YouTube has become a significant platform for communication and expression, where people from all over the world can share their thoughts and opinions on various videos. These comments can provide a deep insight into what the viewer perceives and their feedback on the content. This allows content creators to understand the responses of viewers and make improvements to provide their audience with better quality and experience. This also holds immense potential for marketing companies to understand their client’s expectations and sentiments from the videos. Also, it is useful for the general audience to know what other viewers have to say about the video and engage in discussions with each other. In this article, we are going to perform a sentimental analysis of the YouTube comments that we have collected using the YouTube API.
Sentimental Analysis on YouTube Comments
Opinion Mining is a technique used to determine the emotions or sentiments expressed in a piece of text. YouTube comments analysis helps in understanding the emotional responses of viewers towards the video content.
Using NLP for analyzing YouTube comments offers advantages:
- The data generated by users in the form of comments is vast and NLP tools handle large datasets efficiently, making it possible to analyze comments at scale.
- The content creators are able to gain better insights into their audience’s preferences, reactions and emotional engagement.
Colab link: Youtube Comment Analysis
Tutorial on YouTube Comment Analysis
The approach for this project is quite straightforward. First, we are fetching comments from any YouTube video using the official YouTube API. Then, using some methods, we will improve the quality of our set of comments by filtering out irrelevant comments and saving the most relevant comments in a text file. Finally, using natural language processing techniques, we will analyze the sentiment of the comments, the overall sentiment score, and the most positive and most negative comments.
Step 1: Generating API Key
First, we need to get the API key for Youtube API to fetch comments.
-(1)-(1)-(2).png)
- Click on ENABLE APIS AND SERVICES, to enable services for api
-(1).png)
- Search for youtube data api v3, and click on the first result.
-(1).png)
- Click on ENABLE, to activate this api.
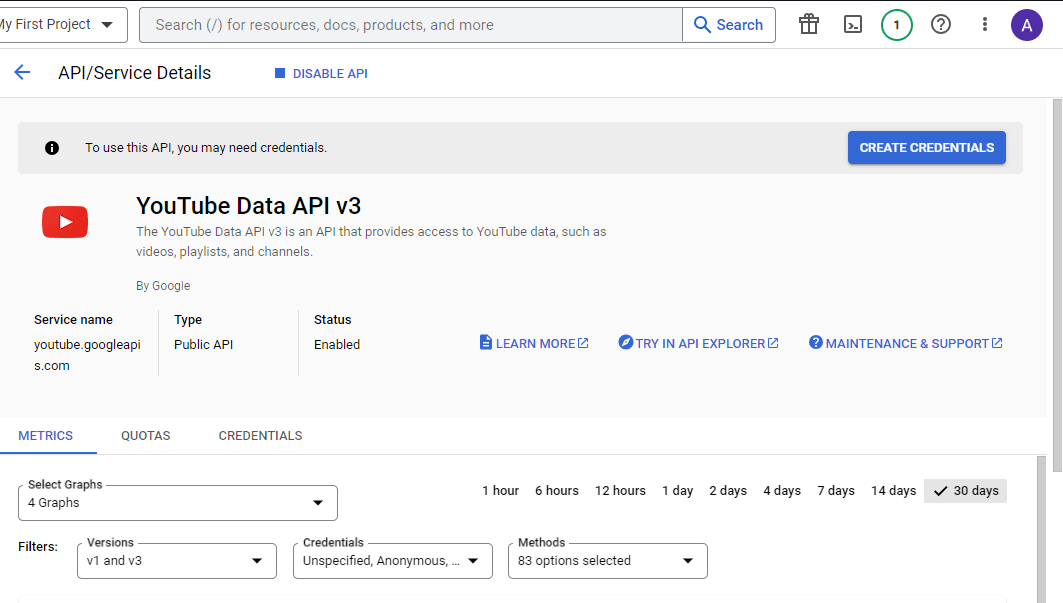
- The API has been activated, now click on CREATE CREDENTIALS, to get the API Key.
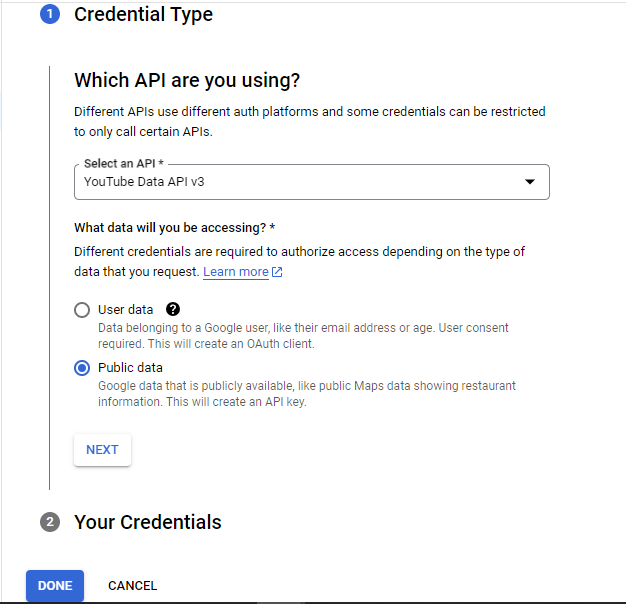
- Select the Public Data radio button, to have access to publicly available youtube data, and click NEXT.
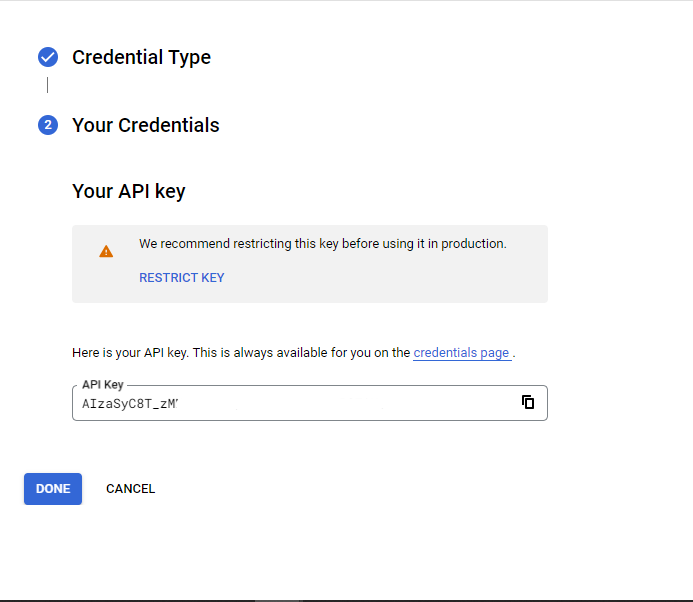
API Key has been generated, make sure you save the API key securely, as anyone with access to the API Key can use your account resources to access Youtube data; Click DONE after copying the API key.
Step 2: Importing dependencies
Now, after generating the API Key, let’s proceed to the programming section. Install necessary modules, for our project using the following commands.
- The emoji package in Python allows us to use and print emoji.
- The vaderSentiment package is a sentiment analysis tool.
- The google-api-python-client is package used to interact with Google Services and APIs.
!pip install emoji
!pip install vaderSentiment
!pip install goolge-api-python-client
Now in the project file, import the dependencies
Python3
from googleapiclient.discovery import build
import re
import emoji
from vaderSentiment.vaderSentiment import SentimentIntensityAnalyzer
import matplotlib.pyplot as plt
|
Here, we have imported all the modules required for this project and will be using all of them further
Step 3: Fetching Comments
We have considered Mission Impossible – Deard Reckoning Part One for sentiment analysis. For that, we have set up API credentials and stored API key in a variabel name API_KEY. After, taking the input for YouTube URL.
The YouTube API does not take the URL instead it takes the video id as arguments. So, we are slicing the input for accessing the last 11 characters of the URL as the video id consists of 11 characters in it.
Python3
API_KEY = 'AIzaSyCNO6aypXXXXXXXXXXXXXXXXXXXXXXXXXX'
youtube = build('youtube', 'v3', developerKey=API_KEY)
video_id = input('Enter Youtube Video URL: ')[-11:]
print("video id: " + video_id)
video_response = youtube.videos().list(
part='snippet',
id=video_id
).execute()
video_snippet = video_response['items'][0]['snippet']
uploader_channel_id = video_snippet['channelId']
print("channel id: " + uploader_channel_id)
|
Output:
Enter Youtube Video URL: https://www.youtube.com/watch?v=avz06PDqDbM
video id: avz06PDqDbM
channel id: UCF9imwPMSGz4Vq1NiTWCC7g
Using the above code snippet, we have fetched the channel id of the uploader.
Now, we are fetching the comments for a video and storing the comments temporarily in a list. Using the following code, we are initializing a list comments to store the fetched comments, and looping the requests until 600 comments are fetched, as the YouTube API only allows us to query 100 comments per request. Next we are making a request to API to send all the comments which weren’t made by the uploader of the video in order to make a comments set relevant, by checking equality of channel id of the person who made a comment and the channel id of the uploader. Then we are appending the comments the list until it is atleast 600 comments are fetched.
Python3
print("Fetching Comments...")
comments = []
nextPageToken = None
while len(comments) < 600:
request = youtube.commentThreads().list(
part='snippet',
videoId=video_id,
maxResults=100,
pageToken=nextPageToken
)
response = request.execute()
for item in response['items']:
comment = item['snippet']['topLevelComment']['snippet']
if comment['authorChannelId']['value'] != uploader_channel_id:
comments.append(comment['textDisplay'])
nextPageToken = response.get('nextPageToken')
if not nextPageToken:
break
comments[:5]
|
Output:
Fetching Comments...
['This looks like a commercial for Botox',
'Fun facts: The word "Key" has been mentioned 90 times in this movie. Can't stop laughing.',
'I didn't realise it was a movie..<br>Completely lost in it ✨ <br>A total masterpiece I'll say',
'Mission impossible - Son of hunt 1 ????',
'Rented yestarday, what a waste of $20. More low quality badly done car scenes since films were invented.']
Now as it is visible, that some of the comments contains hyperlinks and some of the comments only has emojis, this creates irrelevancy, so first we need to filter out this comments before moving forward.
Step 4: Filtering Comments
For filtering comments, first we created a re-pattern to identify comments with hyperlinks and made a variable threshold ratio with value 0.65 to filter out all the comments that consists of emojis more than 35% of whole comments to handle irrelevancy.
Then, we have made an empty list assigned to variable named relevant_comments to store quality comments.
Next, we are looping through all the comments, calculating the emoji count in the comment using emoji_count function of emoji module we imported earlier and text character count using re pattern.
Then, we are checking for empty comments or comments with no character (just emojis) and presence of no hyperlink using pattern search, then making sure the ratio of text character to total count of comment text is greater than threshold ratio, before appending it to the relevant_comments list.
Python3
hyperlink_pattern = re.compile(
r'http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*\\(\\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+')
threshold_ratio = 0.65
relevant_comments = []
for comment_text in comments:
comment_text = comment_text.lower().strip()
emojis = emoji.emoji_count(comment_text)
text_characters = len(re.sub(r'\s', '', comment_text))
if (any(char.isalnum() for char in comment_text)) and not hyperlink_pattern.search(comment_text):
if emojis == 0 or (text_characters / (text_characters + emojis)) > threshold_ratio:
relevant_comments.append(comment_text)
relevant_comments[:5]
|
Output:
['this looks like a commercial for botox',
'fun facts: the word "key" has been mentioned 90 times in this movie. can't stop laughing.',
'i didn't realise it was a movie..<br>completely lost in it ✨ <br>a total masterpiece i'll say',
'mission impossible - son of hunt 1 ????',
'rented yestarday, what a waste of $20. more low quality badly done car scenes since films were invented.']
Step 5: Storing comments in a text file for further access
Using the provide code, we checked if, ytcomment.txt is not present in the current directory, it will be created automatically, and if exists, it will be erased and all the comments will be added into the file by separating each comment with a new line character.
Here, we have used encoding as utf-8 as for storing the emojis we need to make the encoding utf-8 from standard one.
Python3
f = open("ytcomments.txt", 'w', encoding='utf-8')
for idx, comment in enumerate(relevant_comments):
f.write(str(comment)+"\n")
f.close()
print("Comments stored successfully!")
|
Output:
Comments stored successfully!
Step 6: Analyzing Comments
Now here, comes most important part – Analyzing the sentiment of comments.
Firstly, we have created a function sentiment_scores which takes two parameters – comment (string) and polarity (list). The function first creates an object for the SentimentIntensityAnalyzer class of the vaderSentiment module we imported in the beginning, then it analyses the comment and stores polarity scores in the dictionary variable sentiment_dict then appends the compund score to the polarity list and returns the polarity list. Then, we have initiated an empty list assigned to variable polarity, we are opening ytcomments.txt in read mode with encoding utf-8 for permitting emojis as well, then we are reading each comment and parsing the comment and polarity list to sentiment_scores function whose return value is assigned to polarity (overwritten).
Python3
def sentiment_scores(comment, polarity):
sentiment_object = SentimentIntensityAnalyzer()
sentiment_dict = sentiment_object.polarity_scores(comment)
polarity.append(sentiment_dict['compound'])
return polarity
polarity = []
positive_comments = []
negative_comments = []
neutral_comments = []
f = open("ytcomments.txt", 'r', encoding='`utf-8')
comments = f.readlines()
f.close()
print("Analysing Comments...")
for index, items in enumerate(comments):
polarity = sentiment_scores(items, polarity)
if polarity[-1] > 0.05:
positive_comments.append(items)
elif polarity[-1] < -0.05:
negative_comments.append(items)
else:
neutral_comments.append(items)
polarity[:5]
|
Output:
Analysing Comments...
[0.3612, 0.6486, 0.659, 0.4033, -0.8204]
Step 7: Overall Polarity
Average polarity is obtained by dividing the sum of polarity scores by the length of polarity list. If average polarity is greater than 0.05, the video is categorized as having a Positive response, if less than -0.05 has a negative response and if between -0.05 and +0.05 it is categorized as having a Neutral response.
Furthermore, the most positive and most negative response is printed along with the polarity score and length of comment.
Python3
avg_polarity = sum(polarity)/len(polarity)
print("Average Polarity:", avg_polarity)
if avg_polarity > 0.05:
print("The Video has got a Positive response")
elif avg_polarity < -0.05:
print("The Video has got a Negative response")
else:
print("The Video has got a Neutral response")
print("The comment with most positive sentiment:", comments[polarity.index(max(
polarity))], "with score", max(polarity), "and length", len(comments[polarity.index(max(polarity))]))
print("The comment with most negative sentiment:", comments[polarity.index(min(
polarity))], "with score", min(polarity), "and length", len(comments[polarity.index(min(polarity))]))
|
Output:
Average Polarity: 0.26831534954407277
The Video has got a Positive response
The comment with most positive sentiment: mission impossible, wow! this movie was absolutely mind-blowing! the plot was gripping and full of surprising twists that kept me hooked from start to finish. the ideas were incredibly creative, and i found myself eagerly anticipating each action-packed scene and thrilling moment.<br><br>the action sequences were spectacularly staged, leaving my heart racing with excitement. tom cruise delivered an impressive performance as the lead, bringing the characters to life in a remarkable way. his stunts were mind-blowing, and it was evident that he went above and beyond to provide the audience with an unforgettable experience.<br><br>the chemistry between the actors was palpable, and the ensemble complemented each other perfectly, making the story even more compelling. the dialogues were witty and clever, adding depth to the characters.<br><br>the filmmakers clearly put a lot of love into the details, creating stunning visual effects that immersed me in the world of the film. the set designs and cinematography were fantastic, making me feel like i was transported to an entirely new reality.<br><br>all in all, "mission impossible" was an action entertainment masterpiece that exceeded my expectations. i can't wait to see the second installment and experience even more of this thrilling adventure!
with score 0.9968 and length 1323
The comment with most negative sentiment: i cannot believe how bad paramount negotiated and promoted this movie!! i saw not a single poster of mi-7 in the theatre-. i went the first weekend of release (imax) and to my detriment only saw f... barbie everywhere!! but nothing of mi-7, not even a popcorn bag, plastic glasses or t-shirts. what a terrible mistake you have made with tom cruise's movie!! i am extremely angry and you have no right to complain about the terrible figures you are getting in the box office. ???????????? by the way, not everything is the usa. you did not promote this movie in latin america or other countries. shame on you once again.
with score -0.9923 and length 617
Plotting graphs
We will plot a bar chart to know, count of positive, negative and neutral comments visually.
- To get the count of positive, negative and neutral comments and store them in positive_count, negative_count and neutral_count respectively.
- Then we make labels for the chart and storing respective counts in comments_counts list. Using bar function in matplotlib.pyplot we are giving 3 parameters, the labels, counts and the respective colors of each bar.
- Next, we are setting labels for x and y axis using xlabel and ylabel functions, and title with title function
- Finally, we are displaying the plot using show() function.
Python3
positive_count = len(positive_comments)
negative_count = len(negative_comments)
neutral_count = len(neutral_comments)
labels = ['Positive', 'Negative', 'Neutral']
comment_counts = [positive_count, negative_count, neutral_count]
plt.bar(labels, comment_counts, color=['blue', 'red', 'grey'])
plt.xlabel('Sentiment')
plt.ylabel('Comment Count')
plt.title('Sentiment Analysis of Comments')
plt.show()
|
Output:
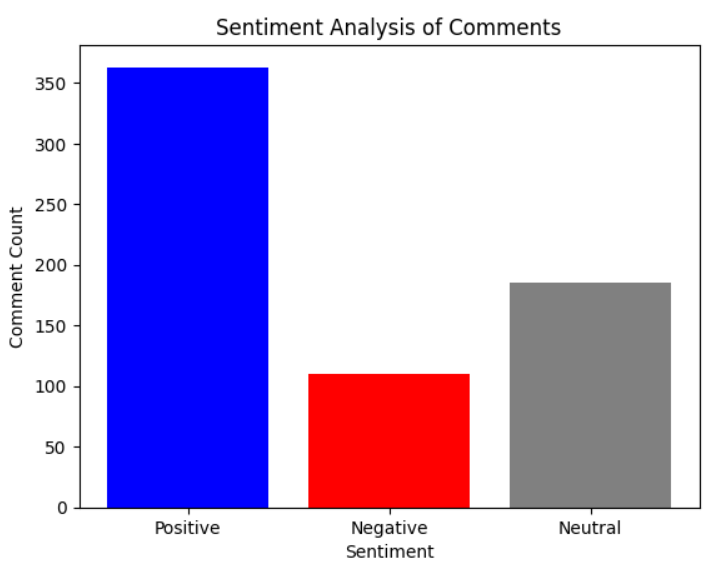
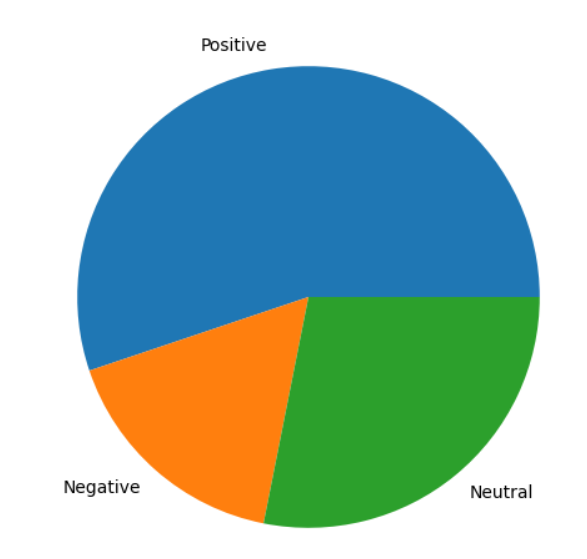
- We can also plot a pie chart for the same chart using the following code in which first we are setting the size of figure using figure() function and figsize parameter that sets the dimensions in inches, setting it as 10 inchs wide and 6 inches in height.
- Then using pie( ) function, we are plotting pie chart using count of respective comments and labels as parameters.
Python3
labels = ['Positive', 'Negative', 'Neutral']
comment_counts = [positive_count, negative_count, neutral_count]
plt.figure(figsize=(10, 6))
plt.pie(comment_counts, labels=labels)
plt.show()
|
Output:
Conclusion
In conclusion, our journey through the fascinating world of YouTube comment analysis has shed light on the immense power of data-driven insights in understanding the dynamic and diverse landscape of online interactions. By harnessing the capabilities of data scraping APIs, we were able to collect a wealth of comments from the platform. Through careful filtration, we ensured that our analysis focused on the most relevant and representative data.
Our application of sentiment analysis algorithms allowed us to delve deeper into the emotional undercurrents of these comments. You can now, scrape the data of any video and perform sentimental analysis.
Happy Experimenting!
Share your thoughts in the comments
Please Login to comment...