Query HIVE table in Pyspark
Last Updated :
05 Jun, 2023
Hadoop Distributed File System (HDFS) is a distributed file system that provides high-throughput access to application data. In this article, we will learn how to create and query a HIVE table using Apache Spark, which is an open-source distributed computing system that is used to process large amounts of data in Python.
Query HIVE Table in Pyspark
Apache Hive is a data warehousing system built on top of Hadoop. It allows users to query and analyze large datasets stored in Hadoop-distributed file systems (HDFS) using SQL-like queries. We will create a Hive table, that is similar to a table in a traditional database, where data is stored in rows and columns. Let us see how we can Query a Hive table in PySpark.
Creating and Inserting Values into the Hive Table
We will use HiveQL language for querying the Hive table in PySpark.
The Syntax for Creating a Hive Table
CREATE TABLE IF NOT EXISTS table1 (id INT, name STRING, age INT)
We have created a table named “table1” with three columns: “id”, “name”, and “age”. We also specified the data types of each column and the file format used to store the table’s data.
The Syntax for Inserting Values into the Hive Table
We insert the values into the table “table1” using the following syntax.
INSERT INTO TABLE table1
VALUES (1, 'John', 28),
(2, 'Jane', 32),
(3, 'Michael', 25);
Syntax to display the Hive table:
To display the table we may either use the SQL query
SELECT * FROM table1
or use the spark function
df = spark.read.table("table1")
df.show()
Example:
In this example, we create a table name ’employees’ and added 5 rows into it using the spark.sql() function and passed the SQL query into it. Then we used the spark.read.table() function to read the database into a variable ‘df’ and display it using the show() function.
Python3
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName(
"HiveQuery").enableHiveSupport().getOrCreate()
spark.sql("CREATE TABLE IF NOT EXISTS employees
(id INT, name STRING, age INT, sales_amt INT,
city STRING, state STRING)")
spark.sql("INSERT INTO TABLE employees VALUES
(1, 'John', 28, 100, 'LA', 'CA'),
(2, 'Jane', 32, 200, 'NY', 'NY'),
(3, 'David', 45, 150, 'LA', 'CA'),
(4, 'Lisa', 23, 300, 'NY', 'NY'),
(5, 'Mike', 38, 250, 'SF', 'CA')")
df = spark.read.table("employees")
df.show()
|
Output:
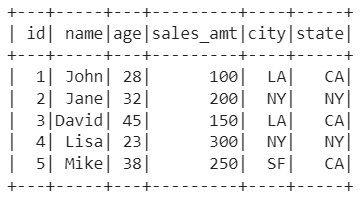
employees table
Filtering Data
Sometimes we don’t need all the rows of the database instead require some specific rows based on some criteria. We can filter such rows by writing simple HiveQL queries. Let us see a few examples of the same.
Example: Retrieve the name and age of employees who are older than 35
In this example, we will use the previously created table to retrieve the rows of only those employees whose age is greater than 35 years, using the WHERE clause.
Python3
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName(
"HiveQuery").enableHiveSupport().getOrCreate()
result = spark.sql("SELECT name, age FROM employees WHERE age > 35")
result.show()
|
Output:
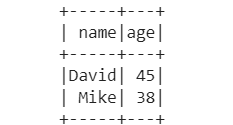
employees whose age is greater than 35
Example: Calculate the total sales amount for each state
In this example, we used the SUM() function and passed the ‘sales_amt’ to calculate the total sum. Then we grouped the data using the GROUP BY clause.
Python3
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName(
"HiveQuery").enableHiveSupport().getOrCreate()
result = spark.sql(
"SELECT state, SUM(amount) as total_sales FROM sales GROUP BY state")
result.show()
|
Output:

total sales from each state
Example: Retrieve the names of customers from California who live in Los Angeles
In this example, we used the AND along with WHERE to provide multiple conditions.
Python3
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName(
"HiveQuery").enableHiveSupport().getOrCreate()
result = spark.sql("SELECT name FROM customers WHERE state='CA' AND city='LA'")
result.show()
|
Output:
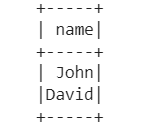
employees from CA and LA
Share your thoughts in the comments
Please Login to comment...