Why Save Machine Learning Models?
Last Updated :
29 Jan, 2024
Machine learning models play a pivotal role in data-driven decision-making processes. Once a model is trained on a dataset, it becomes a valuable asset that can be used for making predictions on new, unseen data. In the context of R Programming Language, saving machine learning models is a crucial step for various reasons, ranging from reusability and scalability to deployment and collaboration.
Reasons to Save Machine Learning Models
1. Reusability
One of the primary reasons to save a machine learning model is reusability. Training a model can be a computationally intensive task, especially for complex models or large datasets. Once a model is trained, saving it allows for easy reuse of new data without the need to retrain the model each time. This is particularly beneficial when working with large datasets or in scenarios where frequent predictions are required.
2. Scalability
In real-world applications, machine learning models are often deployed to handle predictions on large datasets or in real-time. Saving the trained model and loading it as needed provides a scalable solution, avoiding the computational overhead of retraining the model for each prediction.
3. Deployment
Saved machine learning models are deployable in various environments, such as web applications, mobile apps, or server-based applications. This is crucial for integrating machine learning models into production systems, enabling real-world applications of data science.
4. Sharing and Collaboration
Saving machine learning models facilitates sharing and collaboration. Whether you are working in a team or sharing your work with the broader community, having a saved model file allows others to use your model without the need to replicate the training process. This consistency ensures that everyone is working with the same version of the model.
5. Consistency
Saving models ensures consistent usage across different environments. It helps avoid inconsistencies that may arise if models are retrained or modified differently in various locations. Consistency is essential for maintaining the integrity of model-based decision-making.
Saving Machine Learning Models in R
In R, there are several ways to save machine learning models, depending on the type of model and the packages used for training. Let’s explore a simple example using the saveRDS and readRDS functions.
R
install.packages("randomForest")
library(randomForest)
data(iris)
set.seed(123)
rf_model <- randomForest(Species ~ ., data = iris, ntree = 100)
summary(rf_model)
|
Output:
Length Class Mode
call 4 -none- call
type 1 -none- character
predicted 150 factor numeric
err.rate 400 -none- numeric
confusion 12 -none- numeric
votes 450 matrix numeric
oob.times 150 -none- numeric
classes 3 -none- character
importance 4 -none- numeric
importanceSD 0 -none- NULL
localImportance 0 -none- NULL
proximity 0 -none- NULL
ntree 1 -none- numeric
mtry 1 -none- numeric
forest 14 -none- list
y 150 factor numeric
test 0 -none- NULL
inbag 0 -none- NULL
terms 3 terms call
- call: This shows the function call that was used to create the object.
- type: Indicates the data type of the object. In this case, “character” for “type” suggests it might be a character vector.
- predicted: This seems to be a factor with 150 levels and numeric values.
- err.rate: A numeric vector with 400 values, likely representing error rates.
- confusion: A numeric matrix with dimensions 12×12, often used to display the confusion matrix.
- votes: A numeric matrix with 450 values, possibly representing votes.
- oob.times: A numeric vector with 150 values, indicating the number of times each observation is “out-of-bag” in the random forest.
- classes: A character vector with 3 levels, possibly representing the classes or categories in the data.
- importance: A numeric vector with 4 values, suggesting variable importance scores.
- importanceSD: This is NULL, meaning there is no standard deviation associated with variable importance.
- localImportance, proximity, inbag: All NULL, suggesting that local importance, proximity information, and in-bag information might not be available or not applicable.
- ntree, mtry: Numeric values, likely representing the number of trees and the number of variables tried at each split in the random forest.
- forest: A list with 14 elements, which could contain information about the individual trees in the random forest.
- y: A factor with 150 levels, possibly representing the response variable.
- terms: A terms object with 3 terms, indicating the terms used in the model.
It contains information about the model parameters, results, and other relevant details. If you have specific questions about any of these elements or if you want to perform specific actions on this object, please provide more details.
Save the Random Forest model
R
saveRDS(rf_model, "iris_rf_model.rds")
loaded_rf_model <- readRDS("iris_rf_model.rds")
|
Output:
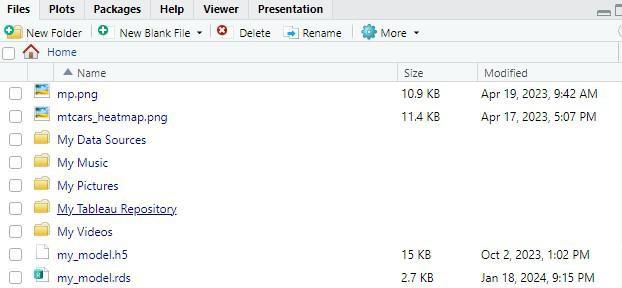
Save Machine Learning Models
Use the loaded model to make predictions on new data
R
new_data <- data.frame(
Sepal.Length = c(5.1, 5.9, 6.5),
Sepal.Width = c(3.5, 3.0, 3.2),
Petal.Length = c(1.4, 4.2, 5.1),
Petal.Width = c(0.2, 1.5, 2.0)
)
prediction <- predict(loaded_rf_model, new_data)
print(prediction)
|
Output:
1 2 3
setosa versicolor virginica
Levels: setosa versicolor virginica
Saving machine learning models is crucial for several reasons, and it serves various purposes in the lifecycle of a machine learning project.
Share your thoughts in the comments
Please Login to comment...