Cluster Graph in R
Last Updated :
12 Oct, 2023
R’s cluster graph functionality can be a useful tool for visualizing data and seeing patterns within it. In disciplines including biology, the social sciences, and data analysis, cluster graphs are frequently used to group together related data points. In this article, we’ll demonstrate how to display a cluster graph in R by combining the ggplot2 package for data analysis and visualization with the ggraph tool for graph visualization.
Cluster Analysis
Cluster analysis is a technique used in data science and statistics to group similar data points together. It is commonly applied in various fields such as biology, marketing, and social sciences for tasks like customer segmentation, species classification, and identifying patterns in data. Cluster analysis algorithms aim to find meaningful clusters in your data based on similarity or dissimilarity measures.
Hierarchical Clustering
A bottom-up method of clustering is hierarchical clustering. By gradually merging or separating clusters, it builds a hierarchy of clusters. A dendrogram, a structure like a tree, is frequently used to represent the outcome. The dendrogram can be clipped at a given height to produce the required number of clusters.
Dendrogram
A cluster graph, also known as a dendrogram or a tree diagram, is a graphical representation of the clustering results. It shows how data points or clusters are grouped together and can provide insights into the hierarchical structure of your data. Two popular methods for creating cluster graphs are hierarchical clustering and k-means clustering.
Hierarchical Clustering in R
R
set.seed(123)
data <- matrix(rnorm(50), ncol = 2)
hi_cl <- hclust(dist(data))
plot(hi_cl)
|
Output:
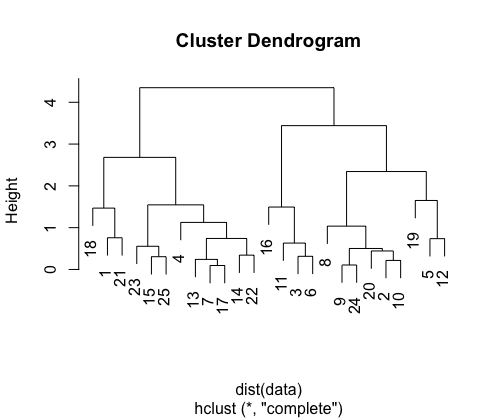
In this example, we first generate random data and then perform hierarchical clustering using the hclust function. We use the Euclidean distance (dist) as the dissimilarity measure. and generates a dendrogram visualization of the hierarchical clustering results. You can cut the dendrogram at a specific height to obtain clusters.
K-Means Clustering
An unsupervised non-linear approach called K Means Clustering in R programming organises data based on similarity or similar groups. Specifically, it aims to divide the observations into a predetermined number of clusters. Data is segmented in order to group each training example into a segment known as a cluster. In the unsupervised method, a lot of emphasis is placed on providing raw data while also spending a lot of money on manual review to determine relevance. It is utilised in a number of industries, including banking, healthcare, retail, and media.
K-Means Clustering in R
K-means clustering is a partitioning method that aims to divide data into a pre-specified number of clusters, denoted as “k.” Each data point belongs to the cluster with the nearest mean (centroid).
R
library(ggplot2)
library(cluster)
data(mtcars)
head(mtcars)
|
Output:
mpg cyl disp hp drat wt qsec vs am gear carb
Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
Valiant 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1
Plot the clustering
R
kmeans_model <- kmeans(mtcars[, c("mpg", "hp")], centers = 3)
ggplot(data = mtcars, aes(x = mpg, y = hp, color = as.factor(kmeans_model$cluster))) +
geom_point(size = 4) +
scale_color_manual(values = c("#1f77b4", "#ff7f0e", "#2ca02c")) +
labs(title = "Car Segmentation Based on MPG and Horsepower",
x = "Miles per Gallon (mpg)",
y = "Horsepower (hp)") +
theme_minimal()
|
Output:
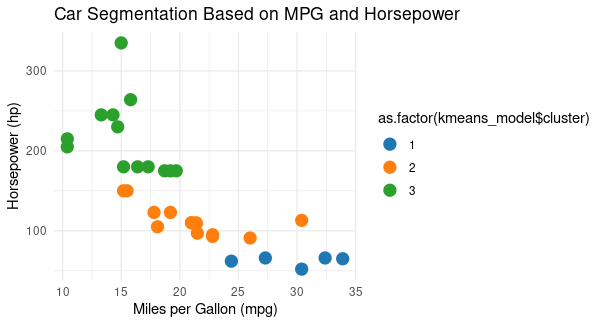
KMeans Clustering using R
We use ggplot2 to create a scatterplot.
- The points are colored according to the cluster assignments.
- The color scheme is customized to make the plot more attractive.
- We add a title and axis labels to improve the plot’s informativeness.
- We use a minimal theme for a clean and attractive appearance.
This code will create an attractive scatterplot visualizing customer segments based on annual income and spending score.
Cluster graph on USArrest dataset
We use the “USArrests” dataset, which contains crime statistics for different U.S. states. We’ll perform k-means clustering with k=3 clusters and visualize the results using the “factoextra” and “factoMineR” libraries.
Install and load the required libraries. If not already installed, run:
install.packages("factoextra")
install.packages("factoMineR")
Load the package and dataset
R
library(factoextra)
library(factoMineR)
data("USArrests")
|
Explore the dataset
We use functions like head(USArrests) to check the structure of the dataset.
Output:
Murder Assault UrbanPop Rape
Alabama 13.2 236 58 21.2
Alaska 10.0 263 48 44.5
Arizona 8.1 294 80 31.0
Arkansas 8.8 190 50 19.5
California 9.0 276 91 40.6
Colorado 7.9 204 78 38.7
Perform K-Means Clustering
R
kmeans_model <- kmeans(USArrests, centers = 3)
fviz_cluster(kmeans_model, data = USArrests, geom = "point")
|
Output:
.png)
Display Custer Graph
We perform k-means clustering on the “USArrests” dataset. Specifically, you are creating a k-means model with three clusters (centers = 3). The result, kmeans_model, will contain information about the clusters, including cluster assignments for each data point and the cluster centers.
- fviz_cluster: This function is used to create cluster visualizations. It takes the k-means model kmeans_model as input.
- data = USArrests: This specifies the dataset you are working with, which is “USArrests” in this case.
- geom = “point”: This specifies that you want to represent the data points as points in the plot.
The resulting plot will show the data points colored according to their assigned clusters, and it will also display the cluster centers. This visualization allows you to see how the data has been segmented into clusters by the k-means algorithm.
Conclusion
The use of cluster graphs can help you comprehend the structure of your data and spot trends or groups within it. R offers robust utilities like hclust and kmeans along with visualisation tools like ggplot2 to help you construct interesting cluster graphs whether you use hierarchical clustering or k-means clustering. To get deeper insights from your data, experiment with various clustering methods, dissimilarity metrics, and visualization options.
Share your thoughts in the comments
Please Login to comment...