Audio Classification using Transformers
Last Updated :
06 Jan, 2024
Our daily life is full of different types of audio. The human brain can effectively classify different audio signals. But what about our machines? They can’t even understand any audio signals by default. Classifying different audio signals is very important for different advanced tasks like speech recognition, music analysis environmental sound monitoring, etc. In this article, we will implement an audio classification technique using the Transformers library.
Why use transformers?
Audio classification is a challenging and complex task that involves several steps like capturing long-range dependencies, variable input sequences, and categorization of audio signals’ invalid classes. All these steps involve several large calculations, which are time- and memory-consuming. Many other methods of audio classification have already been tested, but recent studies showed that the Transformers module can effectively handle all the complex steps associated with classification tasks. The essence of using transformers in audio classification lies in their ability to capture intricate patterns, dependencies and temporal relationships within audio data. Unlike traditional methods (like RNNs), which often struggle to represent the rich and complex structures of audio signals, transformers can process the entire input sequence simultaneously, making them more efficient in handling temporal relationships in audio data.
Audio Classification using Transformers
Installing required modules
Before starting implementation, we need to install some required Python modules to our runtime.
!pip install transformers
!pip install datasets
!pip install evaluate
!pip install accelerate
Importing required modules
Now we will import all required Python modules like NumPy, transformers and Evaluate etc.
Python3
from datasets import load_dataset, Audio
from transformers import AutoFeatureExtractor, AutoModelForAudioClassification, TrainingArguments, Trainer, pipeline
import evaluate
import numpy as np
|
Dataset loading
Now we will load minds dataset which is specially used to audio classification model training. After that we will split it into training and testing sets in 80:20 ratio. Also, we will remove all useless columns like “english_transcription”, “transcription”, “lang_id”, “path” and only keep the audio and intent_class columns with a fixed sampling rate of 16000 (general sampling rate of model input) for all audio files. We also transform the intent_class colomn to labels for model input.
Python3
minds = load_dataset("PolyAI/minds14", name="en-US", split="train")
minds = minds.train_test_split(test_size=0.2)
minds = minds.remove_columns(["transcription", "english_transcription", "lang_id", "path"])
labels = minds["train"].features["intent_class"].names
label2id, id2label = dict(), dict()
for i, label in enumerate(labels):
label2id[label] = str(i)
id2label[str(i)] = label
minds = minds.cast_column("audio", Audio(sampling_rate=16_000))
|
Data pre-processing
Now we will define a small function to map the dataset in batches. This function will map all the input tensor values for audios in array format with their corresponding labels to feed the model. Also, we will define a feature extractor for further use.
Python3
def preprocess_function(examples):
audio_arrays = [x["array"] for x in examples["audio"]]
inputs = feature_extractor(
audio_arrays,
sampling_rate=feature_extractor.sampling_rate,
max_length=16000, truncation=True
)
return inputs
encoded_minds = minds.map(
preprocess_function, remove_columns="audio", batched=True)
encoded_minds = encoded_minds.rename_column("intent_class", "label")
feature_extractor = AutoFeatureExtractor.from_pretrained(
"facebook/wav2vec2-base")
|
Evaluation metrics
We will evaluate our model in the terms of accuracy. Here we haven’t normalized the metric calculation so the output will come in the fraction of 1000.
Python3
accuracy = evaluate.load("accuracy")
def compute_metrics(eval_pred):
predictions = np.argmax(eval_pred.predictions, axis=1)
return accuracy.compute(predictions=predictions, references=eval_pred.label_ids)
|
Model training
Now we are all set to feed the dataset into model for training. We will here finetune a pretrained model and evaluate in the terms of accuracy. The model will be finetuned based on various hyper-parameter configurations. The configurations are set for low standard machine purpose. If you have better resources then increase the values of hyper-parameters.
Python3
num_labels = len(id2label)
model = AutoModelForAudioClassification.from_pretrained(
"facebook/wav2vec2-base", num_labels=num_labels,
label2id=label2id, id2label=id2label
)
training_args = TrainingArguments(
output_dir="GFG_audio_classification_finetuned",
evaluation_strategy="epoch",
save_strategy="epoch",
learning_rate=4e-4,
per_device_train_batch_size=32,
gradient_accumulation_steps=4,
per_device_eval_batch_size=32,
num_train_epochs=8,
warmup_ratio=0.1,
logging_steps=10,
load_best_model_at_end=True,
metric_for_best_model="accuracy",
fp16=True,
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=encoded_minds["train"],
eval_dataset=encoded_minds["test"],
tokenizer=feature_extractor,
compute_metrics=compute_metrics,
)
trainer.train()
|
Output:
Epoch Training Loss Validation Loss Accuracy
0 No log 2.644220 0.070796
1 No log 2.661660 0.088496
2 2.641600 2.681606 0.053097
4 2.641600 2.684303 0.061947
5 2.635000 2.679394 0.061947
6 2.635000 2.676991 0.061947
TrainOutput(global_step=24, training_loss=2.6381918589274087, metrics={'train_runtime': 127.9908, 'train_samples_per_second': 28.127, 'train_steps_per_second': 0.188, 'total_flos': 2.6256261811968e+16, 'train_loss': 2.6381918589274087, 'epoch': 6.4})
So, the best accuracy(as previously told that the value will come in fraction of 1000) we have got is 88% and the training stopped at epoch 6 as no improvement is there.
Pipeline for model testing
Now we will pass a sample audio file to the model checkpoint. Remember that, we will get a below structure after fine0tuning completed. We need to copy the path of best checkpoint (it is checkpoint 7 here as we got highest accuracy in 2nd checkpoint) for model testing.
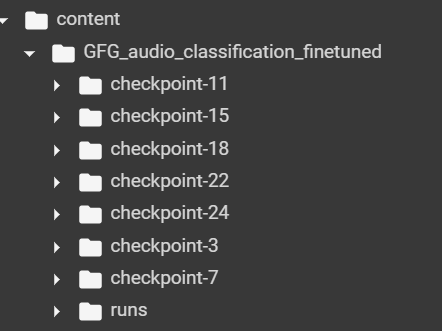
Model finetuning checkpoints
From the above structure we can see that 1st to last checkpoint values are 3, 7, 11, 15, 18, 22, 24. So, we got 88% accuracy at checkpoint 7. So, we will use it for model testing.
Python3
audio_file='/content/audiotesting.wav'
classifier = pipeline("audio-classification", model="/content/GFG_audio_classification_finetuned/checkpoint-7")
classifier(audio_file)
|
Output:
[{'score': 0.0973217785358429, 'label': 'cash_deposit'},
{'score': 0.08817893266677856, 'label': 'freeze'},
{'score': 0.08222776651382446, 'label': 'atm_limit'},
{'score': 0.07961107790470123, 'label': 'card_issues'},
{'score': 0.0780879408121109, 'label': 'address'}]
So, the cash_deposit is correctly labeled with highest score.
Conclusion
We can conclude that audio classification is a very important task for real-world applications, and this can be easily done using transformers library.
Share your thoughts in the comments
Please Login to comment...