Multiclass or multinomial classification is a fundamental problem in machine learning where our goal is to classify instances into one of several classes or categories of the target feature. CatBoost is a powerful gradient-boosting algorithm that is well-suited and widely used for multiclass classification problems. In this article, we will discuss the step-by-step implementation of CatBoost for multiclass classification.
What is Multiclass Classification
Multiclass classification is a kind of supervised learning task in machine learning that involves classifying instances into one of three or more distinct classes or categories of the target feature. For multiclass classification, the minimum number of classes of the target feature should be three. In Binary classification tasks, our goal is to classify instances into one of two classes (like fraud detected or no fraud). Still, multiclass classification is used for problems where multiple possible outcomes are there. Multiclass classification can be used in various fields of Natural Language Processing tasks like Sentiment analysis(positive, negative, or neutral), text categorization language identification, etc. Also in speech recognition and recommendation systems(like recommending products, movies, or any content to users based on their preferences and behavior) multiclass classification is used.
What is CatBoost
CatBoost or Categorical Boosting is a machine learning algorithm developed by Yandex, a Russian multinational IT company. This special boosting algorithm is based on the gradient boosting framework and is designed to handle categorical features more effectively than traditional gradient boosting algorithms. CatBoost incorporates techniques like ordered boosting, oblivious trees, and advanced handling of categorical variables to achieve high performance with minimal hyperparameter tuning. CatBoost classifier is an implementation of the CatBoost algorithm which is specifically used for classification task. CatBoost is very efficient for multiclass classification problems. Next we will see a step-by-step guide for implementation of CatBoost classifier for Multiclass classification using Iris dataset. Then a detailed Exploratory Data Analysis is given for understanding dataset. After that, we will develop a user interface where this model will run in background and users can give input and get real-time predicted results.
Implementation of Multiclass classification using CatBoost
Installing CatBoost
CatBoost module doesn’t come by default. We need to download it manually to our Python runtime environment.
Importing required libraries
Now, we will import all necessary Python libraries required for this implementation like Pandas, NumPy, SKlearn, joblib, Seaborn and Matplotlib etc.
Python3
import pandas as pd
from catboost import CatBoostClassifier
from sklearn.metrics import accuracy_score, classification_report
from sklearn.model_selection import train_test_split
import ipywidgets as widgets
from IPython.display import display
import joblib
import numpy as np
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
import seaborn as sns
|
Loading dataset and data pre-processing
Python3
iris_df = load_iris()
X = iris_df.data
y = iris_df.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
|
The Iris dataset is loaded, divided into training and testing sets using an 80/20 split, and the feature data is stored in X and the associated target labels are stored in Y. For reproducibility, the random seed is set to 42 and the dataset is taken from the load_iris function.
Exploratory Data Analysis
Before model training it is required to understand the dataset in certain ways.
Feature Distributions
We will first visualize the distributions of individual features present in Iris dataset which are sepal length, sepal width, petal length, petal width. This will help us to understand their characteristics and potential outliers.
Python3
plt.figure(figsize=(12, 6))
for i, feature in enumerate(iris_df.feature_names):
plt.subplot(2, 2, i + 1)
sns.histplot(X_train[:, i], bins=20, kde=True, color='Green')
plt.title(f'Distribution of {feature}')
plt.xlabel(feature)
plt.ylabel('Frequency')
plt.tight_layout()
plt.show()
|
Output:
.jpg)
Feature Distribution of Iris data
This method generates a 2×2 grid of subplots for each of the four features in the Iris dataset, each of which shows a histogram and a KDE plot. It offers a visual depiction of the distribution of each feature, making it easier to comprehend their properties and potential variations.
Distribution of target classes
Now we will see the distribution of target class. It will help to understand the class distribution which is essential for assessing class balance and potential data biases.
Python3
plt.figure(figsize=(8, 4))
sns.countplot(x=y_train)
plt.title('Distribution of Target Classes')
plt.xlabel('Class')
plt.ylabel('Count')
plt.show()
|
Output:
.jpg)
Target classes distribution
This code snippet generates a bar chart that shows the distribution of classes in the y_train target variable and sheds light on the balance or imbalance of the classes in the training dataset.
Correlation Matrix
Visualizing correlation matrix between features will help us understand how they are related to each other and also helpful for feature selection or engineering.
Python3
correlation_matrix = np.corrcoef(X_train, rowvar=False)
plt.figure(figsize=(8, 6))
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', xticklabels=iris_df.feature_names, yticklabels=iris_df.feature_names)
plt.title('Correlation Matrix')
plt.show()
|
Output:
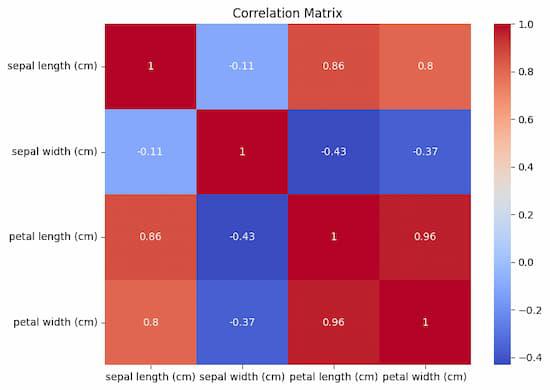
Correlation Matrix
This code creates a heatmap that graphically displays the pairwise correlations between features in the X_train dataset. Insights into the strength and direction of these associations are revealed by the color intensity and annotations.
Model Training and Evaluation
Now we will train the CatBoost model on the training set and then evaluate the model in terms of accuracy score and classification report.
Python3
model = CatBoostClassifier(
iterations=100, depth=6, learning_rate=0.1,
loss_function='MultiClass', verbose=False)
model.fit(X_train, y_train)
|
This program builds and trains a CatBoostClassifier using a set of predetermined hyperparameters, including 100 iterations, a tree depth of 6, a learning rate of 0.1, and a MultiClass loss function. In order to train the model for multiclass classification, the X_train and y_train datasets are used, with verbose output being suppressed (verbose=False).
- iterations: This parameter is used to specify the number of boosting iterations which corresponds to the number of decision trees to be built. It controls the complexity of the model.
- depth: It defines the depth of each decision tree in the ensemble. A higher depth allows the model to capture more complex relationships present in the data. But it may lead to overfitting if it is set too high.
- learning_rate: The learning rate determines the step size for gradient descent during model training. A smaller learning rate can help prevent overfitting but may require more iterations to converge.
- loss_function: For multiclass classification, we will use the ‘MultiClass’ loss function. This is specifically designed for handling multiple classes. It computes the loss for each class separately and aggregates them finally.
- verbose: This parameter controls whether to print training progress in runtime console during model training or not. Setting it to ‘False’ suppresses the progress output and keeps the console clean.
Prediction and Evaluation
Python3
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
report = classification_report(y_test, y_pred)
print(f"Accuracy: {accuracy}")
print("Classification Report:\n", report)
|
Output:
Accuracy: 1.0
Classification Report:
precision recall f1-score support
0 1.00 1.00 1.00 10
1 1.00 1.00 1.00 9
2 1.00 1.00 1.00 11
accuracy 1.00 30
macro avg 1.00 1.00 1.00 30
weighted avg 1.00 1.00 1.00 30
For model evaluation we will consider some well-known metrics which are discussed below:
Accuracy score: this metric measures the fraction of correctly predicted instances out of all instances in the test set. This provides an overall assessment of the model’s performance.
Classification Report: The classification report provides a detailed metrics for each class which includes precision, recall, F1-score(harmonic mean of precision and recall) and support. It helps assess the model’s performance on a per-class basis which can be important in imbalanced datasets or when different classes have their individual significance.
From the output we can see that our CatBoost model has achieved 100% accuracy on Iris Dataset and also other metrics like precision and recall are also 1. So, this model can effectively classify all three species(setosa, versicolor and virginica) of Iris flowers present in the dataset. So, this model can be used for deployment.
Model Deployment
Model saving to runtime
Now, we will save the trained model to use it in our user interface.
Python3
joblib.dump(model, 'catboost_model.pkl')
|
Output:
['catboost_model.pkl']
The trained CatBoost model (model) is saved by this code using joblib.dump to a file named ‘catboost_model.pkl’, making it simple to load and use for future predictions or other tasks. This output ensures that the trained model is successfully saved in you runtime. Now we will be able to load it for our user interface.
The Python function joblib.dump is mostly used for quickly saving Python objects, such as machine learning models, to disk. It is frequently used as a substitute for Python’s built-in pickle module since it is tuned for effectively storing big NumPy arrays. It is especially helpful for machine learning models, which can be intricate and memory-intensive.
User interface creation
Now, let’s create a user interface where user can give inputs Sepal Length, Sepal Width, Petal Length and Petal Width and the model predict the type of Iris flower based on that input.
Python3
model = joblib.load('catboost_model.pkl')
sepal_length = widgets.FloatText(description="Sepal Length:")
sepal_width = widgets.FloatText(description="Sepal Width:")
petal_length = widgets.FloatText(description="Petal Length:")
petal_width = widgets.FloatText(description="Petal Width:")
predict_button = widgets.Button(description="Predict")
def predict_on_click(b):
inputs = np.array([[sepal_length.value, sepal_width.value,
petal_length.value, petal_width.value]])
probabilities = model.predict_proba(inputs)
class_names = ["setosa", "versicolor", "virginica"]
predicted_class_index = np.argmax(probabilities)
predicted_class = class_names[predicted_class_index]
output_label.value = f"Predicted Iris Species: {predicted_class}"
predict_button.on_click(predict_on_click)
display(sepal_length, sepal_width, petal_length, petal_width, predict_button)
output_label = widgets.Label()
display(output_label)
|
Output:
Blank user interface:
Blank user interface
Real-time prediction based on user inputs:
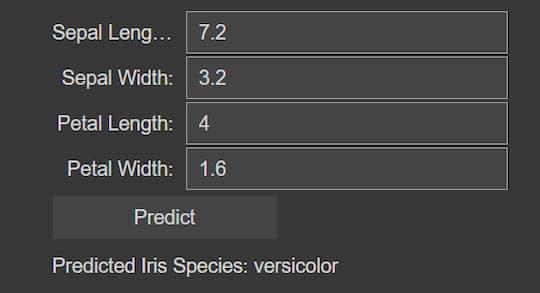
After giving inputs and clinked on Predict button
Here, this code imports a CatBoost machine learning model that has already been trained and incorporates it into a user interface that allows users to predict an iris flower’s species based on measurements. For sepal length, sepal width, petal length, and petal width, the interface has input widgets. When users click the “Predict” button, the code utilizes the loaded model to determine the probabilities of each Iris species based on the numerical numbers they have entered. Next, the user interface shows the projected species. With the help of this integration, users may quickly make predictions by entering measurements of iris flowers and instantly getting classification results using the trained model.
Conclusion
We can conclude that, CatBoost algorithm can be effectively used for multiclass classification problems. Here, we have achieved 100% accuracy on Iris dataset but in other large datasets or real-life problems the accuracy may be degraded. However, CatBoost provides efficient categorical feature support and proof from overfitting. So, this model generally achieves higher accuracy from other traditional machine learning models.
Share your thoughts in the comments
Please Login to comment...