Syntax Directed Translation in Compiler Design
Last Updated :
10 Apr, 2023
Parser uses a CFG(Context-free-Grammar) to validate the input string and produce output for the next phase of the compiler. Output could be either a parse tree or an abstract syntax tree. Now to interleave semantic analysis with the syntax analysis phase of the compiler, we use Syntax Directed Translation.
Conceptually, with both syntax-directed definition and translation schemes, we parse the input token stream, build the parse tree, and then traverse the tree as needed to evaluate the semantic rules at the parse tree nodes. Evaluation of the semantic rules may generate code, save information in a symbol table, issue error messages, or perform any other activities. The translation of the token stream is the result obtained by evaluating the semantic rules.
Definition
Syntax Directed Translation has augmented rules to the grammar that facilitate semantic analysis. SDT involves passing information bottom-up and/or top-down to the parse tree in form of attributes attached to the nodes. Syntax-directed translation rules use 1) lexical values of nodes, 2) constants & 3) attributes associated with the non-terminals in their definitions.
The general approach to Syntax-Directed Translation is to construct a parse tree or syntax tree and compute the values of attributes at the nodes of the tree by visiting them in some order. In many cases, translation can be done during parsing without building an explicit tree.
Example
E -> E+T | T
T -> T*F | F
F -> INTLIT
This is a grammar to syntactically validate an expression having additions and multiplications in it. Now, to carry out semantic analysis we will augment SDT rules to this grammar, in order to pass some information up the parse tree and check for semantic errors, if any. In this example, we will focus on the evaluation of the given expression, as we don’t have any semantic assertions to check in this very basic example.
E -> E+T { E.val = E.val + T.val } PR#1
E -> T { E.val = T.val } PR#2
T -> T*F { T.val = T.val * F.val } PR#3
T -> F { T.val = F.val } PR#4
F -> INTLIT { F.val = INTLIT.lexval } PR#5
For understanding translation rules further, we take the first SDT augmented to [ E -> E+T ] production rule. The translation rule in consideration has val as an attribute for both the non-terminals – E & T. Right-hand side of the translation rule corresponds to attribute values of the right-side nodes of the production rule and vice-versa. Generalizing, SDT are augmented rules to a CFG that associate 1) set of attributes to every node of the grammar and 2) a set of translation rules to every production rule using attributes, constants, and lexical values.
Let’s take a string to see how semantic analysis happens – S = 2+3*4. Parse tree corresponding to S would be

To evaluate translation rules, we can employ one depth-first search traversal on the parse tree. This is possible only because SDT rules don’t impose any specific order on evaluation until children’s attributes are computed before parents for a grammar having all synthesized attributes. Otherwise, we would have to figure out the best-suited plan to traverse through the parse tree and evaluate all the attributes in one or more traversals. For better understanding, we will move bottom-up in the left to right fashion for computing the translation rules of our example.
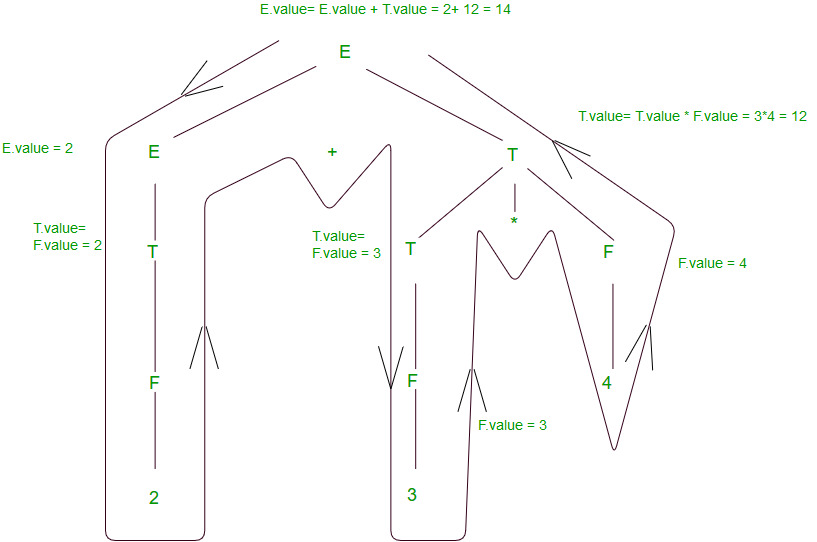
The above diagram shows how semantic analysis could happen. The flow of information happens bottom-up and all the children’s attributes are computed before parents, as discussed above. Right-hand side nodes are sometimes annotated with subscript 1 to distinguish between children and parents.
Additional Information
Synthesized Attributes are such attributes that depend only on the attribute values of children nodes.
Thus [ E -> E+T { E.val = E.val + T.val } ] has a synthesized attribute val corresponding to node E. If all the semantic attributes in an augmented grammar are synthesized, one depth-first search traversal in any order is sufficient for the semantic analysis phase.
Inherited Attributes are such attributes that depend on parent and/or sibling’s attributes.
Thus [ Ep -> E+T { Ep.val = E.val + T.val, T.val = Ep.val } ], where E & Ep are same production symbols annotated to differentiate between parent and child, has an inherited attribute val corresponding to node T.
Advantages of Syntax Directed Translation:
Ease of implementation: SDT is a simple and easy-to-implement method for translating a programming language. It provides a clear and structured way to specify translation rules using grammar rules.
Separation of concerns: SDT separates the translation process from the parsing process, making it easier to modify and maintain the compiler. It also separates the translation concerns from the parsing concerns, allowing for more modular and extensible compiler designs.
Efficient code generation: SDT enables the generation of efficient code by optimizing the translation process. It allows for the use of techniques such as intermediate code generation and code optimization.
Disadvantages of Syntax Directed Translation:
Limited expressiveness: SDT has limited expressiveness in comparison to other translation methods, such as attribute grammars. This limits the types of translations that can be performed using SDT.
Inflexibility: SDT can be inflexible in situations where the translation rules are complex and cannot be easily expressed using grammar rules.
Limited error recovery: SDT is limited in its ability to recover from errors during the translation process. This can result in poor error messages and may make it difficult to locate and fix errors in the input program.
Share your thoughts in the comments
Please Login to comment...