Project Idea | Domain term detection and Hierarchical concept creation
Last Updated :
28 Feb, 2023
Project Title: Domain term detection and Hierarchical concept creation Introduction: Domain Term Detection and Hierarchical Concept Creation in which given set of documents, main aims is to identify domain-specific term which mean that from given large set articles, tried to extract the domain for each article, and also created hierarchical representation of concept and further cluster documents under those concept. Through this anyone can search like if searched found to be domain as Economy from article then It will have Economy as parent node and under economy it can have its child and then so on, means If searched keyword is Economy then which is important keyword then related word for Economy like inflation, goods which all comes under Economy as if it follows the parent-child relation. Features Provided
- Automatic extraction of Keywords.
- Automatic determination of either extracted keyword is Noun, Pronoun and many more.
- Relation Extraction.
- Automatic checking of word sense disambiguation.
- A user can Cluster the Keyword in the different cluster.
- Maintaining the tree-like structure of the parent-child relation of a keyword.
Flowchart: 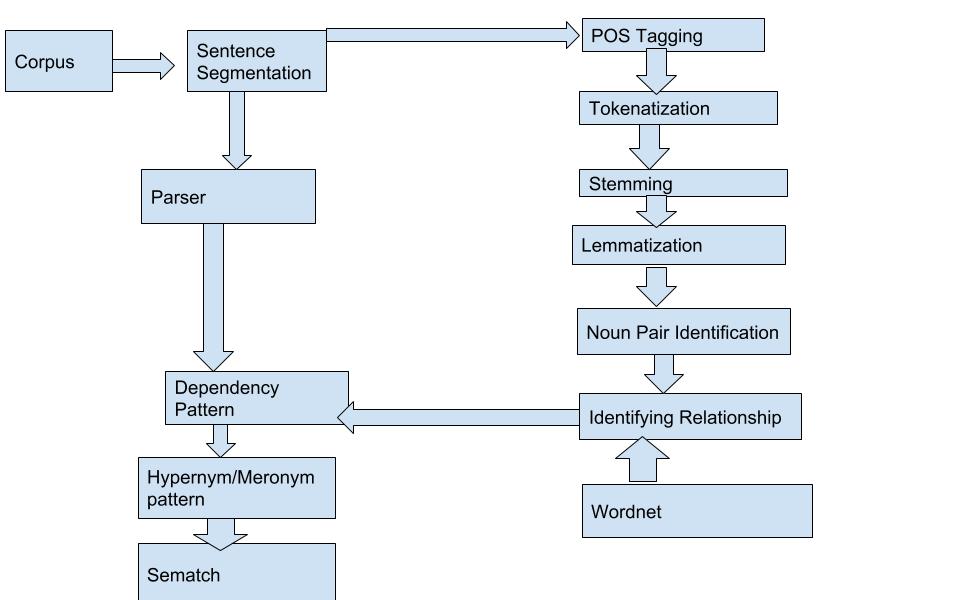 Data structures and Algorithms
Data structures and Algorithms
- Data pre-processing: tokenization
- Stop words
- Entity extraction
- LDA(Latent Dirichlet allocation)
- Guided LDA(Laten Dirichlet allocation)
- Stemming and Lemmatizing.
- Feature extraction: vectorizing the data using TI_IDF Vectorizer(Term Frequency and Inverse Frequency Domain).
- Dimensionality Reduction using LSA(Latent Semantic Analysis)
- Clustering the Latent Vector.
- Density-Based Spatial Clustering of Application with noise (DBSCAN)
- K-means clustering.
Tools Used: Sparql database, Python, Jupyternotebook, StandfordcoreNLP, Data visualization Library used.
- Sematch -compares word similarity It has Wordnet, DBPedia, YOGO based similarity algorithm.
- Hypernym and Meronym – Library which is used to extract the proper noun from the given text.
- Pydot-used to create a downward hierarchy of the given keyword like a tree.
- Pandas-used to read the CSV file.
- Seaborn.
- Matplotlib library
Working. Applied NLP (Natural Languages Processing ) for this project First of all collected all the articles of newspaper from online and then applied various algorithm because as it is known that all the text taken is basically unstructured and known that it won’t fit into a model of unstructured text so for that applied various algorithm to make structured. As we know that if anyone tries to find in google like Economy the from that related keyword also appears, basically which follow the parent-child relationship in the top to downward hierarchy. So the user can easily know that if the searched keyword is Economy the user can identical meaning of words in a tree manner which is quite efficient. The user can easily detect the main important keyword from a given set of text. A user can easily find out the part of speech(pos) from given get of the word only they will provide the sentence and the user will get the pos automatically. A user can easily see the cluster of the same kind of word. A user can store the information on the SPARQL database. Important Point What I found after recursive approach. After reading many about Wordnet I noticed the most important point that Wordnet is limited in scope and also time-consuming. WordNet has no concept of probability. WordNet stores a list of its relations to other words but does not store the probability of the occurrence of that relationship in normal usage. Note: This project idea is contributed by Shwetabh Shekhar for ProGeek Cup 2.0- A project competition by GeeksforGeeks.
Share your thoughts in the comments
Please Login to comment...