What is NODUPKEY Feature in PROC SQL?
Last Updated :
06 Feb, 2023
NODUPKEY is a powerful feature of the PROC SQL procedure in SAS, allowing users to quickly and easily remove duplicate observations from their data. This feature is especially useful when working with large datasets, as it can help to reduce processing time and reduce the amount of data that needs to be stored. In this blog post, we will take a look at what the NODUPKEY feature is, how it works, and when it is most useful.
NODUPKEY
NODUPKEY is a keyword option for the PROC SQL procedure in SAS. It is used to eliminate duplicate observations from a dataset. When NODUPKEY is specified, SAS will look at the values in the specified columns and remove any rows that have the same values in those columns. For example, if a dataset has two observations with the same values in the ID and Name columns, then the second observation will be removed when NODUPKEY is used. NODUPKEY works by creating a hash table of the values in the specified columns. This hash table is then used to compare the values in the columns and determine if any of the observations are duplicates. If a duplicate is found, then the observation is removed from the dataset.
Example
NODUPKEY is a feature in PROC SQL that allows you to identify and remove duplicate rows from a table. This feature compares the values in the specified columns and removes any rows where the values are the same. For example, if you have a table with the columns “ID” and “Name”, you can use the NODUPKEY feature in PROC SQL to remove any duplicate rows where the “ID” values are the same:
Query:
PROC SQL;
SELECT *
FROM table_name
NODUPKEY;
QUIT;
How to use NODUPKEY?
Using NODUPKEY is a relatively straightforward process. First, you need to specify which columns you want to use to determine if there are any duplicate observations. This is done by listing the columns in the NODUPKEY statement. For example, if you want to use the ID and Name columns to determine if there are any duplicates, then your NODUPKEY statement would look like this:
Query:
NODUPKEY ID Name;
Once you have specified which columns to use, you can then use the NODUPKEY keyword in the SELECT statement. This will tell SAS to look for any duplicate observations and remove them. For example, if you wanted to remove any duplicates from a dataset called “mydata” then your SELECT statement would look like this:
Query:
SELECT * FROM mydata NODUPKEY ID Name;
Implementation
For example, if your “customers” table has the following data:

Input
The NODUPKEY feature in PROC SQL is used to remove any duplicate records from a selected dataset. This feature can be used to ensure that only unique records are returned in the query results. For example, the following query can be used to remove any duplicate records from a table named “customers”:
Query:
PROC SQL;
SELECT *
FROM customers
NODUPKEY;
QUIT;
Output:
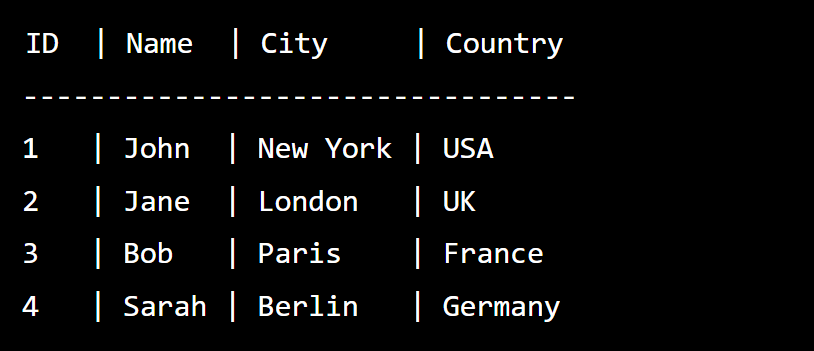
Output
As you can see, the duplicate record with ID 5 and all its values (Name: “John”, City: “New York”, Country: “USA”) has been eliminated from the output.
When To Use NODUPKEY
NODUPKEY is most useful when working with large datasets, as it can reduce processing time and the amount of data that needs to be stored. This is especially true if the dataset contains a lot of duplicate observations. By removing the duplicates, you can reduce the overall size of the dataset and make it easier to work with. NODUPKEY is also useful when you want to ensure that no duplicate observations are included in the dataset. For example, if you are performing a statistical analysis and want to ensure that all of the observations are unique, then using NODUPKEY can help to ensure that this is the case.
Conclusion
NODUPKEY is a powerful feature of the PROC SQL procedure in SAS, allowing users to quickly and easily remove duplicate observations from their data. By specifying which columns to use, SAS will look for any duplicate observations and remove them. This can help to reduce the size of the dataset and make it easier to work with, as well as ensure that no duplicate observations are included in the dataset when performing a statistical analysis.
Share your thoughts in the comments
Please Login to comment...