U-Net++ or Nested U-Net is a deep learning architecture that was introduced in 2019 in the “UNet++. In UNet, the encoder part captures high-level features from the input image through a series of convolutional and pooling layers, while the decoder part upsamples these features to generate a dense segmentation map. However, there can be a semantic gap between the encoder and decoder features, meaning that the decoder may struggle to reconstruct fine-grained details and produce accurate segmentation.
UNet++ introduces the concept of nested skip pathways to bridge this semantic gap. It adds additional skip connections between the encoder and decoder blocks at multiple resolutions. These connections allow the decoder to access and incorporate both low-level and high-level features from the encoder, providing a more detailed and comprehensive understanding of the image. A Nested U-Net Architecture for Medical Image Segmentation” paper. They improved the traditional U-Net architecture by redesigning the skip connections and introducing a deeply supervised nested encoder-decoder network. This article discusses the U-Net++ architecture and also covers its implementation in Python using the TensorFlow library.
U-Net++ Architecture
U-Net++ architecture is a semantic segmentation architecture based on U-Net. They introduced two main innovations in the traditional U-Net, architecture namely, nested dense skip connections and deep supervision. In their research, they found that using nested dense skip connections bridges the semantic gap between encoder and decoder feature maps and improves the gradient flow. They also found that using deep supervision enhances the model performance by providing a regularization to the network while training.
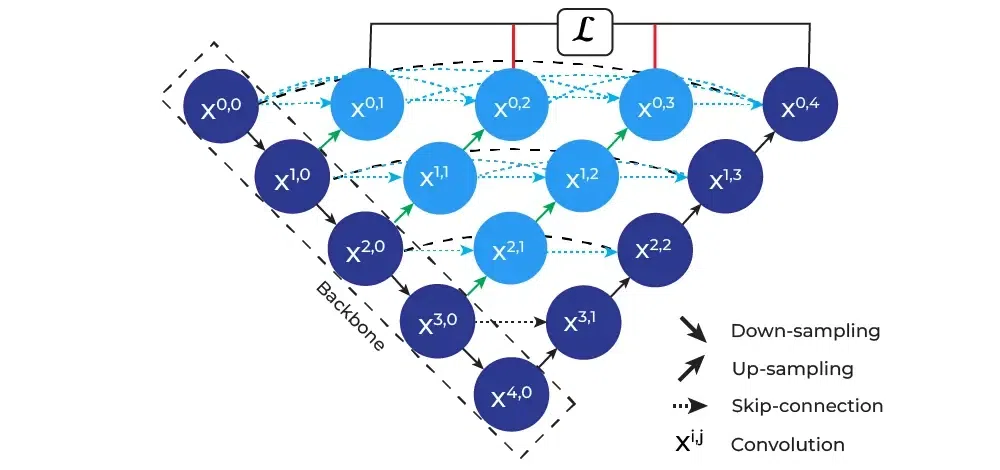
The above figure illustrates the architecture design of U-Net++. The figure illustrates the nested encoder and decoder architecture of the U-Net++ architecture. We can notice that instead of a traditional skip connection, the feature map from the lower level is also convoluted with the upper-level feature and then the new combined feature data is then passed further. The basic idea behind UNet++ is to bridge the semantic gap between the feature maps of the encoder and decoder before the fusion. For example, the semantic gap between (X0,0, X2,2) is bridged using a dense convolution block with three convolution layers.
In the above figure, the black dotted skip connection indicated the original skip connection present in U-Net architecture while the blue dotted skip connection indicated the newly introduced nested skip connection. It must be noted that before convoluting the lower level feature map it is upscaled to match the number of channels in that level. The figure also illustrated how deep supervision is also applied to the output of nodes X0,1, X0,2, X0,3, and X0,4 to improve the model learning while training. Deep supervision is an optimization technique where you optimize the model on the final as well as hidden layers (or nodes) in the model. This helps the model to generalize the problem in a better way. In U-Net++ architecture, they optimized the model on the output of X0,1, X0,2, X0,3, and X0,4 nodes by calculating the combined loss on the expected output based on the output of each of these nodes.
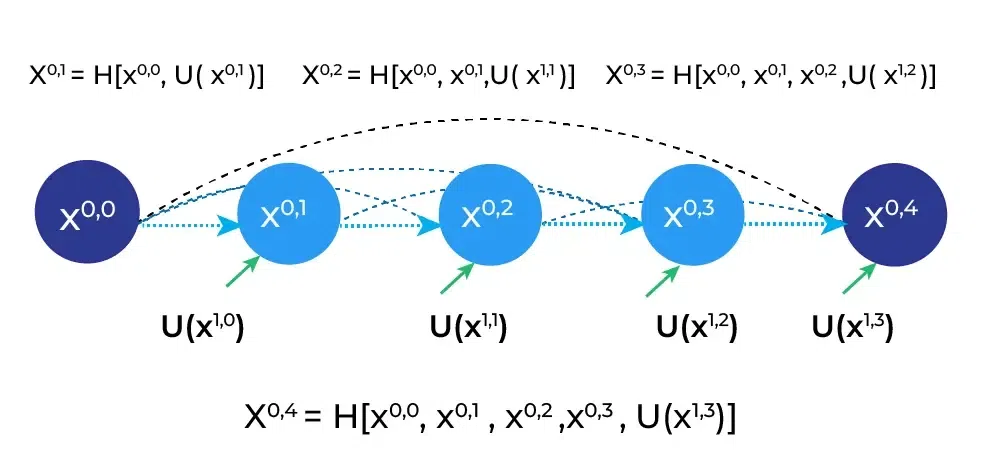
The figure provides a detailed analysis of the first skip pathway of UNet++ and below diagram illustrates how the U-Net++ model can be pruned at inference time if it is trained with deep supervision. The design of U-Net++ L1, U-Net++ L2, U-Net++ L3, and U-Net++ L4 illustrates the U-Net++ design with depth 1, 2, 3, and 4 respectively. These models are used to identify the effectiveness of the model by comparing its performance and inference time over the number of parameters in the model. In their experiments, they found that U-Net++ L3 achieves on average 32.2% reduction in inference time while degrading IoU by only 0.6 points.
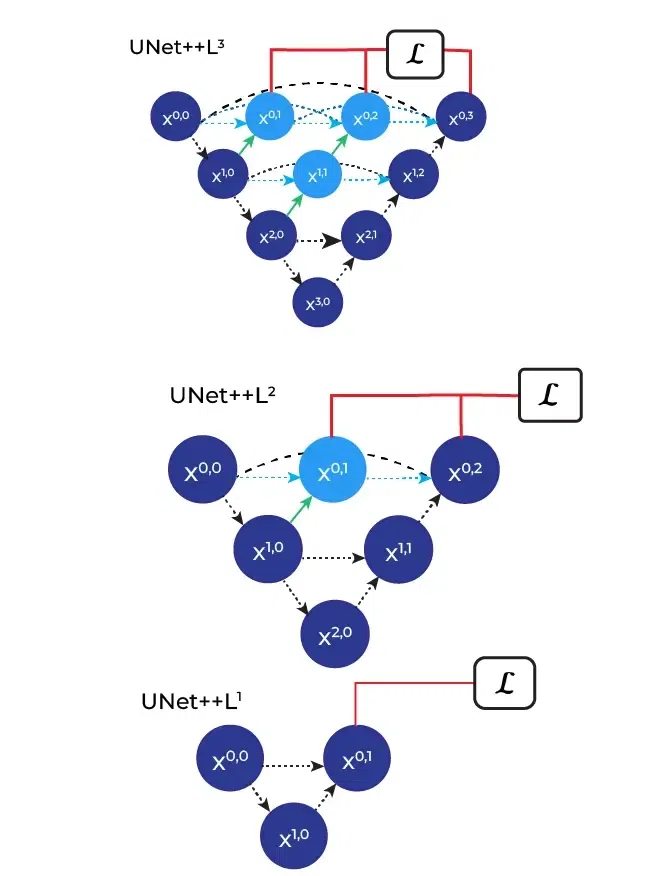
U-Net Vs U-Net++:
U-Net++ was proposed with improvements over U-Net architecture. Some of these improvements are as follows:
- Nested Skip Connections: U-Net++ architecture uses a nested skip connection network to aggregate the features while decoding the encoded data. By aggregating these features from different paths in the network, the model is able to improve the accuracy of the segmentation mask.
- Deep Supervision: U-Net++ architecture uses deep supervision to enhance the model performance by providing a regularization to the network while training.
Build the Model:
Next, we will implement the U-Net++ architecture using Python 3 and the TensorFlow library. The implementation can be divided into two parts. First, we will define our convolution block (Xi,j) and then we will define the U-Net++ model using this block. Now let us import the useful libraries.
Encoder and Decoder Block
The encoder and decoder block of U-Net++ architecture follows the same design and the only difference between these blocks is the number of input channels. The encoder takes input from only one block while the decoder takes one or more than one block. In this article, we are defining a simple convolution block for convolution at each layer which will be used for both encoding and decoding task. This block can be replaced with a VGG Block, ResNet Block or any other convolution block.
Python3
def conv_block(inputs, num_filters):
x = tf.keras.Sequential([
tf.keras.layers.Conv2D(num_filters, 3, padding='same'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu'),
tf.keras.layers.Conv2D(num_filters, 3, padding='same'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu')
])(inputs)
return x
|
U-Net++ Architecture
Now, using the convolution block we will be defining the U-Net++ model and printing the model summary. In defining the architecture we must note that while encoding we will only take the input from the previous encoder but while decoding we will take input from the encoder and decoder at the same level as well as from the decoder at the lower level. While taking input from the lower level decoder, we will upscale the output so that it could match the number of channels in the upper level.
Python3
def unet_plus_plus_model(input_shape=(256, 256, 3), num_classes=1, deep_supervision=True):
inputs = tf.keras.layers.Input(shape=input_shape)
x_00 = conv_block(inputs, 64)
x_10 = conv_block(tf.keras.layers.MaxPooling2D()(x_00), 128)
x_20 = conv_block(tf.keras.layers.MaxPooling2D()(x_10), 256)
x_30 = conv_block(tf.keras.layers.MaxPooling2D()(x_20), 512)
x_40 = conv_block(tf.keras.layers.MaxPooling2D()(x_30), 1024)
x_01 = conv_block(tf.keras.layers.concatenate(
[x_00, tf.keras.layers.UpSampling2D()(x_10)]), 64)
x_11 = conv_block(tf.keras.layers.concatenate(
[x_10, tf.keras.layers.UpSampling2D()(x_20)]), 128)
x_21 = conv_block(tf.keras.layers.concatenate(
[x_20, tf.keras.layers.UpSampling2D()(x_30)]), 256)
x_31 = conv_block(tf.keras.layers.concatenate(
[x_30, tf.keras.layers.UpSampling2D()(x_40)]), 512)
x_02 = conv_block(tf.keras.layers.concatenate(
[x_00, x_01, tf.keras.layers.UpSampling2D()(x_11)]), 64)
x_12 = conv_block(tf.keras.layers.concatenate(
[x_10, x_11, tf.keras.layers.UpSampling2D()(x_21)]), 128)
x_22 = conv_block(tf.keras.layers.concatenate(
[x_20, x_21, tf.keras.layers.UpSampling2D()(x_31)]), 256)
x_03 = conv_block(tf.keras.layers.concatenate(
[x_00, x_01, x_02, tf.keras.layers.UpSampling2D()(x_12)]), 64)
x_13 = conv_block(tf.keras.layers.concatenate(
[x_10, x_11, x_12, tf.keras.layers.UpSampling2D()(x_22)]), 128)
x_04 = conv_block(tf.keras.layers.concatenate(
[x_00, x_01, x_02, x_03, tf.keras.layers.UpSampling2D()(x_13)]), 64)
if deep_supervision:
outputs = [
tf.keras.layers.Conv2D(num_classes, 1)(x_01),
tf.keras.layers.Conv2D(num_classes, 1)(x_02),
tf.keras.layers.Conv2D(num_classes, 1)(x_03),
tf.keras.layers.Conv2D(num_classes, 1)(x_04)
]
outputs = tf.keras.layers.concatenate(outputs, axis=0)
else:
outputs = tf.keras.layers.Conv2D(num_classes, 1)(x_04)
model = tf.keras.Model(
inputs=inputs, outputs=outputs, name='Unet_plus_plus')
return model
if __name__ == "__main__":
model = unet_plus_plus_model(input_shape=(
512, 512, 3), num_classes=2, deep_supervision=True)
model.summary()
|
Output:
Model: "Unet_plus_plus"
_______________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
===============================================================================================
input_2 (InputLayer) [(None, 512, 512, 3 0 []
)]
sequential_15 (Sequential) (None, 512, 512, 64 39232 ['input_2[0][0]']
)
max_pooling2d_4 (MaxPooling2D) (None, 256, 256, 64 0 ['sequential_15[0][0]']
)
sequential_16 (Sequential) (None, 256, 256, 12 222464 ['max_pooling2d_4[0][0]']
8)
max_pooling2d_5 (MaxPooling2D) (None, 128, 128, 12 0 ['sequential_16[0][0]']
8)
sequential_17 (Sequential) (None, 128, 128, 25 887296 ['max_pooling2d_5[0][0]']
6)
max_pooling2d_6 (MaxPooling2D) (None, 64, 64, 256) 0 ['sequential_17[0][0]']
sequential_18 (Sequential) (None, 64, 64, 512) 3544064 ['max_pooling2d_6[0][0]']
max_pooling2d_7 (MaxPooling2D) (None, 32, 32, 512) 0 ['sequential_18[0][0]']
sequential_19 (Sequential) (None, 32, 32, 1024 14166016 ['max_pooling2d_7[0][0]']
)
up_sampling2d_13 (UpSampling2D (None, 64, 64, 1024 0 ['sequential_19[0][0]']
) )
up_sampling2d_12 (UpSampling2D (None, 128, 128, 51 0 ['sequential_18[0][0]']
) 2)
concatenate_14 (Concatenate) (None, 64, 64, 1536 0 ['sequential_18[0][0]',
) 'up_sampling2d_13[0][0]']
up_sampling2d_11 (UpSampling2D (None, 256, 256, 25 0 ['sequential_17[0][0]']
) 6)
concatenate_13 (Concatenate) (None, 128, 128, 76 0 ['sequential_17[0][0]',
8) 'up_sampling2d_12[0][0]']
sequential_23 (Sequential) (None, 64, 64, 512) 9442304 ['concatenate_14[0][0]']
up_sampling2d_10 (UpSampling2D (None, 512, 512, 12 0 ['sequential_16[0][0]']
) 8)
concatenate_12 (Concatenate) (None, 256, 256, 38 0 ['sequential_16[0][0]',
4) 'up_sampling2d_11[0][0]']
sequential_22 (Sequential) (None, 128, 128, 25 2361856 ['concatenate_13[0][0]']
6)
up_sampling2d_16 (UpSampling2D (None, 128, 128, 51 0 ['sequential_23[0][0]']
) 2)
concatenate_11 (Concatenate) (None, 512, 512, 19 0 ['sequential_15[0][0]',
2) 'up_sampling2d_10[0][0]']
sequential_21 (Sequential) (None, 256, 256, 12 591104 ['concatenate_12[0][0]']
8)
up_sampling2d_15 (UpSampling2D (None, 256, 256, 25 0 ['sequential_22[0][0]']
) 6)
concatenate_17 (Concatenate) (None, 128, 128, 10 0 ['sequential_17[0][0]',
24) 'sequential_22[0][0]',
'up_sampling2d_16[0][0]']
sequential_20 (Sequential) (None, 512, 512, 64 148096 ['concatenate_11[0][0]']
)
up_sampling2d_14 (UpSampling2D (None, 512, 512, 12 0 ['sequential_21[0][0]']
) 8)
concatenate_16 (Concatenate) (None, 256, 256, 51 0 ['sequential_16[0][0]',
2) 'sequential_21[0][0]',
'up_sampling2d_15[0][0]']
sequential_26 (Sequential) (None, 128, 128, 25 2951680 ['concatenate_17[0][0]']
6)
concatenate_15 (Concatenate) (None, 512, 512, 25 0 ['sequential_15[0][0]',
6) 'sequential_20[0][0]',
'up_sampling2d_14[0][0]']
sequential_25 (Sequential) (None, 256, 256, 12 738560 ['concatenate_16[0][0]']
8)
up_sampling2d_18 (UpSampling2D (None, 256, 256, 25 0 ['sequential_26[0][0]']
) 6)
sequential_24 (Sequential) (None, 512, 512, 64 184960 ['concatenate_15[0][0]']
)
up_sampling2d_17 (UpSampling2D (None, 512, 512, 12 0 ['sequential_25[0][0]']
) 8)
concatenate_19 (Concatenate) (None, 256, 256, 64 0 ['sequential_16[0][0]',
0) 'sequential_21[0][0]',
'sequential_25[0][0]',
'up_sampling2d_18[0][0]']
concatenate_18 (Concatenate) (None, 512, 512, 32 0 ['sequential_15[0][0]',
0) 'sequential_20[0][0]',
'sequential_24[0][0]',
'up_sampling2d_17[0][0]']
sequential_28 (Sequential) (None, 256, 256, 12 886016 ['concatenate_19[0][0]']
8)
sequential_27 (Sequential) (None, 512, 512, 64 221824 ['concatenate_18[0][0]']
)
up_sampling2d_19 (UpSampling2D (None, 512, 512, 12 0 ['sequential_28[0][0]']
) 8)
concatenate_20 (Concatenate) (None, 512, 512, 38 0 ['sequential_15[0][0]',
4) 'sequential_20[0][0]',
'sequential_24[0][0]',
'sequential_27[0][0]',
'up_sampling2d_19[0][0]']
sequential_29 (Sequential) (None, 512, 512, 64 258688 ['concatenate_20[0][0]']
)
conv2d_64 (Conv2D) (None, 512, 512, 2) 130 ['sequential_20[0][0]']
conv2d_65 (Conv2D) (None, 512, 512, 2) 130 ['sequential_24[0][0]']
conv2d_66 (Conv2D) (None, 512, 512, 2) 130 ['sequential_27[0][0]']
conv2d_67 (Conv2D) (None, 512, 512, 2) 130 ['sequential_29[0][0]']
concatenate_21 (Concatenate) (None, 512, 512, 2) 0 ['conv2d_64[0][0]',
'conv2d_65[0][0]',
'conv2d_66[0][0]',
'conv2d_67[0][0]']
===============================================================================================
Total params: 36,644,680
Trainable params: 36,630,088
Non-trainable params: 14,592
_______________________________________________________________________________________________
The image of size 512×512×3 is passed through the architecture and we get a binary segmented output map of size 512×512×2 if deep supervision is disabled and 4×512×512×2 if deep supervision is enabled. While encoding the size of the input image keeps decreasing to 32×32×1024 till it reaches the bottleneck and then it regains its dimensions while decoding. At each layer, the size of the image is decreased by half, and the number of channels is increased by two folds.
It must be noted that we are using padding while performing encoding and decoding to maintain the image dimensions. It must also be noted that the decoding block gives the same output irrespective of the input shape at the same level. For example, the output shape of X1,1, X1,2, and X1,3 is 256×256×128 even though they have different input shapes i.e, X1,1 has 256×256×384, X1,2 has 256×256×512, and X1,3 has 256×256×640. Finally, an output image is generated which represents a label that corresponds to a particular object or class in the input image. If deep supervision is enabled then we get four output images of size 512×512×2 from X0,1, X0,2, X0,3,, and X0,4 respectively and if it is disabled then we get a single output image from X0,4.
Objective Function
According to the paper, the U-Net++ model was optimized on the combined loss of binary cross-entropy and dice coefficient. This can be defined as:

Where  and
and  denote the predicted probabilities and the ground truths of the ith image respectively, and N indicates the batch size.
denote the predicted probabilities and the ground truths of the ith image respectively, and N indicates the batch size.
Apply to an Image
Input Image:
.png)
Python3
import numpy as np
from PIL import Image
from tensorflow.keras.preprocessing import image
img = Image.open('cat.png')
img = img.resize((512, 512))
img_array = image.img_to_array(img)
img_array = np.expand_dims(img_array[:, :, :3], axis=0)
img_array = img_array / 255.
model = unet_plus_plus_model(input_shape=(
512, 512, 3), num_classes=2, deep_supervision=False)
predictions = model.predict(img_array)
predictions = np.squeeze(predictions, axis=0)
predictions = np.argmax(predictions, axis=-1)
predictions = Image.fromarray(np.uint8(predictions*255))
predictions = predictions.resize((img.width, img.height))
predictions.save('predicted_image.jpg')
predictions
|
Output:
1/1 [==============================] - 11s 11s/step

Note: It must be noted that while predicting you will not apply deep supervision as you only need the output from final layer (or node). You have to apply deep supervision while training only as you will optimize the model on combined loss from all the nodes.
Applications:
Although U-Net++ architecture is not yet explored in other domains like its predecessor U-Net model it is still useful for various image segmentation tasks which include semantic segmentation, instance segmentation, and medical image segmentation.
Share your thoughts in the comments
Please Login to comment...