What is Information Retrieval?
Last Updated :
19 Sep, 2023
Information Retrieval (IR) can be defined as a software program that deals with the organization, storage, retrieval, and evaluation of information from document repositories, particularly textual information. Information Retrieval is the activity of obtaining material that can usually be documented on an unstructured nature i.e. usually text which satisfies an information need from within large collections which is stored on computers. For example, Information Retrieval can be when a user enters a query into the system.
Not only librarians, professional searchers, etc engage themselves in the activity of information retrieval but nowadays hundreds of millions of people engage in IR every day when they use web search engines. Information Retrieval is believed to be the dominant form of Information access. The IR system assists the users in finding the information they require but it does not explicitly return the answers to the question. It notifies regarding the existence and location of documents that might consist of the required information. Information retrieval also extends support to users in browsing or filtering document collection or processing a set of retrieved documents. The system searches over billions of documents stored on millions of computers. A spam filter, manual or automatic means are provided by Email program for classifying the mails so that it can be placed directly into particular folders.
An IR system has the ability to represent, store, organize, and access information items. A set of keywords are required to search. Keywords are what people are searching for in search engines. These keywords summarize the description of the information.
What is an IR Model?
An Information Retrieval (IR) model selects and ranks the document that is required by the user or the user has asked for in the form of a query. The documents and the queries are represented in a similar manner, so that document selection and ranking can be formalized by a matching function that returns a retrieval status value (RSV) for each document in the collection. Many of the Information Retrieval systems represent document contents by a set of descriptors, called terms, belonging to a vocabulary V. An IR model determines the query-document matching function according to four main approaches:
The estimation of the probability of user’s relevance rel for each document d and query q with respect to a set R q of training documents: Prob (rel|d, q, Rq)
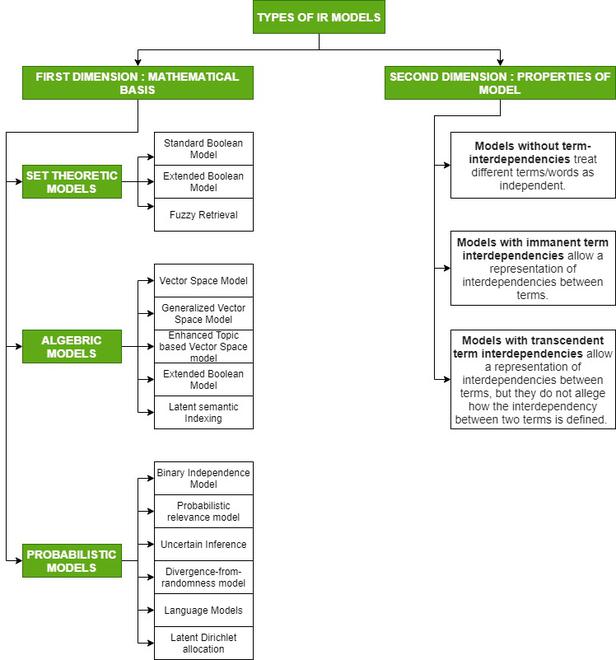
Types of IR Models
Components of Information Retrieval/ IR Model
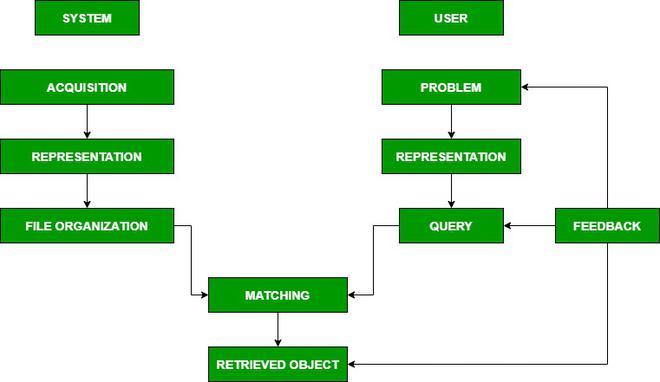
- Acquisition: In this step, the selection of documents and other objects from various web resources that consist of text-based documents takes place. The required data is collected by web crawlers and stored in the database.
- Representation: It consists of indexing that contains free-text terms, controlled vocabulary, manual & automatic techniques as well. example: Abstracting contains summarizing and Bibliographic description that contains author, title, sources, data, and metadata.
- File Organization: There are two types of file organization methods. i.e. Sequential: It contains documents by document data. Inverted: It contains term by term, list of records under each term. Combination of both.
- Query: An IR process starts when a user enters a query into the system. Queries are formal statements of information needs, for example, search strings in web search engines. In information retrieval, a query does not uniquely identify a single object in the collection. Instead, several objects may match the query, perhaps with different degrees of relevancy.
Difference Between Information Retrieval and Data Retrieval
| The software program that deals with the organization, storage, retrieval, and evaluation of information from document repositories particularly textual information. |
Data retrieval deals with obtaining data from a database management system such as ODBMS. It is A process of identifying and retrieving the data from the database, based on the query provided by user or application. |
| Retrieves information about a subject. |
Determines the keywords in the user query and retrieves the data. |
| Small errors are likely to go unnoticed. |
A single error object means total failure. |
| Not always well structured and is semantically ambiguous. |
Has a well-defined structure and semantics. |
| Does not provide a solution to the user of the database system. |
Provides solutions to the user of the database system. |
| The results obtained are approximate matches. |
The results obtained are exact matches. |
| Results are ordered by relevance. |
Results are unordered by relevance. |
| It is a probabilistic model. |
It is a deterministic model. |
User Interaction With Information Retrieval System
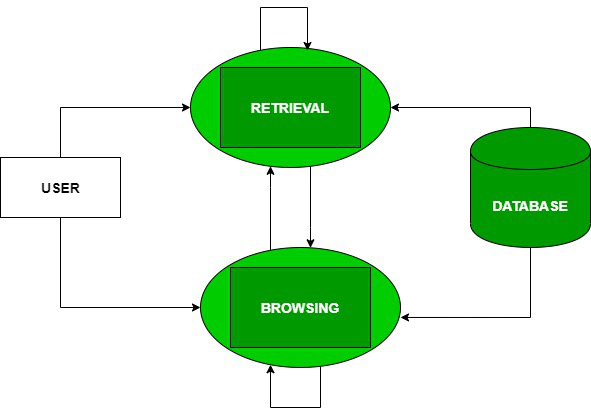
The User Task: The information first is supposed to be translated into a query by the user. In the information retrieval system, there is a set of words that convey the semantics of the information that is required whereas, in a data retrieval system, a query expression is used to convey the constraints which are satisfied by the objects. Example: A user wants to search for something but ends up searching with another thing. This means that the user is browsing and not searching. The above figure shows the interaction of the user through different tasks.
- Logical View of the Documents: A long time ago, documents were represented through a set of index terms or keywords. Nowadays, modern computers represent documents by a full set of words which reduces the set of representative keywords. This can be done by eliminating stopwords i.e. articles and connectives. These operations are text operations. These text operations reduce the complexity of the document representation from full text to set of index terms.
Past, Present, and Future of Information Retrieval
1. Early Developments: As there was an increase in the need for a lot of information, it became necessary to build data structures to get faster access. The index is the data structure for faster retrieval of information. Over centuries manual categorization of hierarchies was done for indexes.
2. Information Retrieval In Libraries: Libraries were the first to adopt IR systems for information retrieval. In first-generation, it consisted, automation of previous technologies, and the search was based on author name and title. In the second generation, it included searching by subject heading, keywords, etc. In the third generation, it consisted of graphical interfaces, electronic forms, hypertext features, etc.
3. The Web and Digital Libraries: It is cheaper than various sources of information, it provides greater access to networks due to digital communication and it gives free access to publish on a larger medium.
Advantages of Information Retrieval
1. Efficient Access: Information retrieval techniques make it possible for users to easily locate and retrieve vast amounts of data or information.
2. Personalization of Results: User profiling and personalization techniques are used in information retrieval models to tailor search results to individual preferences and behaviors.
3. Scalability: Information retrieval models are capable of handling increasing data volumes.
4. Precision: These systems can provide highly accurate and relevant search results, reducing the likelihood of irrelevant information appearing in search results.
Disadvantages of Information Retrieval
1. Information Overload: When a lot of information is available, users often face information overload, making it difficult to find the most useful and relevant material.
2. Lack of Context: Information retrieval systems may fail to understand the context of a user’s query, potentially leading to inaccurate results.
3. Privacy and Security Concerns: As information retrieval systems often access sensitive user data, they can raise privacy and security concerns.
4. Maintenance Challenges: Keeping these systems up-to-date and effective requires ongoing efforts, including regular updates, data cleaning, and algorithm adjustments.
5. Bias and fairness: Ensuring that information retrieval systems do not exhibit biases and provide fair and unbiased results is a crucial challenge, especially in contexts like web search engines and recommendation systems.
Share your thoughts in the comments
Please Login to comment...