Phases of a Compiler
Last Updated :
08 Nov, 2023
Prerequisite – Introduction of Compiler design
We basically have two phases of compilers, namely the Analysis phase and Synthesis phase. The analysis phase creates an intermediate representation from the given source code. The synthesis phase creates an equivalent target program from the intermediate representation.
A compiler is a software program that converts the high-level source code written in a programming language into low-level machine code that can be executed by the computer hardware. The process of converting the source code into machine code involves several phases or stages, which are collectively known as the phases of a compiler. The typical phases of a compiler are:
- Lexical Analysis: The first phase of a compiler is lexical analysis, also known as scanning. This phase reads the source code and breaks it into a stream of tokens, which are the basic units of the programming language. The tokens are then passed on to the next phase for further processing.
- Syntax Analysis: The second phase of a compiler is syntax analysis, also known as parsing. This phase takes the stream of tokens generated by the lexical analysis phase and checks whether they conform to the grammar of the programming language. The output of this phase is usually an Abstract Syntax Tree (AST).
- Semantic Analysis: The third phase of a compiler is semantic analysis. This phase checks whether the code is semantically correct, i.e., whether it conforms to the language’s type system and other semantic rules. In this stage, the compiler checks the meaning of the source code to ensure that it makes sense. The compiler performs type checking, which ensures that variables are used correctly and that operations are performed on compatible data types. The compiler also checks for other semantic errors, such as undeclared variables and incorrect function calls.
- Intermediate Code Generation: The fourth phase of a compiler is intermediate code generation. This phase generates an intermediate representation of the source code that can be easily translated into machine code.
- Optimization: The fifth phase of a compiler is optimization. This phase applies various optimization techniques to the intermediate code to improve the performance of the generated machine code.
- Code Generation: The final phase of a compiler is code generation. This phase takes the optimized intermediate code and generates the actual machine code that can be executed by the target hardware.
In summary, the phases of a compiler are: lexical analysis, syntax analysis, semantic analysis, intermediate code generation, optimization, and code generation.
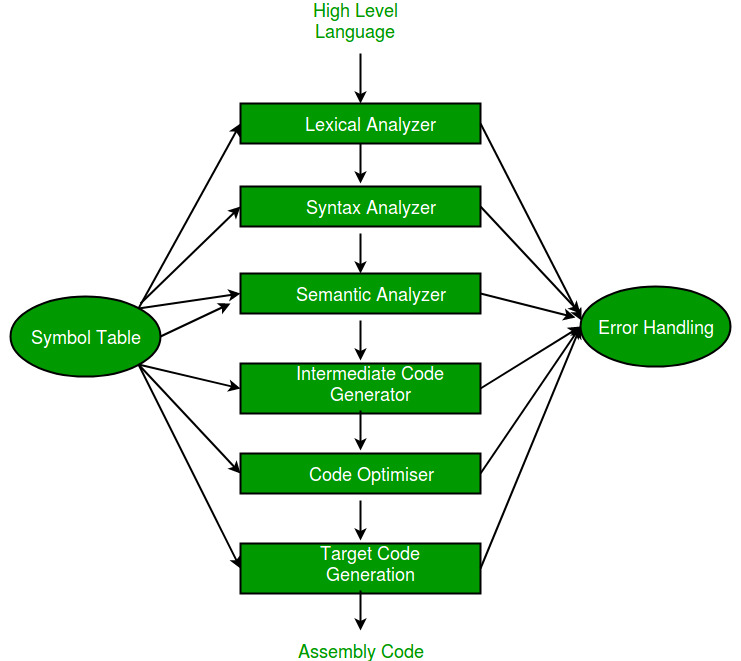
Symbol Table – It is a data structure being used and maintained by the compiler, consisting of all the identifier’s names along with their types. It helps the compiler to function smoothly by finding the identifiers quickly.
The analysis of a source program is divided into mainly three phases. They are:
- Linear Analysis-
This involves a scanning phase where the stream of characters is read from left to right. It is then grouped into various tokens having a collective meaning.
- Hierarchical Analysis-
In this analysis phase, based on a collective meaning, the tokens are categorized hierarchically into nested groups.
- Semantic Analysis-
This phase is used to check whether the components of the source program are meaningful or not.
The compiler has two modules namely the front end and the back end. Front-end constitutes the Lexical analyzer, semantic analyzer, syntax analyzer, and intermediate code generator. And the rest are assembled to form the back end.
- Lexical Analyzer –
It is also called a scanner. It takes the output of the preprocessor (which performs file inclusion and macro expansion) as the input which is in a pure high-level language. It reads the characters from the source program and groups them into lexemes (sequence of characters that “go together”). Each lexeme corresponds to a token. Tokens are defined by regular expressions which are understood by the lexical analyzer. It also removes lexical errors (e.g., erroneous characters), comments, and white space.
- Syntax Analyzer – It is sometimes called a parser. It constructs the parse tree. It takes all the tokens one by one and uses Context-Free Grammar to construct the parse tree.
Why Grammar?
The rules of programming can be entirely represented in a few productions. Using these productions we can represent what the program actually is. The input has to be checked whether it is in the desired format or not.
The parse tree is also called the derivation tree. Parse trees are generally constructed to check for ambiguity in the given grammar. There are certain rules associated with the derivation tree.
- Any identifier is an expression
- Any number can be called an expression
- Performing any operations in the given expression will always result in an expression. For example, the sum of two expressions is also an expression.
- The parse tree can be compressed to form a syntax tree
Syntax error can be detected at this level if the input is not in accordance with the grammar.

- Semantic Analyzer – It verifies the parse tree, whether it’s meaningful or not. It furthermore produces a verified parse tree. It also does type checking, Label checking, and Flow control checking.
- Intermediate Code Generator – It generates intermediate code, which is a form that can be readily executed by a machine We have many popular intermediate codes. Example – Three address codes etc. Intermediate code is converted to machine language using the last two phases which are platform dependent.
Till intermediate code, it is the same for every compiler out there, but after that, it depends on the platform. To build a new compiler we don’t need to build it from scratch. We can take the intermediate code from the already existing compiler and build the last two parts.
- Code Optimizer – It transforms the code so that it consumes fewer resources and produces more speed. The meaning of the code being transformed is not altered. Optimization can be categorized into two types: machine-dependent and machine-independent.
- Target Code Generator – The main purpose of the Target Code generator is to write a code that the machine can understand and also register allocation, instruction selection, etc. The output is dependent on the type of assembler. This is the final stage of compilation. The optimized code is converted into relocatable machine code which then forms the input to the linker and loader.
All these six phases are associated with the symbol table manager and error handler as shown in the above block diagram.
The advantages of using a compiler to translate high-level programming languages into machine code are:
- Portability: Compilers allow programs to be written in a high-level programming language, which can be executed on different hardware platforms without the need for modification. This means that programs can be written once and run on multiple platforms, making them more portable.
- Optimization: Compilers can apply various optimization techniques to the code, such as loop unrolling, dead code elimination, and constant propagation, which can significantly improve the performance of the generated machine code.
- Error Checking: Compilers perform a thorough check of the source code, which can detect syntax and semantic errors at compile-time, thereby reducing the likelihood of runtime errors.
- Maintainability: Programs written in high-level languages are easier to understand and maintain than programs written in low-level assembly language. Compilers help in translating high-level code into machine code, making programs easier to maintain and modify.
- Productivity: High-level programming languages and compilers help in increasing the productivity of developers. Developers can write code faster in high-level languages, which can be compiled into efficient machine code.
In summary, compilers provide advantages such as portability, optimization, error checking, maintainability, and productivity.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...