it. These embeddings are then passed into the loss function to calculate the loss. The goal of this loss function is to make the squared distance between two image embeddings (independent of image condition and pose )of the same identity small, whereas the squared distance between two images of different identities is large. Therefore a new loss function called Triplet loss is used. The idea of using triplet loss in our architecture is that it helps the model enforce a margin between faces of different identities.
Triplet loss:
The embedding of an image is represented by f(x) such as x  . This embedding is in the form of vector of size 128 and it is normalized such that
. This embedding is in the form of vector of size 128 and it is normalized such that

We want to make sure that the anchor image ( ) of a person is closer to a positive image() (image of the same person) as compared to a negative image() (image of another person) such that:
) of a person is closer to a positive image() (image of the same person) as compared to a negative image() (image of another person) such that:


where  is the margin that is enforced to differentiate between positive and negative pairs and
is the margin that is enforced to differentiate between positive and negative pairs and  are the image space.
are the image space.
Therefore the loss function is defined as the following :
![L = \sum_{i}^{N}\left [ \left \| f\left ( x_i^a \right ) - f\left ( x_i^p \right ) \right \|_{2}^{2} - \left \| f\left ( x_i^a \right ) - f\left ( x_i^n \right ) \right \|_{2}^{2} +\alpha \right ]](https://www.geeksforgeeks.org/wp-content/ql-cache/quicklatex.com-8b82f356ed725e2724718428e171d0bc_l3.png "Rendered by QuickLaTeX.com")
When we train the model if we choose triplets that easily satisfied the above property then it would not help in better training of the model, so it is important to have the triplets that violate the above equation.
Triplet selection:
In order to ensure faster learning, we need to take triplets that violate the equation above. This means for given  we need to select triplets such that
we need to select triplets such that  is maximum and
is maximum and  is minimum . It is computationally expensive to generate triplets based on whole training set. There are two methods of generating triplets.
is minimum . It is computationally expensive to generate triplets based on whole training set. There are two methods of generating triplets.
- Generating triplets on every step on the basis of previous checkpoints and compute minimum and maximum
on a subset of data. - Selecting hard positive (
 ) and hard negative () by using minimum and maximum on a mini batch.
) and hard negative () by using minimum and maximum on a mini batch.

Triplet-loss and learning
Training:
This model is trained using Stochastic Gradient Descent (SGD) with backpropagation and AdaGrad. This model is trained on a CPU cluster for 1k-2k hours. The steady decrease in loss (and increase in accuracy) was observed after 500 hours of training. This model is trained using two networks :
- ZF-Net: The visualization below indicates the different layers of ZF-Net used in this architecture with their memory requirement:

ZF-Net architecture in FaceNet
As we notice that there are 140 million parameters in the architecture and 1.6 billion FLOPS memory is required to train this model.
Inception Network:
The visualization below indicates the different layers of Inception model used in this architecture with their memory requirement:
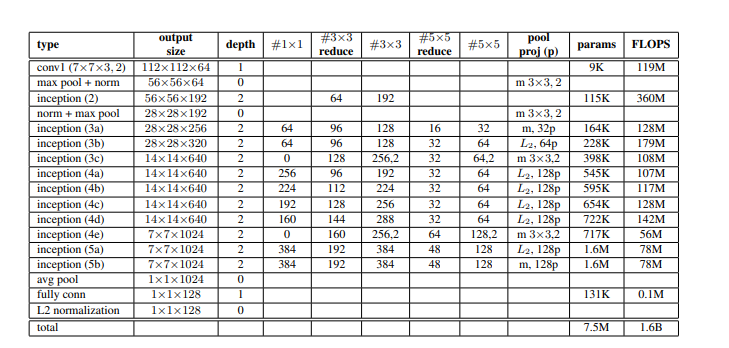
Inception Architecture used in FaceNet
- As we notice that there are only 7.5 million parameters in the architecture but 1.6 billion FLOPS memory is required to train this model (which is similar to ZF-Net).
Results: This model uses 4 different types of architecture on Labeled Faces in the wild and Youtube Face DB dataset.
Labeled Faces in the Wild Dataset:
This architecture uses standard, non-restricted protocol on the LFW dataset. First, this model uses 9 training splits to set L2 distance threshold value, and then on the tenth split, it classifies the two images as same or different.
There are two methods of preprocessing the images of dataset on which accuracy is reported:
- Fixed center crop of the image provided in LFW
- A face detector is used on LFW images if that fails then LFW face alignment is used
This model achieves a classification accuracy of 98.87% accuracy with 0.15% standard error and in the second case 99.63% accuracy with 0.09% standard error. This reduces the error rate reported by DeepFace by a factor of more than 7 and other state-of-the-art DeepId by 30%.
Youtube Face database:
On Youtube Face Dataset it reported an accuracy of 95.12% with a standard error 0.39using the first 100 frames. It is better than the 91.4% accuracy proposed by DeepFace and 93.5% reported by DeepId on 100 frames.

Face Clustering using FaceNet
A result of Face clustering (clustering of images of the same person) from FaceNet paper shows that the model is invariant to occlusion, pose, lighting, and even age, etc.
References: FaceNet paper
Share your thoughts in the comments
Please Login to comment...