Intermediate Code Generation in Compiler Design
Last Updated :
19 Jan, 2024
In the analysis-synthesis model of a compiler, the front end of a compiler translates a source program into an independent intermediate code, then the back end of the compiler uses this intermediate code to generate the target code (which can be understood by the machine). The benefits of using machine-independent intermediate code are:
- Because of the machine-independent intermediate code, portability will be enhanced. For ex, suppose, if a compiler translates the source language to its target machine language without having the option for generating intermediate code, then for each new machine, a full native compiler is required. Because, obviously, there were some modifications in the compiler itself according to the machine specifications.
- Retargeting is facilitated.
- It is easier to apply source code modification to improve the performance of source code by optimizing the intermediate code.
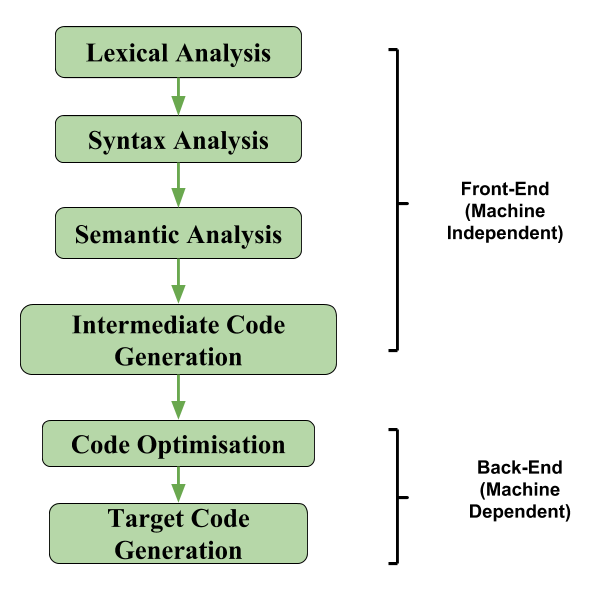
If we generate machine code directly from source code then for n target machine we will have optimizers and n code generator but if we will have a machine-independent intermediate code, we will have only one optimizer. Intermediate code can be either language-specific (e.g., Bytecode for Java) or language. independent (three-address code). The following are commonly used intermediate code representations:
- Postfix Notation:
- Also known as reverse Polish notation or suffix notation.
- In the infix notation, the operator is placed between operands, e.g., a + b. Postfix notation positions the operator at the right end, as in ab +.
- For any postfix expressions e1 and e2 with a binary operator (+) , applying the operator yields e1e2+.
- Postfix notation eliminates the need for parentheses, as the operator’s position and arity allow unambiguous expression decoding.
- In postfix notation, the operator consistently follows the operand.
Example 1: The postfix representation of the expression (a + b) * c is : ab + c *
Example 2: The postfix representation of the expression (a – b) * (c + d) + (a – b) is : ab – cd + *ab -+
Read more: Infix to Postfix
- Three-Address Code:
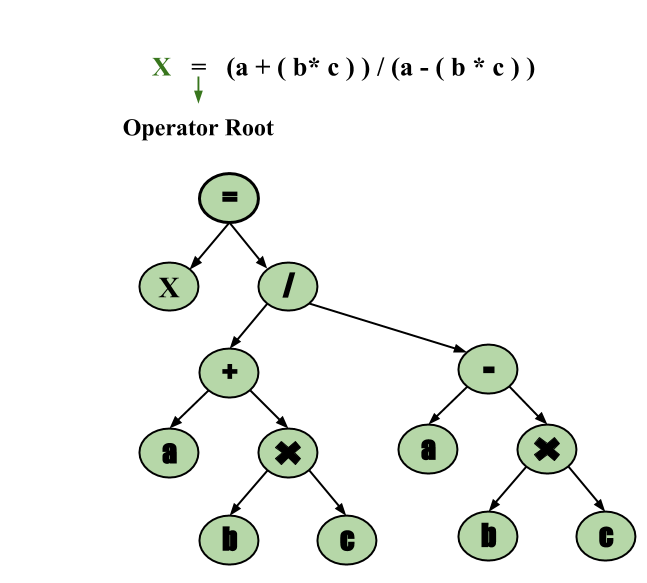
- Syntax Tree:
- A syntax tree serves as a condensed representation of a parse tree.
- The operator and keyword nodes present in the parse tree undergo a relocation process to become part of their respective parent nodes in the syntax tree. the internal nodes are operators and child nodes are operands.
- Creating a syntax tree involves strategically placing parentheses within the expression. This technique contributes to a more intuitive representation, making it easier to discern the sequence in which operands should be processed.
- The syntax tree not only condenses the parse tree but also offers an improved visual representation of the program’s syntactic structure,
Example: x = (a + b * c) / (a – b * c)
Advantages of Intermediate Code Generation:
Easier to implement: Intermediate code generation can simplify the code generation process by reducing the complexity of the input code, making it easier to implement.
Facilitates code optimization: Intermediate code generation can enable the use of various code optimization techniques, leading to improved performance and efficiency of the generated code.
Platform independence: Intermediate code is platform-independent, meaning that it can be translated into machine code or bytecode for any platform.
Code reuse: Intermediate code can be reused in the future to generate code for other platforms or languages.
Easier debugging: Intermediate code can be easier to debug than machine code or bytecode, as it is closer to the original source code.
Disadvantages of Intermediate Code Generation:
Increased compilation time: Intermediate code generation can significantly increase the compilation time, making it less suitable for real-time or time-critical applications.
Additional memory usage: Intermediate code generation requires additional memory to store the intermediate representation, which can be a concern for memory-limited systems.
Increased complexity: Intermediate code generation can increase the complexity of the compiler design, making it harder to implement and maintain.
Reduced performance: The process of generating intermediate code can result in code that executes slower than code generated directly from the source code.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...