Python Web Scraping Tutorial
Last Updated :
15 Apr, 2024
Web scraping, the process of extracting data from websites, has emerged as a powerful technique to gather information from the vast expanse of the internet. In this tutorial, we’ll explore various Python libraries and modules commonly used for web scraping and delve into why Python 3 is the preferred choice for this task.
The latest version of Python, offers a rich set of tools and libraries specifically designed for web scraping, making it easier than ever to retrieve data from the web efficiently and effectively.
Requests Module
The requests library is used for making HTTP requests to a specific URL and returns the response. Python requests provide inbuilt functionalities for managing both the request and response.
pip install requests
Example: Making a Request
Python requests module has several built-in methods to make HTTP requests to specified URI using GET, POST, PUT, PATCH, or HEAD requests. A HTTP request is meant to either retrieve data from a specified URI or to push data to a server. It works as a request-response protocol between a client and a server. Here we will be using the GET request. The GET method is used to retrieve information from the given server using a given URI. The GET method sends the encoded user information appended to the page request.
Python3
import requests
print(r)
print(r.content)
|
Output

For more information, refer to our Python Requests Tutorial.
BeautifulSoup Library
Beautiful Soup provides a few simple methods and Pythonic phrases for guiding, searching, and changing a parse tree: a toolkit for studying a document and removing what you need. It doesn’t take much code to document an application.
Beautiful Soup automatically converts incoming records to Unicode and outgoing forms to UTF-8. You don’t have to think about encodings unless the document doesn’t define an encoding, and Beautiful Soup can’t catch one. Then you just have to choose the original encoding. Beautiful Soup sits on top of famous Python parsers like LXML and HTML, allowing you to try different parsing strategies or trade speed for flexibility.
pip install beautifulsoup4
Example
- Importing Libraries: The code imports the requests library for making HTTP requests and the BeautifulSoup class from the bs4 library for parsing HTML.
- Making a GET Request: It sends a GET request to ‘https://www.geeksforgeeks.org/python-programming-language/’ and stores the response in the variable r.
- Checking Status Code: It prints the status code of the response, typically 200 for success.
- Parsing the HTML: The HTML content of the response is parsed using BeautifulSoup and stored in the variable soup.
- Printing the Prettified HTML: It prints the prettified version of the parsed HTML content for readability and analysis.
Python3
import requests
from bs4 import BeautifulSoup
print(r)
soup = BeautifulSoup(r.content, 'html.parser')
print(soup.prettify())
|
Output

Finding Elements by Class
Now, we would like to extract some useful data from the HTML content. The soup object contains all the data in the nested structure which could be programmatically extracted. The website we want to scrape contains a lot of text so now let’s scrape all those content. First, let’s inspect the webpage we want to scrape.

In the above image, we can see that all the content of the page is under the div with class entry-content. We will use the find class. This class will find the given tag with the given attribute. In our case, it will find all the div having class as entry-content.
We can see that the content of the page is under the <p> tag. Now we have to find all the p tags present in this class. We can use the find_all class of the BeautifulSoup.
Python3
import requests
from bs4 import BeautifulSoup
soup = BeautifulSoup(r.content, 'html.parser')
s = soup.find('div', class_='entry-content')
content = s.find_all('p')
print(content)
|
Output:

For more information, refer to our Python BeautifulSoup.
Selenium
Selenium is a popular Python module used for automating web browsers. It allows developers to control web browsers programmatically, enabling tasks such as web scraping, automated testing, and web application interaction. Selenium supports various web browsers, including Chrome, Firefox, Safari, and Edge, making it a versatile tool for browser automation.
Example 1: For Firefox
In this specific example, we’re directing the browser to the Google search page with the query parameter “geeksforgeeks”. The browser will load this page, and we can then proceed to interact with it programmatically using Selenium. This interaction could involve tasks like extracting search results, clicking on links, or scraping specific content from the page.
Python3
from selenium import webdriver
driver = webdriver.Firefox()
|
Output

Example 2: For Chrome
- We import the webdriver module from the Selenium library.
- We specify the path to the web driver executable. You need to download the appropriate driver for your browser and provide the path to it. In this example, we’re using the Chrome driver.
- We create a new instance of the web browser using webdriver.Chrome() and pass the path to the Chrome driver executable as an argument.
- We navigate to a webpage by calling the get() method on the browser object and passing the URL of the webpage.
- We extract information from the webpage using various methods provided by Selenium. In this example, we retrieve the page title using the title attribute of the browser object.
- Finally, we close the browser using the quit() method.
Python3
from selenium import webdriver
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
element_list = []
for page in range(1, 3, 1):
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.get(page_url)
title = driver.find_elements(By.CLASS_NAME, "title")
price = driver.find_elements(By.CLASS_NAME, "price")
description = driver.find_elements(By.CLASS_NAME, "description")
rating = driver.find_elements(By.CLASS_NAME, "ratings")
for i in range(len(title)):
element_list.append([title[i].text, price[i].text, description[i].text, rating[i].text])
print(element_list)
driver.close()
|
Output
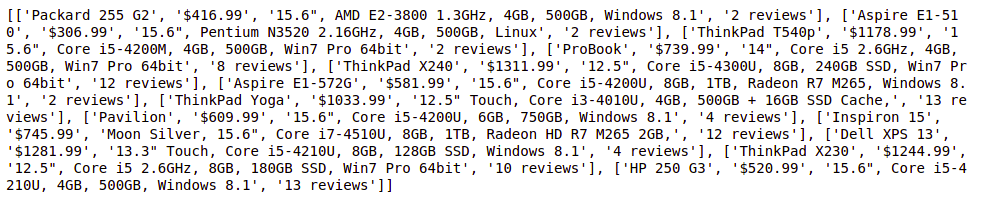
For more information, refer to our Python Selenium.
Lxml
The lxml module in Python is a powerful library for processing XML and HTML documents. It provides a high-performance XML and HTML parsing capabilities along with a simple and Pythonic API. lxml is widely used in Python web scraping due to its speed, flexibility, and ease of use.
pip install lxml
Example
Here’s a simple example demonstrating how to use the lxml module for Python web scraping:
- We import the html module from lxml along with the requests module for sending HTTP requests.
- We define the URL of the website we want to scrape.
- We send an HTTP GET request to the website using the requests.get() function and retrieve the HTML content of the page.
- We parse the HTML content using the html.fromstring() function from lxml, which returns an HTML element tree.
- We use XPath expressions to extract specific elements from the HTML tree. In this case, we’re extracting the text content of all the <a> (anchor) elements on the page.
- We iterate over the extracted link titles and print them out.
Python3
from lxml import html
import requests
response = requests.get(url)
tree = html.fromstring(response.content)
link_titles = tree.xpath('//a/text()')
for title in link_titles:
print(title)
|
Output
More information...
Urllib Module
The urllib module in Python is a built-in library that provides functions for working with URLs. It allows you to interact with web pages by fetching URLs (Uniform Resource Locators), opening and reading data from them, and performing other URL-related tasks like encoding and parsing. Urllib is a package that collects several modules for working with URLs, such as:
- urllib.request for opening and reading.
- urllib.parse for parsing URLs
- urllib.error for the exceptions raised
- urllib.robotparser for parsing robot.txt files
If urllib is not present in your environment, execute the below code to install it.
pip install urllib3
Example
Here’s a simple example demonstrating how to use the urllib module to fetch the content of a web page:
- We define the URL of the web page we want to fetch.
- We use urllib.request.urlopen() function to open the URL and obtain a response object.
- We read the content of the response object using the read() method.
- Since the content is returned as bytes, we decode it to a string using the decode() method with ‘utf-8’ encoding.
- Finally, we print the HTML content of the web page.
Python3
import urllib.request
try:
response = urllib.request.urlopen(url)
data = response.read()
html_content = data.decode('utf-8')
print(html_content)
except Exception as e:
print("Error fetching URL:", e)
|
Output

PyautoGUI
The pyautogui module in Python is a cross-platform GUI automation library that enables developers to control the mouse and keyboard to automate tasks. While it’s not specifically designed for web scraping, it can be used in conjunction with other web scraping libraries like Selenium to interact with web pages that require user input or simulate human actions.
pip3 install pyautogui
Example
In this example, pyautogui is used to perform scrolling and take a screenshot of the search results page obtained by typing a query into the search input field and clicking the search button using Selenium.
Python3
import pyautogui
pyautogui.moveTo(519, 1060, duration = 1)
pyautogui.click()
pyautogui.moveTo(1717, 352, duration = 1)
pyautogui.click()
|
Output

Schedule
The schedule module in Python is a simple library that allows you to schedule Python functions to run at specified intervals. It’s particularly useful in web scraping in Python when you need to regularly scrape data from a website at predefined intervals, such as hourly, daily, or weekly.
Example
- We import the necessary modules: schedule, time, requests, and BeautifulSoup from the bs4 package.
- We define a function scrape_data() that performs the web scraping task. Inside this function, we send a GET request to a website (replace ‘https://example.com’ with the URL of the website you want to scrape), parse the HTML content using BeautifulSoup, extract the desired data, and print it.
- We schedule the scrape_data() function to run every hour using schedule.every().hour.do(scrape_data).
- We enter a main loop that continuously checks for pending scheduled tasks using schedule.run_pending() and sleeps for 1 second between iterations to prevent the loop from consuming too much CPU.
Python3
import schedule
import time
def func():
print("Geeksforgeeks")
schedule.every(1).minutes.do(func)
while True:
schedule.run_pending()
time.sleep(1)
|
Output

Why Python3 for Web Scraping?
Python’s popularity for web scraping stems from several factors:
- Ease of Use: Python’s clean and readable syntax makes it easy to understand and write code, even for beginners. This simplicity accelerates the development process and reduces the learning curve for web scraping tasks.
- Rich Ecosystem: Python boasts a vast ecosystem of libraries and frameworks tailored for web scraping. Libraries like BeautifulSoup, Scrapy, and Requests simplify the process of parsing HTML, making data extraction a breeze.
- Versatility: Python is a versatile language that can be used for a wide range of tasks beyond web scraping. Its flexibility allows developers to integrate web scraping seamlessly into larger projects, such as data analysis, machine learning, or web development.
- Community Support: Python has a large and active community of developers who contribute to its libraries and provide support through forums, tutorials, and documentation. This wealth of resources ensures that developers have access to assistance and guidance when tackling web scraping challenges.
Share your thoughts in the comments
Please Login to comment...