Read And Write Tabular Data using Pandas
Last Updated :
05 Feb, 2024
Pandas is a Python package providing fast, flexible, and expressive data structures designed to make working with “relational” or “labeled” data both easy and intuitive. It aims to be the fundamental, high-level building block for doing practical, real-world data analysis in Python.
The two primary data structures of Pandas, Series (1-dimensional) and DataFrame (2-dimensional), handle the vast majority of typical use cases in finance, statistics, social science, and many areas of engineering. For R users, DataFrame provides everything about R’s data.frame provides, and much more. Pandas is built on top of NumPy and is intended to integrate well within a scientific computing environment with many other third-party libraries.
Data structures
|
Dimension
|
Name
|
Description
|
|
1
|
Series
|
1D-labeled homogeneously-typed array
|
|
2
|
DataFrame
|
General 2D labeled, size-mutable tabular structure with potentially heterogeneously-typed column
|
Reading Tabular Data
Pandas provides the read_csv() function to read data stored as a csv file into a pandas DataFrame. pandas supports many different file formats or data sources out of the box (csv, excel, sql, json, parquet, …), each of them with the prefix read_*.
Importing Necessary libraries
CSV file
dataset.csv
1. Reading the csv file
Dataset link : dataset.csv
Python
data = pd.read_csv('dataset.csv')
print(data.head())
|
Output:
total_bill tip sex smoker day time size
0 16.99 1.01 Female No Sun Dinner 2
1 10.34 1.66 Male No Sun Dinner 3
2 21.01 3.50 Male No Sun Dinner 3
3 23.68 3.31 Male No Sun Dinner 2
4 24.59 3.61 Female No Sun Dinner 4
2. Reading excel file
Dataset link : data.xlsx
Python
data = pd.read_excel('data.xlsx')
print(data.head())
|
Output:
Column1 Column2 Column3
0 1 A 10.5
1 2 B 20.3
2 3 C 15.8
3 4 D 8.2
Writing Tabular Data
1. Writing in Excel file
Python
data = pd.read_csv('dataset.csv')
excel_file_path = 'newDataset.xlsx'
data.to_excel(excel_file_path, index=False)
print(f'Data written to Excel file: {excel_file_path}')
|
Output:
Data written to Excel file: newDataset.xlsx
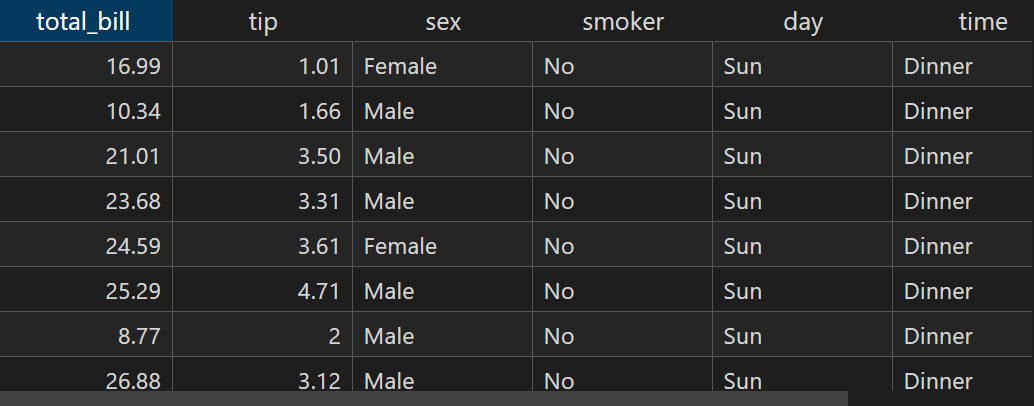
newDataset.xlsx
2. Writing in CSV file
Python
data = pd.read_csv('dataset.csv')
csv_file_path = 'newDataset.csv'
data.to_csv(csv_file_path, index=False)
print(f'Data written to CSV file: {csv_file_path}')
|
Output:
Data written to CSV file: newDataset.csv
Conclusion
In conclusion, Pandas provides essential tools for efficiently managing tabular data, allowing seamless reading and writing operations across various file formats. The library’s key functions, such as read_csv, read_excel, to_csv, and to_excel, facilitate the smooth import and export of data, irrespective of its original format.
Pandas’ adaptability extends to diverse data scenarios, enabling users to address nuances like missing values and customizable parameters. Whether dealing with CSV, Excel, SQL, JSON, or other file types, Pandas offers a consistent and user-friendly interface for data manipulation.
Share your thoughts in the comments
Please Login to comment...