Python | Tools in the world of Web Scraping
Last Updated :
01 Apr, 2024
Web page scraping can be done using multiple tools or using different frameworks in Python. There are variety of options available for scraping data from a web page, each suiting different needs. First, let’s understand the difference between web-scraping and web-crawling. Web crawling is used to index the information on the page using bots also known as Crawlers. On the other hand, Web-scraping is an automated way of extracting the information/content using bots also known as Scrapers. Let see some most commonly used web Scraping tools for Python3 :
- Urllib2
- Requests
- BeautifulSoup
- Lxml
- Selenium
- MechanicalSoup
Among all the available frameworks/ tools, only urllib2 come pre-installed with Python. So all other tools need to be installed, if needed. Let’s discuss all these tools in detail.
1. Urllib2 : Urllib2 is a python module used for fetching URL’s. It offers a very simple interface, in the form of urlopen function, which is capable of fetching URL’s using different protocols like HTTP, FTP etc.
Note:
The urllib2 library was a Python library that provided a simple interface for making HTTP requests.
This library has been deprecated in favor of the more feature-rich requests library, which offers a more intuitive and user-friendly interface.
Python
# Using urllib2 module
from urllib.request import urlopen
html = urlopen("http://geeksforgeeks.org")
print(html.read())
Output :
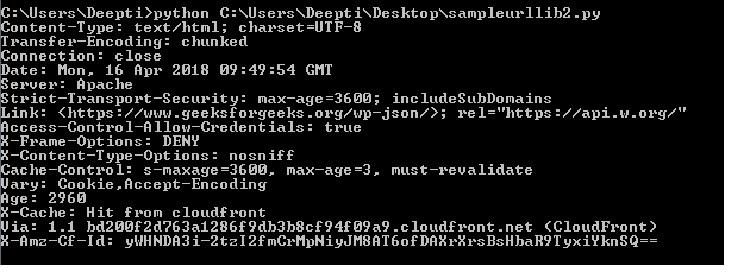
2. Requests : Requests does not come pre-installed with Python. Requests allows to send HTTP/1.1 requests. One can add headers, form data, multipart files and parameters with simple Python dictionaries and access the response data in the same way. Installing requests can be done using pip.
pip install requests
Python3
# Using requests module
import requests
# get URL
req = requests.get('https://www.geeksforgeeks.org/')
print(req.encoding)
print(req.status_code)
print(req.elapsed)
print(req.url)
print(req.history)
print(req.headers['Content-Type'])
Output :
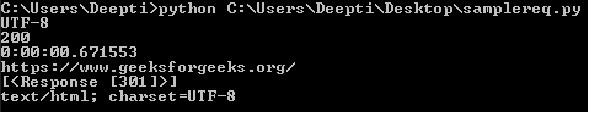
3. BeautifulSoup : Beautiful soup is a parsing library that can use different parsers. Beautiful Soup’s default parser comes from Python’s standard library. It creates a parse tree that can be used to extract data from HTML; a toolkit for dissecting a document and extracting what you need. It automatically converts incoming documents to Unicode and outgoing documents to UTF-8. pip can be used to install BeautifulSoup :
pip install beautifulsoup4
Python
# importing BeautifulSoup form
# bs4 module
from bs4 import BeautifulSoup
# importing requests
import requests
# get URL
r = requests.get("https://www.geeksforgeeks.org")
data = r.text
soup = BeautifulSoup(data)
for link in soup.find_all('a'):
print(link.get('href'))
Output :
.jpg)
4. Lxml : Lxml is a high-performance, production-quality HTML and XML parsing library. If the user need speed, then go for Lxml. Lxml has many modules and one of the module is etree , which is responsible for creating elements and structure using these elements. One can start using lxml by installing it as a python package using pip tool :
pip install lxml
Python
# importing etree from lxml module
from lxml import etree
root_elem = etree.Element('html')
etree.SubElement(root_elem, 'head')
etree.SubElement(root_elem, 'title')
etree.SubElement(root_elem, 'body')
print(etree.tostring(root_elem, pretty_print = True).decode("utf-8"))
Output :
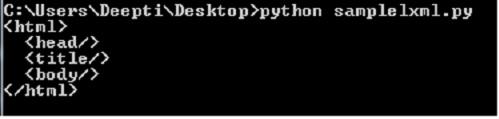
5. Selenium : Some websites use javascript to serve content. For example, they might wait until you scroll down on the page or click a button before loading certain content. For these websites, selenium is needed. Selenium is a tool that automates browsers, also known as web-drivers. It also comes with Python bindings for controlling it right from your application. pip package is used to install selenium :
pip install selenium
Python
# importing webdriver from selenium module
from selenium import webdriver
# path for chromedriver
path_to_chromedriver ='/Users/Admin/Desktop/chromedriver'
browser = webdriver.Chrome(executable_path = path_to_chromedriver)
url = 'https://www.geeksforgeeks.org'
browser.get(url)
Output :


6. MechanicalSoup : MechanicalSoup is a Python library for automating interaction with websites. It automatically stores and sends cookies, follows redirects, and can follow links and submit forms. It doesn’t do JavaScript. One can use following command to install MechanicalSoup :
pip install MechanicalSoup
Python
# importing mechanicalsoup
import mechanicalsoup
browser = mechanicalsoup.StatefulBrowser()
value = browser.open("http://geeksforgeeks.org/")
print(value)
value1 = browser.get_url()
print(value1)
value2 = browser.follow_link("forms")
print(value2)
value = browser.get_url()
print(value)
7. Scrapy : Scrapy is an open source and collaborative web crawling framework for extracting the data needed from websites. It was originally designed for web scraping. It can be used to manage requests, preserve user sessions follow redirects and handle output pipelines. There are 2-methods to install scrapy :
Using pip :
pip install scrapy
Using Anaconda : First install Anaconda or Miniconda and then use following command to install scrapy :
conda install -c conda-forge scrapy
Above discussed module are most commonly used scrapers for Python3. Although there are few more but no longer compatible with Python3 like Mechanize, Scrapemark.
References :
- https://elitedatascience.com/python-web-scraping-libraries
- https://python.gotrained.com/python-web-scraping-libraries/
- http://blog.datahut.co/beginners-guide-to-web-scraping-with-python-lxml/
Share your thoughts in the comments
Please Login to comment...