Best Practices For Automation Tester to Avoid Java Memory Leak Issue
Last Updated :
16 Feb, 2023
A memory leak is a type of issue that will not cause any problem unless Java Heap Memory is overflown, but once you start getting this issue during execution, it’s very difficult to find out the root cause of it. So, it’s better to prevent memory leak issues in code from the very beginning. While building a test automation framework using Java, we should be considering many best practices but, in this article, we would be discussing three important best practices that we should keep in mind.
Practice No. 1: Reading Excel Files, Properties Files, and Managing Database Connection
Reading an excel file is very common in a test automation framework, either it could be to store test data, credentials, configuration, etc. Apache POI is the external jar that we mostly use to read an excel file. Let’s see the java code to write an XLSX file where we are trying to set the header of the excel file. We have created objects of XSSFWorkbook class and FileOutputStream class at the very beginning with global scope. The object workbook is then used to initialize with a new XSSFWorkbook instance followed by creating the sheet and row and setting the cell value. Whereas outputStream object is initialized with FileOutputStream class by accepting the excel file path as an argument. Important to notice that once the work is done, both the workbook and outputStream object is closed to avoid any memory leak. Also, note that these objects are even close in the catch section, so that in case any exception occurs in between, the memory leak can be avoided then as well. The same is applied to the Properties file as well.
Java
public static void writeExcelData(String filePath)
throws IOException
{
XSSFWorkbook workbook = null;
FileOutputStream outputStream = null;
try {
workbook = new XSSFWorkbook();
XSSFSheet sheet
= workbook.createSheet("Stock Analysis");
Row row = sheet.createRow(0);
row.createCell(0).setCellValue("Stock Name");
row.createCell(1).setCellValue("Current Index");
row.createCell(2).setCellValue("Today's Change");
row.createCell(3).setCellValue("52 Week High");
row.createCell(4).setCellValue("52 Week Low");
row.createCell(5).setCellValue(
"High Minus Current Index");
row.createCell(6).setCellValue(
"Current Index Minus Low Index");
outputStream = new FileOutputStream(filePath);
workbook.write(outputStream);
workbook.close();
outputStream.close();
}
catch (Exception e) {
System.out.println("Exception occurred : " + e);
if (workbook != null) {
workbook.close();
}
if (outputStream != null) {
outputStream.close();
}
}
}
|
It’s also very common to set up a connection with Database in a test automation framework, either for database testing or to fetch or store data in the database. Let’s take an example to connect to Maria DB. We have globally declared two objects conn and stmt of class Connection and Statement respectively. Note how we have closed the conn and stmt once the work is done. In case of exception, finally block is always executed and we have closed conn and stmt here as well.
Java
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.sql.Statement;
public class Mariadb {
static final String JDBC_DRIVER
= "org.mariadb.jdbc.Driver";
static final String DB_URL
static final String USER = "root";
static final String PASS = "root";
public static void main(String[] args)
{
Connection conn = null;
Statement stmt = null;
try {
Class.forName("org.mariadb.jdbc.Driver");
System.out.println(
"Connecting to a selected database...");
conn = DriverManager.getConnection(
"root");
System.out.println(
"Connected database successfully...");
System.out.println(
"Creating table in given database...");
stmt = conn.createStatement();
String sql
= "INSERT INTO CUSTOMER VALUES('FIRST NAME','SECOND NAME')";
stmt.executeQuery(sql);
stmt.close();
conn.close();
}
catch (SQLException se) {
se.printStackTrace();
}
catch (Exception e) {
e.printStackTrace();
}
finally {
try {
if (stmt != null) {
stmt.close();
conn.close();
}
}
catch (Exception se) {
}
}
}
}
|
One of the easiest approaches is to enable memory leak management in the IDE you are using. For Example, you can do the below setup in Eclipse. If you do so, Eclipse will automatically give you a compilation error in case any memory leak occurs in the code.
Navigate to Window – Preferences – Java – Compiler – Errors/Warnings – Potential Programming Problems – Change the settings of “Resource leak” and “Potential resource leak” to “Error” instead of “Warning”. Click on Apply and Ok. You will notice Eclipse automatically throws a compilation error for the memory leak.
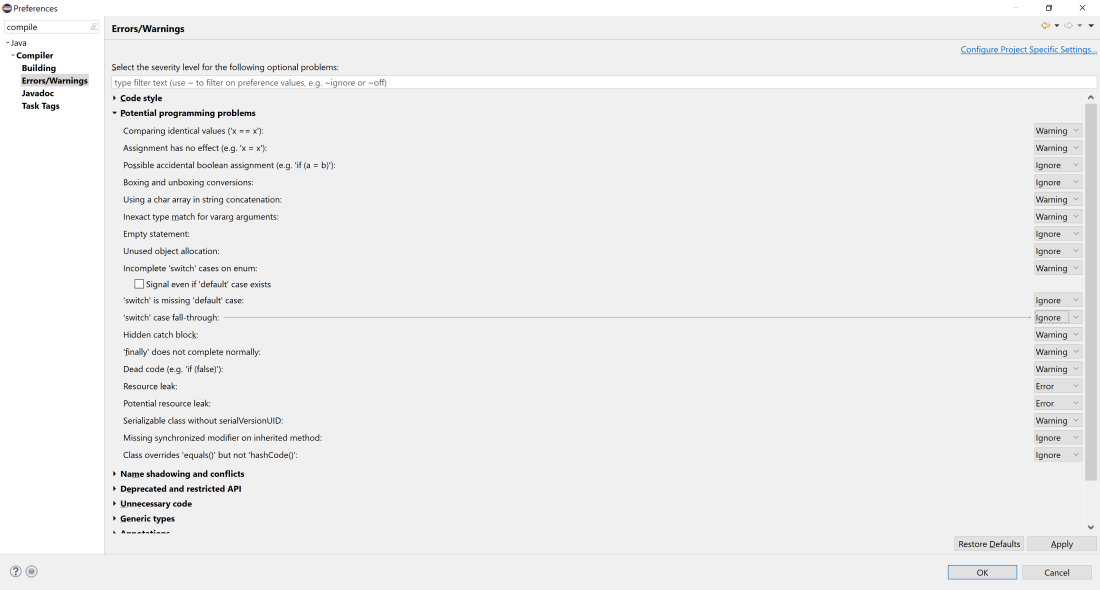
IDE Settings in Eclipse to prevent memory leak
Practice No. 2: Use Singleton Design Pattern
Java provides a variety of design patterns to use in different cases. But we would be talking about Singleton Design Pattern today which can be very useful in a test automation framework. As mentioned earlier, we need to read excel files, and properties files, and establish a database connection, very often in the framework. Let’s assume that we need to read the same excel or properties file in our code but at different places. It’s very inefficient if we create different objects to access the same file at various places in our code.
Using Singleton Design Pattern, we can restrict the creation of an object of a class from outside of the class by making the constructor private. That way the object can be created only from inside the class and it returns the same object whenever called. Hence, Singleton Design Pattern can be used to restrict unnecessary object creation to read various files and establish a database connection in our test automation framework.
Let’s see an example of how to create a Singleton class to establish a Maria DB Connection. In the below example, the constructor MariaDBConnectionSingleton constructor has been made private and within which the code to establish a connection is written. As the constructor is private, it can’t be called from outside of the class. First, we need to call the getInstance() static method to get an object of the class MariaDBConnectionSingleton and then call the getConnection() method using that object to get the conn object. Note that in this way always the same conn object is being returned and no additional Connection object is being created.
Java
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
public class MariaDBConnectionSingleton {
private static MariaDBConnectionSingleton instance;
private Connection conn;
private String userName = "root";
private String password = "root";
private String schemaName = "bdd_framework";
private String mariaDBConnectionString
private MariaDBConnectionSingleton() throws SQLException
{
try {
this.conn = DriverManager.getConnection(
mariaDBConnectionString + "/" + schemaName,
userName, password);
}
catch (Exception ex) {
System.out.println(
"Something is wrong with the DB connection String : "
+ ex.getMessage());
}
}
public Connection getConnection() { return conn; }
public static MariaDBConnectionSingleton getInstance()
throws SQLException
{
if (instance == null) {
instance = new MariaDBConnectionSingleton();
}
else if (instance.getConnection().isClosed()) {
instance = new MariaDBConnectionSingleton();
}
return instance;
}
}
|
Practice No. 3: Initialize the initial capacity of ArrayList and HashMap if Possible
Java Collection is a big world itself but we may not need to discuss everything here. As an automation testers, we use ArrayList and HashMap very often. Let’s discuss ArrayList and HashMap.
ArrayList: ArrayList gives us the flexibility of storing a similar type of data like an Array, the only difference is in Array we can’t dynamically expand the size of the Array if needed whereas in ArrayList the size can be expanded dynamically. But if we understand the internal functioning of ArrayList, we will see that it’s actually backed up by an Array in the background. What happens is, when we declare an ArrayList, in the background, it creates an Array of size 10 (by default size). Java uses a factor called Load Factor (which is by default 0.75), which determines when to grow the initial array (which was of size 10). Total Capacity * Load Factor – which is 10 * 0.75 = 7, that means when the 7th element in the initial Array is inserted, the Array would double its initial capacity, i.e. of size 20.
Now the question is how it increases the capacity. Well in the background Java actually creates another array of size 20 and copies the 7 elements from the initial array, here is when it takes O(n) time where n is the number of elements. We should always try to avoid this O(n) time as it may cause a Java Heap Memory issue. Think about a situation if need to deal with many elements and copy the elements to a new dynamically increased ArrayList again and again.
We can avoid it if we know what would be the maximum size of the ArrayList before ahead and declare the ArrayList with the initial capacity. Let’s take an example, assume that we have a requirement to store all the JSON file names in an ArrayList<String>. Below is the code we should write.
Java
public static List<String>
getJSONFileNames(String folderPath)
{
try {
File folder = new File(folderPath);
File[] listOfFiles = folder.listFiles();
int totalFiles = 0;
if (listOfFiles != null) {
totalFiles = listOfFiles.length;
}
int initialCapacity = (int)(totalFiles / 0.75) + 1;
List<String> jsonFileName
= new ArrayList<>(initialCapacity);
for (File file : listOfFiles) {
if (file.isFile()) {
if (file.getName().trim().endsWith(
"json")) {
jsonFileName.add(folderPath + "\\"
+ file.getName());
}
}
}
return jsonFileName;
}
catch (Exception e) {
return new ArrayList<>();
}
}
|
In the above example, we first got the totalFiles of the folder. Please note that we have used a formula (expected size/load factor) +1 to calculate the initial size of the ArrayList. As explained earlier, Java automatically allocates another array with double the size of the initial size as soon as 75% (Load Factor 0.75) of the array is filled. Hence to avoid it, we should initialize the ArrayList with more than 25% of the total initial capacity (i.e. 15 if the expected initial size is 10).
HashMap: HashMap is another popular Java Collection that we use very often in our test automation framework. The main advantage is its Key-Value pair nature. For example, if we want to read data from a database, we can put the data in a key pair value combination where the key should be the column name. Similarly, reading data from excel and storing it in HashMap where the column name should be a key value.
Likewise, ArrayList and HashMap also have a similar concept of Load Factor and Initial Capacity where 0.75 is the default load factor and 16 is the default initial capacity of a HashMap. In HashMap, first, a hashcode is generated, and accordingly, the element is placed. It’s possible that the same hashcode is being generated for multiple elements, and that is when a collision happens. In such cases, a LinkedList is formed to store the element with which collision occurs. Inserting and retrieving data from HashMap becomes slow if we encounter such collisions. The collision can be avoided if we follow the same rule that was explained in ArrayList, i.e. to declare the initial capacity of HashMap using the formula (expected size/load factor) +1.
Share your thoughts in the comments
Please Login to comment...