In this article, we will implement Retrieval Augmented Generation aka RAG pipeline using Open-Source Large Language models with Langchain and HuggingFace.

Open Source LLMs vs Closed Source LLMs
Large Language models are all over the place. Because of the rise of Large Language models, AI came into the limelight in the market. From development to the business world, most tasks are now automated thanks to the capability of Large Language Models. One breakthrough in this field was the release of ChatGPT by OpenAI. Large Language Models are autoregressive models trained on large amounts of data and can further perform tasks such as Text Generation, Text Autocompletion, Question and answering, Intelligent Chatbot, Code Generation, Text Summarization and more. Large Language models such as GPT are good, but they also address the issues of Data Privacy.
Large Language models such as ChatGPT that is GPT3.5 and closed source LLMs. By closed Large Languages we mean the model weights are not revealed publicly. This is where APIs are provided and not many enterprises rely on such services. This is where Open Source LLMs are one viable alternative to such concerns. Open-source Source Large Language models are such models whose weights are publicly available, and anyone can use these fine-tuned models on general specific data. Some of the popular open source LLMs are Mixtral, Llama, Falcon, Orca and so on.
HuggingFace – Hub of Open Source LLMs
When it comes down to hosting large number of models, there is no better provider than HuggingFace. HuggingFace has a wide range of open-source models in the Transformers, an open-source repository. Transformers has supported to powerful deep learning framework such as Transformers and PyTorch. HuggingFace provided HuggingFace Hub, a platform with over 120k models, 20k datasets, and 50k spaces (demo AI applications).
With help of HuggingFace Hub we can access and inference large language seamlessly, then brings to us to the large language model framework Langchain, that will do the job to connect different components to build the pipeline.
What is Langchain?
ChatGPT is great and one of the most advanced AI product. ChatGPT can perform various kind of tasks and everyone wants to integrate it as ChatBot in their own product. Consider you have a product and need a powerful chatbot like ChatGPT, but it doesn’t have the access to your data.
What do you do in cash case? How do we achieve this?
This is where Langchain comes to the rescue. Langchain is a powerful Large Language model framework. It provides wide range of components to build a ChatBot like ChatGPT. Few of the important component to build RAG pipeline are: Loaders to load external data, Large language models integration, Vector database, Embedding models support, memory, and so on.
What is Retrieval Augmented Generation?
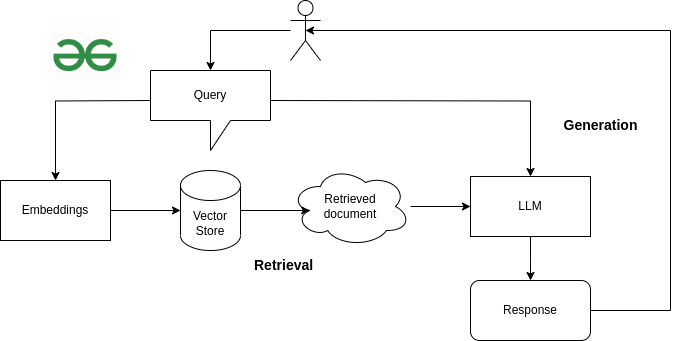
Retrieval augment generation, in short RAG is a mechanism to integrate large language model to a custom data. RAG includes two methods:
- Retriever model
- Generator model
The process includes where a user enters his query. This query is first converted into vector format using embedding model. Based on this input embedding, we look into the existing vector store and retrieve the relevant document/content. This is the process that is involved in retriever model.
In the generator model, we generate a response. During the retriever, we extract the relevant document, this document along with the query is passed to the large language model. Using the LLM intelligence we get a better response to the user query/prompt.
Chatbot to interact with Website Project
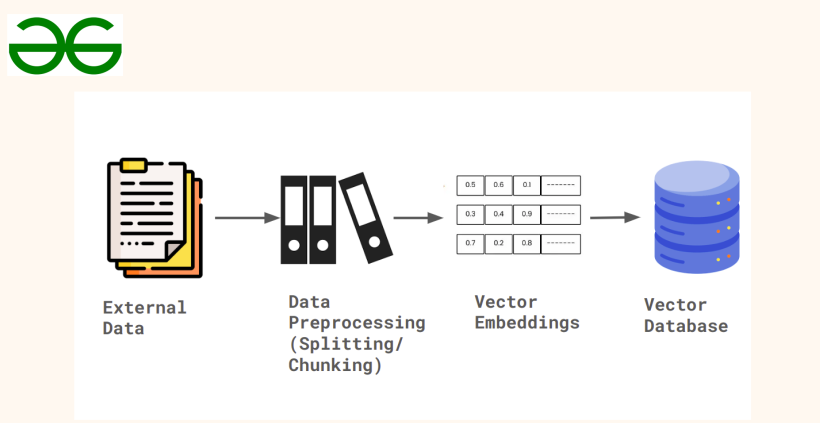
Load the Data
Since in this project our goal is to build a chatbot and interact with website. I picked two of my best articles in Machine learning that is published on GeeksforGeeks.
- Stock Price Prediction project using TensorFlow
- Training of Recurrent Neural Network in TensorFlow
Once we define our data, we use WebBaseLoader from Langchain to load and extract the content.
Python
from langchain.document_loaders import WebBaseLoader
data = WebBaseLoader(URL)
content = data.load()
|
Text Split – Chunking
Chunking is a strategy to reduce the large corpus of data into smaller segment to reduce the complexity and diversity in the large data context. Chunking divides the smaller chunks of data based on the token size.
Python
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=256,chunk_overlap=50)
chunking = text_splitter.split_documents(content)
|
Chunk overlap adds the previous token size chunk information token into the beginning of next chunk.
Embeddings
We can’t pass the text chunk into the language model. In deep learning we provide vector or numeric representation to the model. We can achieve this by converting the text into vector embeddings using the existing open-source embeddings model. Here we will use HuggingFace to load embedding model.
Important step to notice. Since we are using open-source models from HuggingFace using Inference API. We need to get the access token. Access token from HuggingFace is free. Steps to get your access token:
- Sign in to HuggingFace.co.
- Select “Settings” from your profile.
- In the left sidebar, navigate to “Access Token.”
- Create new access token.
We will save the access token in environment variable; this will further be used when we define the LLM.
Python
from langchain.embeddings import HuggingFaceInferenceAPIEmbeddings
import os
from getpass import getpass
HF_token = getpass()
os.environ['HUGGINGFACEHUB_API_TOKEN'] = HF_token
embeddings = HuggingFaceInferenceAPIEmbeddings(
api_key = HF_token,model_name = "BAAI/bge-base-en-v1.5"
)
|
Vector Database
We need a location to save our embeddings to be stored somewhere, this is where we use Vector database. Vector databases are different from traditional database because it performs more than storage. Vector database can perform different kind of search techniques such as semantic search, cosine similarity, keyword search, nearest neighbor and so on. We have various open-source vector database such as: FAISS, Chroma, Milvus, Qdrant and so on. In this case, we will use ChromaDB.
Python
from langchain.vectorstores import Chroma
vectorstore = Chroma.from_documents(chunking,embeddings)
|
Step-1 Retrieval
Based on the above diagram, now let’s retrieve the relevant document based on the user query. Langchain provide various kind of retrievers. In our case we will use vector store only as our database. We can define what kind of search_type we need either similarity or mmr(maximum marginal relevancy). k is search keyword argument that defines how many relevant documents we need to retrieve.
Python
retriever = vectorstore.as_retriever(search_type="mmr",search_kwargs={"k":3})
query = "what is recurrent neural network?"
docs_rel = retriever.get_relevant_documents(query)
print(docs_rel)
|
Output:
[Document(page_content='Recurrent Neural Networks in TensorFlow', metadata={'description': 'A Computer Science portal for geeks. It contains well written, well thought and well explained computer science and programming articles, quizzes and practice/competitive programming/company interview Questions.', 'language': 'en-US', 'source': 'https://www.geeksforgeeks.org/training-of-recurrent-neural-networks-rnn-in-tensorflow/', 'title': 'Training of Recurrent Neural Networks (RNN) in TensorFlow - GeeksforGeeks'}),
Document(page_content='Recurrent Neural Network is different from Convolution Neural Network and Artificial Neural Network. A Neural Network is basically known to be trained to learn deep features to make accurate predictions. Whereas Recurrent Neural Network works in such a', metadata={'description': 'A Computer Science portal for geeks. It contains well written, well thought and well explained computer science and programming articles, quizzes and practice/competitive programming/company interview Questions.', 'language': 'en-US', 'source': 'https://www.geeksforgeeks.org/training-of-recurrent-neural-networks-rnn-in-tensorflow/', 'title': 'Training of Recurrent Neural Networks (RNN) in TensorFlow - GeeksforGeeks'}),
Document(page_content='Now that the data is ready, the next step is building a Simple Recurrent Neural network. Before training with SImpleRNN, the data is passed through the Embedding layer to perform the equal size of Word Vectors.', metadata={'description': 'A Computer Science portal for geeks. It contains well written, well thought and well explained computer science and programming articles, quizzes and practice/competitive programming/company interview Questions.', 'language': 'en-US', 'source': 'https://www.geeksforgeeks.org/training-of-recurrent-neural-networks-rnn-in-tensorflow/', 'title': 'Training of Recurrent Neural Networks (RNN) in TensorFlow - GeeksforGeeks'})]
Step-2 Augment
Each large language model has certain prompt template using which it was trained on. In augment step we pass the user query through a template. In our case since our large language model is Zephyr, we will use the prompt template from Zephyr model.
There are three factors to consider in prompt template:
- System prompt to the model
- User prompt from the user
- Assistant, the response that model needs to generate
Step-3 Generation
Finally let’s generate our response. This is where we introduce our LLM component and create a RetrievalQA chain that connects retriever with LLM. The Large language model that we will use is Zephyr-7B model fine-tuned model from Mistral-7B.
Python
from langchain.llms import HuggingFaceHub
from langchain.chains import RetrievalQA
model = HuggingFaceHub(repo_id="HuggingFaceH4/zephyr-7b-alpha",
model_kwargs={"temperature":0.5,
"max_new_tokens":512,
"max_length":64
})
qa = RetrievalQA.from_chain_type(llm=model,retriever=retriever,chain_type="stuff")
response = qa(prompt)
print(response['result'])
|
Output:
\n\nA recurrent neural network (RNN) is a type of artificial neural network that is designed to process sequential data. Unlike traditional neural networks, which process data in a single pass, RNNs can handle data that has a temporal component, such as speech, handwriting, or video. RNNs are capable of "remembering" input data over time, which allows them to identify patterns and make predictions based on historical data. RNNs are commonly used in applications such as speech recognition, language translation, and sentiment analysis.
Testing of another prompt:
Share your thoughts in the comments
Please Login to comment...