How CatBoost algorithm works
Last Updated :
09 Nov, 2023
CatBoost is an acronym that refers to “Categorical Boosting” and is intended to perform well in classification and regression tasks. CatBoost’s ability to handle categorical variables without the requirement for manual encoding is one of its primary advantages. It employs a method known as Ordered Boosting to handle the difficulties faced by categorical features such as large cardinality. This enables CatBoost to handle categorical data automatically, saving the user time and effort.CatBoost’s basic idea is its ability to effectively and efficiently handle categorical features. It implements a novel technique called Ordered Boosting, which generates a numerical representation by permuting the categorical variables. This method maintains the category information while allowing the model to use the powerful gradient-boosting technique.
What is CatBoost?
CatBoost, the cutting-edge algorithm developed by Yandex is always a go-to solution for seamless, efficient, and mind-blowing machine learning, classification and regression tasks. With its innovative Ordered Boosting algorithm, CatBoost takes the predictions to new heights by harnessing the power of decision trees. In this article, you’ll explore, the workings of catboost algorithm.
Key features related to CatBoost :
The key features related to CatBoost are as follows:
- Gradient boosting: It is a powerful ensemble learning technique that combines weak prediction models, often decision trees, to construct a powerful predictive model. It works by iteratively adding new models to the ensemble, each one trained to correct the errors made by the previous models. Gradient boosting is used by CatBoost to increase model accuracy by focusing on misclassified examples.
- Categorical Features: Categorical features, such as colour or type, are variables that reflect qualitative data. CatBoost handles categorical characteristics effectively without the need for substantial preprocessing or one-shot encoding, making it an effective tool for real-world datasets.
- Learning rate: The learning rate controls the step size at which the model learns during the boosting phase. To balance the model’s learning speed and accuracy, CatBoost automatically picks an ideal learning rate based on the dataset features.
- L2 regularization: It is also known as ridge regularization, introduces a penalty term into the loss function to prevent overfitting and improve the generalization ability of the model. In the context of CatBoost, L2 regularization is a key feature that helps to control the complexity of the boosted trees. It achieves this by adding a regularization term to the loss function used during the training process.
Workings of Catboost
CatBoost is a powerful gradient-boosting technique designed for machine learning tasks, particularly those involving structured input. It leverages the concept of gradient boosting, which is an ensemble learning method. The algorithm starts by making an initial guess, often the mean of the target variable. It then gradually constructs an ensemble of decision trees, with each tree aiming to reduce the errors or residuals from the previous trees.
One of the key strengths of CatBoost is its ability to handle categorical features effectively. It employs a technique called “ordered boosting” to directly process categorical data, leading to faster training and improved model performance. This is achieved by encoding the categorical features in a way that preserves the natural ordering of the categories.
To prevent overfitting, CatBoost incorporates regularization techniques. These techniques introduce penalties or constraints during the training process to discourage the model from becoming too complex and fitting thе training data too closely. Regularization helps to generalize the model and make it more robust to unseen data.
The algorithm iteratively constructs the ensemble of trees by minimizing the loss function using gradient descent. At each iteration, it calculates the negative gradient of the loss function with respect to the current predictions and fits a new tree to the negative gradient. The learning rate determines the step size taken during gradient descent. The process is repeated until a predetermined number of trees have been added or a convergence criterion has been met. When making predictions, CatBoost combines the predictions from all the trees in the ensemblе. This aggregation of predictions results in highly accurate and reliable models.
Mathematically,
CatBoost can be represented as follows:
Given a training datasеt with N samples and M features, where each sample is denoted as (x_i, y_i), as x_i is a vector of M features and y_i is the corresponding target variablе, CatBoost aims to learn a function F(x) that predicts the target variable y.

where,
- F(x) represents thе overall prediction function that CatBoost aims to learn. It takes an input vector x and predicts the corresponding target variable y.
 is the initial guess or the baseline prediction. It is often set as the mean of the target variable in the training dataset. This term captures the overall average behavior of the target variable.
is the initial guess or the baseline prediction. It is often set as the mean of the target variable in the training dataset. This term captures the overall average behavior of the target variable. represents the summation over the ensemble of trees. M denotes the total number of trees in the ensemble.
represents the summation over the ensemble of trees. M denotes the total number of trees in the ensemble. represents the summation over the training samples. N denotes the total number of training samples.
represents the summation over the training samples. N denotes the total number of training samples. represents the prediction of the m-th tree for the i-th training sample. Each tree in the ensemble contributes to the overall prediction by making its own prediction for each training sample.
represents the prediction of the m-th tree for the i-th training sample. Each tree in the ensemble contributes to the overall prediction by making its own prediction for each training sample.
The equation states that the overall prediction F(x) is obtained by summing up the initial guess F_0(x) with thе predictions of each tree f_m(x_i) for each training sample. This summation is performed for all trees (m) and all training samples (i).
Getting started with CatBoost :
Install the Packages
!pip install catboost
Step 1: Importing Necessary Libraries
Before we begin coding, we must first import the appropriate libraries. We’ll use the pandas package for data manipulation and the CatBoost library for algorithm implementation.
Python3
import pandas as pd
from catboost import CatBoostClassifier
from sklearn.metrics import accuracy_score
from sklearn.metrics import classification_report
from matplotlib import pyplot as plt
from sklearn.preprocessing import LabelEncoder
|
Step 2: Loading the Dataset
Dataset link :Titanic Dataset
Python3
titanic_data = pd.read_csv('titanic.csv')
titanic_data = titanic_data.drop(['Name', 'Ticket', 'Cabin'], axis=1)
|
Step 3: Preprocessing the Dataset
Preprocessing processes will be performed for the dataset. Missing values will be handled, categorical variables will be converted to numeric representations, and the data will be divided into training and testing sets.
Python
titanic_data['Age'].fillna(titanic_data['Age'].mean(), inplace=True)
titanic_data['Embarked'].fillna(titanic_data['Embarked'].mode()[0], inplace=True)
le=LabelEncoder()
titanic_data[['Sex','Embarked']] = titanic_data[['Sex','Embarked']].apply(le.fit_transform)
X = titanic_data[['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare']]
y = titanic_data['Survived']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
|
Step 4: Setup and Training the CatBoost Model
We’ll now initialize the CatBoostClassifier and define the training hyperparameters. We’ll determine the number of iterations, learning rate, and tree depth. Finally, the model will be fitted to the training data.
Python3
model = CatBoostClassifier(iterations=100, learning_rate=0.1, depth=6)
model.fit(X_train, y_train)
|
Step 5: Assessing the Model’s Performance
We can evaluate the model’s performance on the testing data after it has been trained. To understand the precision, recall, and F1-score of the model, we’ll compute the accuracy score and provide a classification report.
Python3
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
classification_report = classification_report(y_test, y_pred)
print("Accuracy:", accuracy)
print("Classification Report:\n", classification_report)
|
Output:
98: learn: 0.3625223 total: 257ms remaining: 2.59ms
99: learn: 0.3621516 total: 259ms remaining: 0us
Accuracy: 0.7988826815642458
Classification Report:
precision recall f1-score support
0 0.79 0.89 0.84 105
1 0.81 0.68 0.74 74
accuracy 0.80 179
macro avg 0.80 0.78 0.79 179
weighted avg 0.80 0.80 0.80 179
Step 6: Feature Importance with CatBoost
CatBoost includes an in-built feature importance approach for determining the importance of each feature in the model. A bar plot can be used to show the feature significance scores.
Python
feature_importance = model.get_feature_importance()
feature_names = X.columns
plt.bar(feature_names, feature_importance)
plt.xlabel("Feature Importance")
plt.title("CatBoost Feature Importance")
plt.show()
|
Output:
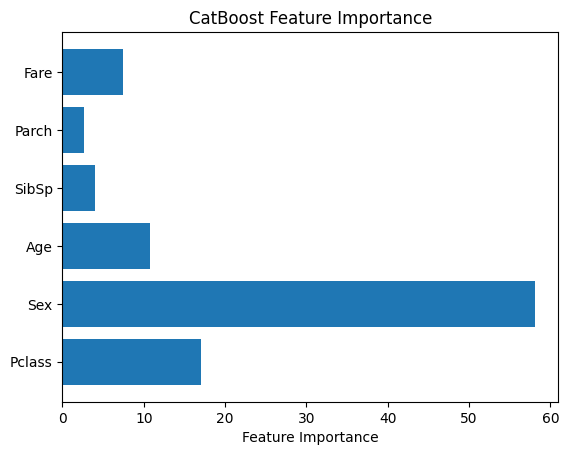
feature importance generated by matplotlib
Conclusion
To summarize, CatBoost is a powerful and user-friendly gradient boosting library that is appropriate for a wide range of applications. Whether you’re a newbie searching for a simple approach to machine learning or an experienced practitioner looking for top-tier performance, CatBoost is a useful tool to have in your toolbox. However, as with any tool, its success is dependent on the individual problem and dataset, therefore it’s always a good idea to experiment with it and compare it to other techniques.
Share your thoughts in the comments
Please Login to comment...