Imbalanced datasets impact the performance of the machine learning models and the Synthetic Minority Over-sampling Technique (SMOTE) addresses the class imbalance problem by generating synthetic samples for the minority class. The article aims to explore the SMOTE, its working procedure, and various extensions to enhance its capability. The article provides Python implementations for SMOTE and its extensions, offering a comprehensive guide to tackle the problem of Imbalanced datasets in Python.
Data Imbalance in Classification Problem
Data imbalance in classification refers to skewed class distribution, hindering machine learning models’ performance. Majority classes dominate while minority classes are underrepresented. This challenge arises when one category vastly outnumbers others. Techniques like Oversampling, Undersampling, Threshold moving, and SMOTE help address this issue. Handling imbalanced datasets is crucial to prevent biased model outputs, especially in multi-classification problems.
Synthetic Minority Over-Sampling Technique
The Synthetic Minority Over-Sampling Technique (SMOTE) is a powerful method used to handle class imbalance in datasets. SMOTE handles this issue by generating samples of minority classes to make the class distribution balanced. SMOTE works by generating synthetic examples in the feature space of the minority class.
Working Procedure of SMOTE
- Identify Minority Class Instances: SMOTE operates on datasets where one or more classes are significantly underrepresented compared to others. The first step is to identify the minority class or classes in the dataset.
- Nearest Neighbor Selection: For each minority class instance, SMOTE identifies its k nearest neighbors in the feature space. The number of nearest neighbors, denoted as k, is a parameter specified by the user.
- Synthetic Sample Generation: For each minority class instance, SMOTE randomly selects one of its k nearest neighbors. It then generates synthetic samples along the line segment joining the minority class instance and the selected nearest neighbor in the feature space.
- Controlled Oversampling: The amount of oversampling is controlled by a parameter called the oversampling ratio, which specifies the desired ratio of synthetic samples to real minority class samples. By default, SMOTE typically aims to balance the class distribution by generating synthetic samples until the minority class reaches the same size as the majority class.
- Repeat for All Minority Class Instances: Steps 2-4 are repeated for all minority class instances in the dataset, generating synthetic samples to augment the minority class.
- Create Balanced Dataset: After generating synthetic samples for the minority class, the resulting dataset becomes more balanced, with a more equitable distribution of instances across classes.
Implementing SMOTE for Imbalanced Classification in Python
In this section, we’ll use Pima Indian Diabetes Dataset. In the following code snippet, we load the dataset and plot the class distribution.
Python
import matplotlib.pyplot as plt
import pandas as pd
data = pd.read_csv('diabetes.csv')
x=data.drop(["Outcome"],axis=1)
y=data["Outcome"]
count_class = y.value_counts() # Count the occurrences of each class
plt.bar(count_class.index, count_class.values)
plt.xlabel('Class')
plt.ylabel('Count')
plt.title('Class Distribution')
plt.xticks(count_class.index, ['Class 0', 'Class 1'])
plt.show()
Output:
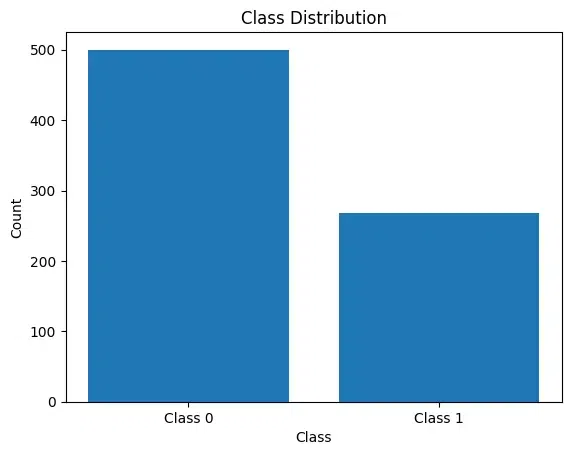
From the above plot, it is clear that the data is imbalanced.
Now, lets use SMOTE to handle this problem. We will utilize SMOTE to address data imbalance by generating synthetic samples for the minority class, indicated by ‘sampling_strategy=’minority”. By applying SMOTE, the code balances the class distribution in the dataset, as confirmed by ‘y.value_counts()’ displaying the count of each class after resampling.
Python
from imblearn.over_sampling import SMOTE
smote=SMOTE(sampling_strategy='minority')
x,y=smote.fit_resample(x,y)
y.value_counts()
Output:
Outcome
1 500
0 500
Name: count, dtype: int64
Extensions of SMOTE Models
SMOTE effectively addresses data imbalance by generating synthetic samples, enriching the minority class and refining decision boundaries. Despite its benefits, SMOTE’s computational demands can escalate with larger datasets and high-dimensional feature spaces.
To enhance SMOTE’s capability to handle various data scenarios, several extensions have been developed:
- ADASYN
- Borderline SMOTE
- SMOTE-ENN (Edited Nearest Neighbors)
- SMOTE+TOMEK
- SMOTE-NC (Nominal Continuous)
ADASYN: Adaptive Synthetic Sampling Approach
ADASYN, an extension of the SMOTE technique, is also used in handling imbalanced datasets. ADASYN focuses on local densities of minority classes. It finds out the regions where the imbalance is very severe and applies the strategy to generate synthetic samples there. It generates more samples where the density is high and fewer samples where the density is low. This approach is highly useful in scenarios where class distribution varies across the feature space.
Working Procedure of ADASYN
- Class Imbalance Ratios: The initial step is ADASYN is to calculate the ratio of minority class which is obtained by dividing the number of majority class samples by the number of minority class samples.
- Finding density distribution: For every minority instance, we find its k-nearest neighbors. Then we find the distance between them using metrics like Manhattan distance or Euclidean distance. If the instances are surrounded by more nearby neighbors, then we consider the density to be higher else the density is considered to be low.
- Sample generation ratio: Once both class imbalance ratio and density distribution are calculated, we compute the sample generation ratio. It finds out how many samples are to be generated for each minority class instance. For Higher densities and larger imbalanced instances, more synthetic samples are generated.
- Generating synthetic samples: By combining the minority instances with their nearest neighbors, new samples are generated.
- Balanced dataset creation: By combining the new synthetic samples with the original minority instances, the frequency of the minority classes increases. This makes the dataset balanced and helps the model to learn more accurately.
Python Implementation For ADASYN
Python
from imblearn.over_sampling import ADASYN
# Applying ADASYN
adasyn = ADASYN(sampling_strategy='minority')
x_resampled, y_resampled = adasyn.fit_resample(x, y)
# Count outcome values after applying ADASYN
y_resampled.value_counts()
Output:
Outcome
1 500
0 500
Name: count, dtype: int64
Borderline SMOTE
Borderline SMOTE is designed to better address the issue of misclassification of minority class samples that are near the borderline between classes. These samples are often the hardest to classify and are more likely to be mislabeled by classifiers. Borderline SMOTE focuses on generating synthetic samples near the decision boundary between the minority and majority classes. It targets instances that are more challenging to classify, aiming to improve the generalization performance of classifiers.
Working Procedure of Borderline SMOTE
- Identify Borderline Samples: First, it identifies the minority class samples that are near the borderline. These are samples that are close to or are overlapping with the majority class.
- Nearest Neighbors Analysis: For each borderline minority sample, the algorithm finds the nearest neighbors. It then determines whether these neighbors are from the same class (minority) or the majority class.
- Synthetic Sample Generation: Synthetic samples are generated by interpolating between the borderline minority samples and their nearest minority class neighbors, aiming to strengthen the minority class presence around the borderline.
Python Implementation For Borderline SMOTE
Python
from imblearn.over_sampling import BorderlineSMOTE
blsmote = BorderlineSMOTE(sampling_strategy='minority', kind='borderline-1')
X_resampled, y_resampled = blsmote.fit_resample(x, y)
y_resampled.value_counts()
Output:
Outcome
1 500
0 500
Name: count, dtype: int64
SMOTE-ENN (Edited Nearest Neighbors)
SMOTE-ENN combines the SMOTE method with the Edited Nearest Neighbors (ENN) rule. ENN is used to clean the data by removing any samples that are misclassified by their nearest neighbors. This combination helps in cleaning up the synthetic samples, improving the overall quality of the dataset. The objective of ENN is to remove noisy or ambiguous samples, which may include both minority and majority class instances.
Working Procedure of SMOTE-ENN (Edited Nearest Neighbors)
- SMOTE Application: First, apply SMOTE to generate synthetic samples.
- ENN Application: Then, use ENN to remove synthetic or original samples that have a majority of their nearest neighbors belonging to the opposite class.
- Cleaning Data: This step helps in removing noisy instances and those that are likely to be misclassified.
Python Implementation for SMOTE-ENN (Edited Nearest Neighbors)
Python
from imblearn.combine import SMOTEENN
smote_enn = SMOTEENN()
X_resampled, y_resampled = smote_enn.fit_resample(x, y)
y_resampled.value_counts()
Output:
Outcome
1 297
0 215
Name: count, dtype: int64
- Initial Distribution: Before applying SMOTE-ENN, the distribution of the classes was 500 instances of class 0 and 268 instances of class 1.
- SMOTE Oversampling: SMOTE generates synthetic samples for the minority class (class 1) to balance the class distribution. This increases the number of instances in class 1.
- Edited Nearest Neighbors (ENN):
- After SMOTE oversampling, the dataset contain synthetic samples that are misclassified or considered noisy by ENN.
- ENN removes some of these synthetic samples, which lead to a reduction in the number of instances for both classes, but especially for class 1 since it was oversampled.
Therefore, after applying SMOTE-ENN, class 1 has 297 instances, and class 0 has 215 instances.
SMOTE- TOMEK Links
SMOTE+TOMEK links combine the SMOTE technique with TOMEK links, which are pairs of very close instances, but from opposite classes. By removing TOMEK links, instances that are close to each other but belong to different classes may be eliminated, which can help in reducing overlap between classes and improving the separability of the classes.
Working Procedure of SMOTE- TOMEK Links
- Finding Nearest Neighbors: Compute the nearest neighbor from the same class and the nearest neighbor from a different class for each instance in the dataset. Usually, a distance measure like Euclidean distance is used to find these closest neighbors.
- Finding Tomek Links: Repeatedly go over each pair of dataset instances. Determine whether each pair, in accordance with the specified criteria, forms a Tomek link. Mark the two occurrences for possible removal from the dataset if a Tomek link is found.
- Eliminating Ambiguous Instances: Once all Tomek linkages within the dataset have been found, the instances that comprise these links may be considered ambiguous or maybe noisy. These instances are then removed from the dataset.
- Dataset Cleaning: This reduces the overlap between classes and can improve the classification performance.
Python Implementation for SMOTE- TOMEK Links
Python
from imblearn.combine import SMOTETomek
smt = SMOTETomek(sampling_strategy='auto')
X_resampled, y_resampled = smt.fit_resample(x, y)
y_resampled.value_counts()
Output:
Outcome
1 471
0 471
Name: count, dtype: int64
- After applying SMOTE-TOMEK Links, the dataset achieves a balanced class distribution, with both classes having the same number of instances (471 instances each).
- This balance indicates that the synthetic samples generated by SMOTE effectively augmented the minority class, while the removal of TOMEK links helped in cleaning up the dataset and improving class separation.
SMOTE-NC (Nominal Continuous)
SMOTE-NC is a variant of SMOTE that is suitable for datasets containing a mix of nominal (categorical) and continuous features. It modifies the SMOTE algorithm to correctly handle categorical data. The traditional SMOTE algorithm excels in generating synthetic samples to address class imbalance in datasets with only numerical features. However, when categorical features are present, applying SMOTE directly can be problematic. This is because SMOTE operates in the feature space, interpolating between instances based on their numerical attributes. Interpolating between categorical features is not meaningful and can lead to synthetic samples that do not accurately represent the original data.
SMOTE-NC addresses this challenge By integrating the treatment of categorical and numerical features, SMOTE-NC enables the creation of synthetic samples that maintain the integrity of the original dataset while balancing the class distribution.
Working Procedure of SMOTE-NC (Nominal Continuous)
- Handling Nominal Features: Traditional SMOTE operates in the feature space by interpolating between minority class instances. However, when categorical features are present, it’s not meaningful to interpolate between categories directly. SMOTE-NC addresses this by considering the categorical features separately and ensuring that synthetic samples preserve the categorical properties of the original data.
- Combining SMOTE with Handling Nominal Features: SMOTE-NC extends the SMOTE algorithm to handle both nominal and continuous features appropriately. It generates synthetic samples by oversampling the minority class instances in the continuous feature space while preserving the distribution of categorical features.
- Integration with Categorical Encoding: Before applying SMOTE-NC, categorical features need to be encoded into a numerical representation. This encoding could be done using techniques like one-hot encoding or ordinal encoding, depending on the nature of the categorical variables.
- Preservation of Feature Characteristics: During the synthetic sample generation process, SMOTE-NC ensures that the categorical features of the synthetic samples align with the original dataset. This helps in maintaining the integrity of the dataset and ensuring that the synthetic samples accurately represent the minority class.
Note: Diabetes dataset may not be suitable for SMOTENC due to its lack of categorical features. SMOTENC is better suited for datasets where a mix of categorical and numerical features is present.
Python Implementation for SMOTE-NC (Nominal Continuous)
For this example, we have use of SMOTENC for handling datasets with both categorical and numerical features. It creates a toy dataset with imbalanced classes, applies SMOTENC to balance the classes while preserving categorical features, and prints the original and resampled class distributions.
Python
import numpy as np
from sklearn.datasets import make_classification
from imblearn.over_sampling import SMOTENC
# Create a toy dataset with a significant imbalance between two classes
X, y = make_classification(n_classes=2, class_sep=2,
weights=[0.1, 0.9], n_informative=3, n_redundant=1, flip_y=0,
n_features=5, n_clusters_per_class=1, n_samples=100, random_state=10)
# Print original class distribution
print('Original class distribution:')
print('Class 0:', np.bincount(y)[0], 'Class 1:', np.bincount(y)[1])
# Indicate which features are categorical (e.g., features at index 0 and 3 are categorical)
categorical_features = [0, 3]
# Initialize SMOTENC specifying which features are categorical
smote_nc = SMOTENC(categorical_features=categorical_features, random_state=42)
# Perform the resampling
X_resampled, y_resampled = smote_nc.fit_resample(X, y)
# Print the resampled data size and class distribution
print('\nResampled class distribution:')
print('Class 0:', np.bincount(y_resampled)[0], 'Class 1:', np.bincount(y_resampled)[1])
Output:
Original class distribution:
Class 0: 10 Class 1: 90
Resampled class distribution:
Class 0: 90 Class 1: 90
SMOTE for Imbalanced Classification: When to Use
| Algorithm | Best Use Case | Strengths | When to Use |
|---|
| Traditional SMOTE | General imbalanced datasets where minority class enhancement is needed. | Increases the number of minority class samples through interpolation, improving the generalization ability of classifiers. | Use when your dataset is imbalanced but doesn’t have extreme noise or overlapping class issues. Suitable for straightforward augmentation needs. |
|---|
| ADASYN (Adaptive Synthetic Sampling) | Datasets where imbalance varies significantly across the feature space. | Focuses on generating samples next to the original samples that are harder to learn, adapting to varying degrees of class imbalance. | Use when certain areas of the feature space are more imbalanced than others, requiring adaptive density estimation. |
|---|
| Borderline SMOTE | Datasets where minority class examples are close to the decision boundary. | Enhances classification near the borderline where misclassification risk is high. | Use when data points from different classes overlap and are prone to misclassification, particularly in binary classification problems. |
|---|
| SMOTE-NC (Nominal Continuous) | Datasets that include a combination of nominal (categorical) and continuous features. | Handles mixed data types without distorting the categorical feature space. | Use when your dataset includes both categorical and continuous inputs, ensuring that synthetic samples respect the nature of both data types. |
|---|
| SMOTE-ENN (Edited Nearest Neighbors) | Datasets with potential noise and mislabeled examples. | Combines over-sampling with cleaning to remove noisy and misclassified instances. | Use when the dataset is noisy or contains outliers, and you want to refine the class boundary further after over-sampling. |
|---|
| SMOTE+TOMEK | Best for reducing overlap between classes after applying SMOTE. | Cleans the data by removing Tomek links, which can help in enhancing the classifier’s performance. | Use when you need a cleaner dataset with less overlap between classes, suitable for situations where class separation is a priority. |
|---|
Conclusion
To sum up, SMOTE is an effective technique to handle imbalanced datasets. It finds the minority class in the dataset and generates synthetic samples for them. It thus helps in balancing data which makes the machine learning model better learn. It is widely used in classification problems. However, it is essential to carefully analyze the problem before applying the method, as sometimes it might lead to trade-offs. Overall, SMOTE plays a vital role in handling imbalance datasets.
FAQs on SMOTE for Imbalanced Classification
What is SMOTE?
SMOTE stands for Synthetic Minority Over-sampling Technique. It is a pre-processing technique used to handle class imbalance. It balances the data by generating synthetic samples for the minority class.
Does SMOTE work for all types of machine learning problems?
SMOTE is mostly used for classification problems where class imbalance is prevalent. But it may not be suitable for all types of problems, so it’s essential to consider its limitations.
Can SMOTE introduce overfitting?
Yes, SMOTE can introduce overfitting if synthetic samples are generated excessively.
How do I implement SMOTE in Python?
SMOTE can be implemented in python using libraries, including imbalanced-learn (imblearn) and scikit-learn.
Share your thoughts in the comments
Please Login to comment...