How to read hive partitioned table via pyspark
Last Updated :
16 Oct, 2023
Hive is built on Apache Hadoop and employments a high-level association and inquiry dialect called HiveQL (comparative to SQL) to recover large-scale information put away in disseminated capacity frameworks such as the Hadoop Dispersed Record Framework “HDFS”.
In this article, we will learn how to read a Hive Partitioned Table using Pyspark.
Reading Hive Partitioned Table using Pyspark
A Hive table could be a logical representation of organized information put away within the Apache Hive information distribution center framework. Before reading the hive-partitioned table using Pyspark, we need to have a hive-partitioned table.
Let us see the process of creating and reading a Hive Partitioned Table using Pyspark in Python.
Create a Hive Partitioned Table
First, let us create a hive-partitioned table.
Step 1: Import modules
Import the necessary modules that are required to create a hive table in Pyspark.
from pyspark.sql import SparkSession
Step 2: Create a SparkSession
Create a SparkSession with Hive support enabled using the enableHiveSupport() method.
spark = SparkSession.builder.enableHiveSupport().getOrCreate()
Step 3: Create a database (if it doesn’t already exist)
Define the sample data as a Python list of tuples. Create a DataFrame using the sample data and specify the column names.
data = [("John", 25, "Male"), ("Alice", 30, "Female"),]
df = spark.createDataFrame(data, ["Name", "Age", "Gender"])
Step 4: Create a partitioned table and save it
Now, create a partitioned hive table of the DataFrame using ‘write.partitionBy()‘ function which takes the column name as the parameter based on which we want to partition the hive table. Then save the table using ‘saveAsTable()‘ function that takes the table name as the parameter.
table_name = "tablename"
df.write.partitionBy("column_name").saveAsTable(table_name)
Step 5: Display the Partitioned Hive Table
df.show()
Example:
In this example, we start by importing the SparkSession class from the pyspark.sql module. We then created the SparkSession and define a sample DataFrame ‘df' with a larger dataset. It contains three columns: “Name”, “Age”, and “Gender”.
Python3
from pyspark.sql import SparkSession
spark = SparkSession.builder.enableHiveSupport().getOrCreate()
data = [
("John", 25, "Male"),
("Alice", 30, "Female"),
("Bob", 27, "Male"),
("Emma", 28, "Female"),
("David", 32, "Male"),
("Sophia", 29, "Female"),
("James", 31, "Male"),
("Olivia", 26, "Female"),
("Ethan", 33, "Male"),
("Isabella", 27, "Female")
]
df = spark.createDataFrame(data, ["Name", "Age", "Gender"])
table_name = "my_partitioned"
df.write.partitionBy("Gender").saveAsTable(table_name)
df.show()
|
Output:
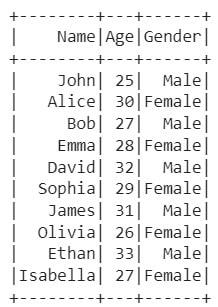
Partitioned Hive Table
Show the Hive Table Partitions
We can use the ‘spark.sql()' function to execute a SQL query. It takes the SQL query as a parameter value. The query is as follows:
"SHOW PARTITIONS table_name"
which retrieves the list of partitions for the Hive table.
Python3
spark.sql("SHOW PARTITIONS {}".format(table_name)).show()
|
Output:

Hive Table Partitions
Read Hive Partitions from the Table
To read a hive partitioned table, we will use the spark.sql() function to execute a SQL query. The query is as follows:
"SELECT * FROM tablename WHERE condition"
which selects all columns (*) from the Hive table where the condition is true for that particular row. The result is stored in the specific_partitions_df DataFrame.
Example: Reading single Partition of the hive table
In this example, we will read a single hive partition from the table. We will display the partitioned table where the gender is Male.
Python3
specific_partitions_df = spark.sql(
"SELECT * FROM {} WHERE Gender = 'Male'".format(table_name))
specific_partitions_df.show()
|
Output:
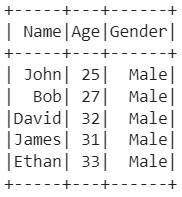
Reading Specific partition of Hive Table
Example: Reading multiple partitions of the hive table.
In this example, we will read multiple hive partitions from the table. We will display the partitioned table where the gender is Male as well as Female.
Python3
multiple_partitions_df = spark.sql(
"SELECT * FROM {} WHERE Gender IN ('Male', 'Female')".format(table_name))
multiple_partitions_df.show()
|
Output:
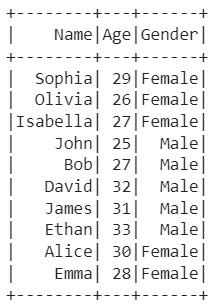
Reading multiple partition of hive table
Share your thoughts in the comments
Please Login to comment...