Python | Pandas Series.str.count()
Last Updated :
15 Nov, 2022
Python is a great language for doing data analysis, primarily because of the fantastic ecosystem of data-centric Python packages. Pandas is one of those packages and makes importing and analyzing data much easier. Pandas str.count() method is used to count occurrence of a string or regex pattern in each string of a series. Additional flags arguments can also be passed to handle to modify some aspects of regex like case sensitivity, multi line matching etc. Since this is a pandas string method, it’s only applicable on Series of strings and .str has to be prefixed every time before calling this method. Otherwise, it will give an error.
Syntax: Series.str.count(pat, flags=0) Parameters: pat: String or regex to be searched in the strings present in series flags: Regex flags that can be passed (A, S, L, M, I, X), default is 0 which means None. For this regex module (re) has to be imported too. Return type: Series with count of occurrence of passed characters in each string.
To download the CSV used in code, click here. In the following examples, the data frame used contains data of some NBA players. The image of data frame before any operations is attached below. 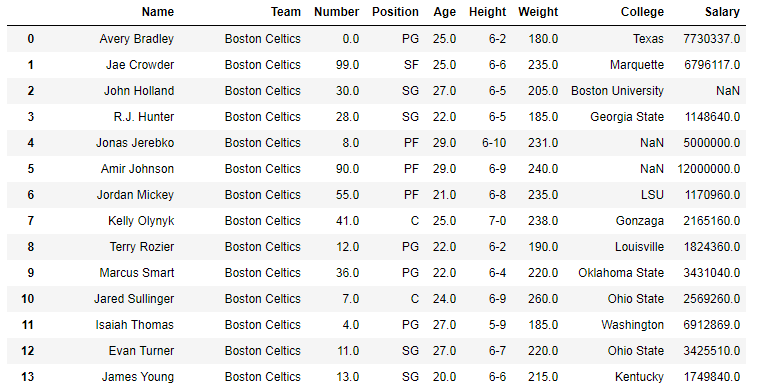 Example #1: Counting word occurrence In this example, a Pandas series is made from a list and occurrence of gfg is counted using str.count() method.
Example #1: Counting word occurrence In this example, a Pandas series is made from a list and occurrence of gfg is counted using str.count() method.
Python3
import pandas as pd
list =["GeeksforGeeks", "Geeksforgeeks", "geeksforgeeks",
"geeksforgeeks is a great platform", "for tech geeks"]
series = pd.Series(list)
count = series.str.count("geeks")
count
|
Output: As shown in the output image, the occurrence of geeks in each string was displayed and Geeks wasn’t counted due to first upper case letter.  Example #2: Using Flags In this example, occurrence of “a” is counted in the Name column. The flag parameter is also used and re.I is passed to it, which means IGNORECASE. Hence, a and A both will be considered during count.
Example #2: Using Flags In this example, occurrence of “a” is counted in the Name column. The flag parameter is also used and re.I is passed to it, which means IGNORECASE. Hence, a and A both will be considered during count.
Python3
import pandas as pd
import re
data = pd.read_csv("https://media.geeksforgeeks.org/wp-content/uploads/nba.csv")
search ="a"
data["count"]= data["Name"].str.count(search, re.I)
data
|
Output: As shown in the output image, it can be clearly compared by looking at the first index itself, the count for a in Avery Bradley is 2, which means both upper case and lower case was considered. 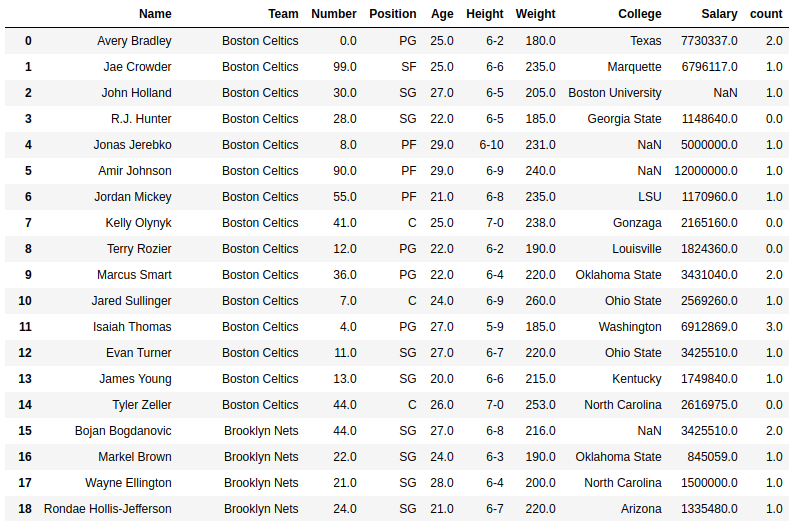
Share your thoughts in the comments
Please Login to comment...