YOLO9000 Architecture – Faster, Stronger
Last Updated :
06 Dec, 2022
YOLO v2 and YOLO 9000 was proposed by J. Redmon and A. Farhadi in 2016 in the paper titled YOLO 9000: Better, Faster, Stronger. At 67 FPS, YOLOv2 gives mAP of 76.8% and at 67 FPS it gives an mAP of 78.6% on VOC 2007 dataset bettered the models like Faster R-CNN and SSD. YOLO 9000 used YOLO v2 architecture but was able to detect more than 9000 classes. YOLO 9000, however, has an mAP of 19.7% mAP with 16% mAP on those classes 156 classes which are not in COCO. However, YOLO can predict more than 9000 classes.
Architecture:

Darknet-19 architecture
The architecture of YOLO9000 is very similar to the architecture of YOLOv2. It also uses Darknet-19 architecture as its Deep Neural Network (DNN) architecture. However, the main difference between their classification architecture. Let’s look at the YOLO 9000 classification architecture below:
Classification Task:
The object detection dataset (COCO: 80 classes) has a lot fewer classes than classification (ImageNet: 22k classes). To expand the classes that YOLO can detect. The paper proposes a method to merge the classification and detection tasks with detection. It trains with the end-to-end network while backpropagating the classification loss. However, The issue with the simple merging of all the classes of the detection and classification are not simply mutually exclusive. For example in COCO datasets class labels are general classes like Cat, Dog, etc. but in Imagenet there are specific classes (For Example for Dog we have classes Norfolk terrier”, “Yorkshire terrier”, or “Bedlington terrier”). We could not have also different softmax classes for “Dog” and “Norfolk terrier” because they are not mutually exclusive.
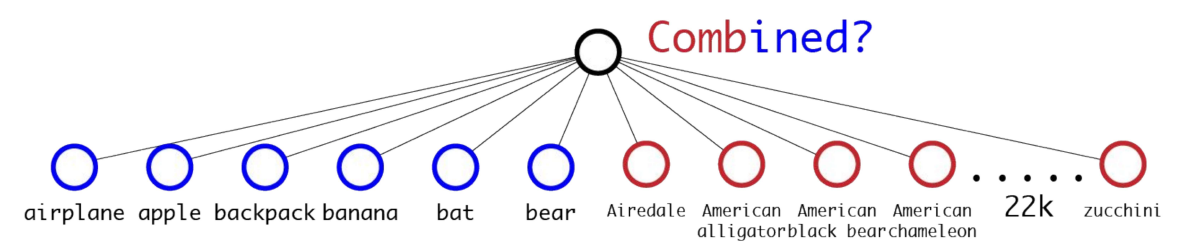
We cannot combine directly because the classes are not mutually exclusive
Hierarchical Classification:
YOLO9000 proposed a method called Hierarchical Classification. In this method. they proposed a hierarchical tree-based structure to represent classes with their subclasses when we make the classification. For Example, Norfolk Terrier comes under the “terrier” which in turn comes under “dog” class. This structure is inspired by WordNet. But, Instead of using the graphical structure it just uses the hierarchical tree structure based on the concept of image collections in the Imagenet dataset). This hierarchical structure is called WordTree.

WordTree Example
For performing classification, this WordTree uses conditional probability on every node level. To calculate the conditional probability of leaf node (specific class) we need to multiply the conditional probability of all its parent. This architecture defines “Physical object” as its root node considers that Pr(Physical Object) =1.
For Example, The conditional probability for different types of terrier can be calculated as:

Now, We can obtain absolute probability that the object belongs to “Norfolk Terrier” class.

Here, the paper uses ImageNet-1000 as an example to perform the experiment. Instead of creating a 1000-layers flat structure, we create a WordTree like hierarchical tree structure with 1000 leaf nodes and 369 parent nodes.

Simple 1k Imagenet vs WordTree
Using the same training parameters as in YOLOv2, this hierarchical Darknet-19 on Imagenet achieves 71.9% top-1 accuracy and 90.4% top-5 accuracy. The advantage of hierarchical classification when this model cannot distinguish between leaf classes, it gives high probability to the parent class.
Training:
The model combines the COCO classes with top-9000 class labels of Imagenet using WordTree method to get a 9418 nodes WordTree. So, the corresponding WordTree has 9418 classes. Imagenet is a much bigger dataset than COCO. To balance the dataset we oversample COCO such that the ratio between Imagenet and COCO sample is 4:1.
We train the model using the YOLOv2 dataset but we use only 3 anchor boxes instead of 5. When this network inputs a detection image this backpropagates the detection loss as normal but for classification loss, it backpropagates the loss at or above the corresponding level of the label.
Results and Conclusion:
YOLO9000 has an overall mAP of 19.7% with 16% mAPon the classes that are not present in the detection dataset. It also performs better on new species of animals that are not present in the COCO dataset. The mAP is higher than the mAP that is resulted in the DPM model.
The main advantage of YOLO9000 is that it is able to predict more than 9000 classes (9418 to be precise) that is in real-time.

YOLO 9000 Results
Because of its large number of class predicting ability. It is one of the most widely used object recognition architecture from medical imaging to drone surveillance, manufacturing industry, etc.
Reference:
Share your thoughts in the comments
Please Login to comment...