Agglomerative clustering is a hierarchical clustering algorithm that is used to group similar data points into clusters. It is a bottom-up approach that starts by treating each data point as a single cluster and then merges the closest pair of clusters until all the data points are grouped into a single cluster or a pre-defined number of clusters.
In this blog, we will discuss how to perform agglomerative clustering in Scikit-Learn, a popular machine-learning library for Python. We will also discuss the differences between agglomerative clustering with and without structure.
Before diving into the details of agglomerative clustering in Scikit-Learn, let’s first understand the basics of hierarchical clustering and how it works.
What is Hierarchical Clustering?
Hierarchical clustering is a type of clustering algorithm that is used to group similar data points into clusters. It is a bottom-up approach that starts by treating each data point as a single cluster and then merges the closest pair of clusters until all the data points are grouped into a single cluster or a pre-defined number of clusters.
Hierarchical clustering can be divided into two types:
- Agglomerative Clustering
- Divisive Clustering
Agglomerative clustering is a bottom-up approach that starts by treating each data point as a single cluster and then merges the closest pair of clusters until all the data points are grouped into a single cluster or a pre-defined number of clusters. Divisive clustering is a top-down approach that starts by treating all the data points as a single cluster and then splits the cluster into smaller clusters until each cluster contains only one data point.
How does Hierarchical Clustering work?
The hierarchical clustering algorithm is an iterative algorithm that starts by treating each data point as a single cluster. In each iteration, the algorithm identifies the pair of clusters that are closest to each other and then merges them into a single cluster. This process continues until all the data points are grouped into a single cluster or a pre-defined number of clusters.
The algorithm uses a distance metric to measure the similarity between the data points and to determine the closest pair of clusters. Some common distance metrics used in hierarchical clustering are Euclidean distance, Manhattan distance, and cosine similarity.
Once all the data points are grouped into clusters, the algorithm creates a dendrogram that shows the hierarchical structure of the clusters. A dendrogram is a tree-like diagram that shows the sequence of cluster merges and the distance at which the clusters are merged.
How to perform hierarchical clustering in Scikit-Learn?
Scikit-Learn is a popular machine-learning library for Python that provides a wide range of clustering algorithms, including hierarchical clustering. In this section, we will discuss how to perform hierarchical clustering in Scikit-Learn using the AgglomerativeClustering class.
To perform hierarchical clustering in Scikit-Learn, we first need to import the AgglomerativeClustering class from the sklearn.cluster module. Here is the code to import the AgglomerativeClustering class:
Python3
from sklearn.cluster import AgglomerativeClustering
|
Once we have imported the AgglomerativeClustering class, we can create an instance of the class by specifying the number of clusters and the distance metric that we want to use. The AgglomerativeClustering class provides several distance metrics that we can use to measure the similarity between the data points, such as euclidean, manhattan, and cosine.
Here is the code to create an instance of the AgglomerativeClustering class:
Python3
clustering = AgglomerativeClustering(n_clusters=3,
affinity="euclidean")
|
Once we have created an instance of the AgglomerativeClustering class, we can fit the model to the data by calling the fit() method of the clustering object. The fit() method takes the data as an input parameter and returns the cluster labels for each data point.
Here is the code to fit the hierarchical clustering model to the data:
Once the model is fitted to the data, we can use the labels_ attribute of the clustering object to get the cluster labels for each data point. The labels_ attribute returns an array of integers that represent the cluster labels for each data point.
Here is the code to get the cluster labels for each data point:
Python3
labels = clustering.labels_
|
Agglomerative clustering with and without structure
The AgglomerativeClustering class in Scikit-Learn provides two algorithms for hierarchical clustering: ward and complete. The ward algorithm is an agglomerative clustering algorithm that uses Ward’s method to merge the clusters. Ward’s method is a variance-based method that aims to minimize the total within-cluster variance.
The complete algorithm is an agglomerative clustering algorithm that uses the maximum or complete linkage method to merge the clusters. The maximum or complete linkage method is a distance-based method that measures the distance between the farthest points in the clusters.
The ward algorithm is useful when the data points have a clear structure, such as when the data points form clusters with a circular or spherical shape. The complete algorithm is useful when the data points do not have a clear structure and the clusters are more elongated or irregular in shape. Here is an example to illustrate the differences between the ward and complete algorithms.
Python3
from sklearn.datasets import make_circles
from sklearn.cluster import AgglomerativeClustering
data, _ = make_circles(n_samples=1000,
noise=0.05,
random_state=0)
|
Next, we can use the AgglomerativeClustering class to perform hierarchical clustering on the data using the ward and complete algorithms. We can create two instances of the AgglomerativeClustering class, one for the ward algorithm and the other for the complete algorithm. Here is the code to perform hierarchical clustering on the data using the ward and complete algorithms:
Python3
ward = AgglomerativeClustering(n_clusters=2,
affinity="euclidean",
linkage="ward")
ward.fit(data)
complete = AgglomerativeClustering(n_clusters=2,
affinity="euclidean",
linkage="complete")
complete.fit(data)
|
Once the ward and complete algorithms are fitted to the data, we can use the labels_ attribute of the ward and complete objects to get the cluster labels for each data point. Here is the code to get the cluster labels for each data point using the ward and complete algorithms:
Python3
ward_labels = ward.labels_
complete_labels = complete.labels_
|
We can then plot the data points and the cluster labels to visualize the results of the ward and complete algorithms. Here is the code to plot the data points and the cluster labels using the ward and complete algorithms:
Python3
import matplotlib.pyplot as plt
plt.scatter(data[:, 0], data[:, 1],
c=ward_labels, cmap="Paired")
plt.title("Ward")
plt.show()
plt.scatter(data[:, 0], data[:, 1],
c=complete_labels, cmap="Paired")
plt.title("Complete")
plt.show()
|
Output:
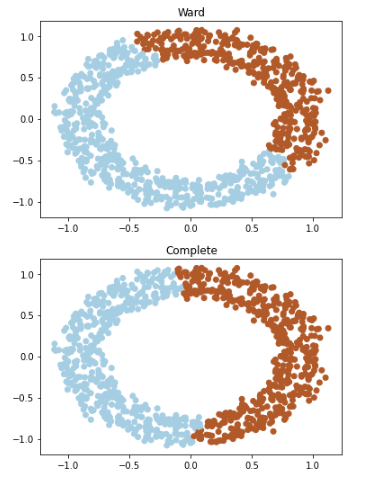
Clusters formed by using Agglomerative Clustering
The plot generated by the ward algorithm shows that the algorithm has successfully identified the circular clusters in the data. The plot generated by the complete algorithm shows that the algorithm has not been able to identify the circular clusters and instead has grouped the data points into two elongated clusters.
This example shows the differences between the ward and complete algorithms for agglomerative clustering. The ward algorithm is better suited for data with a clear structure, such as circular or spherical clusters, whereas the complete algorithm is better suited for data without a clear structure, such as elongated or irregular clusters.
In summary, hierarchical clustering is a type of clustering algorithm that is used to group similar data points into clusters. It is a bottom-up approach that starts by treating each data point as a single cluster and then merges the closest pair of clusters until all the data points are grouped into a single cluster or a pre-defined number of clusters.
Scikit-Learn is a popular machine-learning library for Python that provides a wide range of clustering algorithms, including hierarchical clustering. The AgglomerativeClustering class in Scikit-Learn provides two algorithms for hierarchical clustering: ward and complete. The ward algorithm is an agglomerative clustering algorithm that uses Ward’s method to merge the clusters and is useful for data with a clear structure. The complete algorithm is an agglomerative clustering algorithm that uses the maximum or complete linkage method to merge the clusters and is useful for data without a clear structure.
Differences between hierarchical clustering with and without structure
Hierarchical clustering can be performed with or without structure. In hierarchical clustering without structure, the algorithm treats all the data points as independent, and the distance between the data points is computed using a distance metric. In hierarchical clustering with structure, the algorithm considers the structure of the data and uses the connectivity matrix to determine the distance between the data points.
There are several differences between hierarchical clustering with and without structure:
- In hierarchical clustering without structure, the distance between the data points is computed using a distance metric. In hierarchical clustering with structure, the distance between the data points is determined by the connectivity matrix.
- In hierarchical clustering without structure, the clusters are formed based on the distance between the data points. In hierarchical clustering with structure, the clusters are formed based on the connectivity between the data points.
- In hierarchical clustering without structure, the algorithm may not produce optimal results for data with a non-linear structure. In hierarchical clustering with structure, the algorithm can produce more accurate results for data with a non-linear structure.
- In hierarchical clustering without structure, the algorithm may produce clusters with uneven sizes. In hierarchical clustering with structure, the algorithm can produce clusters with more uniform sizes.
Conclusion
In this blog, we have discussed hierarchical clustering and how to perform agglomerative clustering in Scikit-Learn. We have also discussed the differences between hierarchical clustering with and without structure.
Hierarchical clustering is a powerful clustering algorithm that is widely used in machine learning and data mining. It is a bottom-up approach that starts by treating each data point as a single cluster and then merges the closest pair of clusters until all the data points are grouped into a single cluster or a pre-defined number of clusters.
Scikit-Learn is a popular machine-learning library for Python that provides a wide range of clustering algorithms, including hierarchical clustering. The AgglomerativeClustering class in Scikit-Learn allows us to perform hierarchical clustering with or without structure.
Hierarchical clustering with structure can produce more accurate results for data with non-linear structures and can produce clusters with more uniform sizes. It is important to understand the differences between hierarchical clustering with and without structure and choose the appropriate approach based on the characteristics of the data.
Share your thoughts in the comments
Please Login to comment...