Using csv module to read the data in Pandas
Last Updated :
05 Aug, 2021
The so-called CSV (Comma Separated Values) format is the most common import and export format for spreadsheets and databases. There were various formats of CSV until its standardization. The lack of a well-defined standard means that subtle differences often exist in the data produced and consumed by different applications. These differences can make it annoying to process CSV files from multiple sources. For that purpose, we will use Python’s csv library to read and write tabular data in CSV format.
For link to the CSV file used in the code click here.
Code #1: We will use csv.DictReader() function to import the data file into the Python’s environment.
Python3
import csv
with open('auto-mpg.csv') as csvfile:
mpg_data = list(csv.DictReader(csvfile))
print(mpg_data[:3])
|
Output :
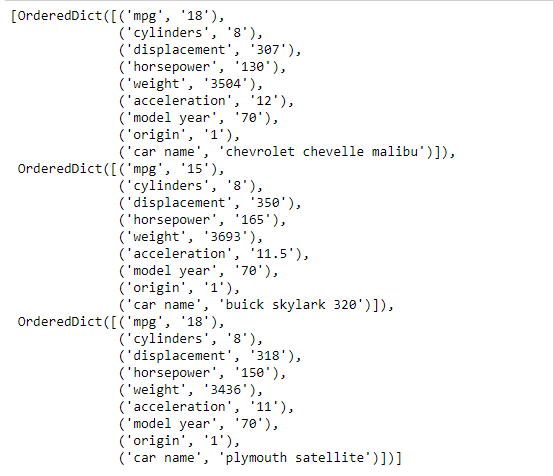
As we can see the data is stored as a list of ordered dictionary. Let’s perform some operations on the data for better understanding.
Code #2:
Python3
print(mpg_data[0].keys)
unique_cyl = set(data['cylinders'] for data in mpg_data)
print(unique_cyl)
|
Output :
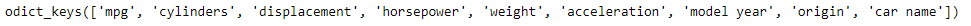
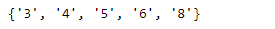
As we can see in the output, we have 5 unique values of cylinders in our dataset.
Code #3: Now let’s find out the value of average mpg for each value of cylinders.
Python3
avg_mpg = []
for c in unique_cyl:
mpgbycyl = 0
cylcount = 0
for x in mpg_data:
if x['cylinders']== c:
mpgbycyl += float(x['mpg'])
cylcount += 1
avg = mpgbycyl/cylcount
avg_mpg.append((c, avg))
avg_mpg.sort(key = lambda x : x[0])
print(avg_mpg)
|
Output :
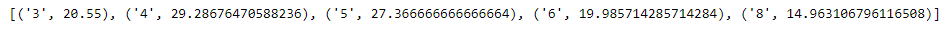
As we can see in the output, the program has successfully returned a list of tuples containing the average mpg for each unique cylinder type in our dataset.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...