Pandas – Multi-index and Groupby Tutorial
Last Updated :
21 Mar, 2024
Multi-index and Groupby are very important concepts of data manipulation. Multi-index allows you to represent data with multi-levels of indexing, creating a hierarchy in rows and columns.
Groupby lets you create groups of similar data and apply aggregate functions (e.g., mean, sum, count, standard deviation) to each group, condensing large datasets into meaningful summaries.
Using both these tools together allows you to analyze data from a different aspect.
In this article, we will discuss Multi-index for Pandas Dataframe and Groupby operations.
Multi-index in Python Pandas
Multi-index allows you to select more than one row and column in your index.
It is a multi-level or hierarchical object for Pandas object.
We can use various methods of multi-index such as MultiIndex.from_arrays(), MultiIndex.from_tuples(), MultiIndex.from_product(), MultiIndex.from_frame, etc., which helps us to create multiple indexes from arrays, tuples, DataFrame, etc.
Syntax
pandas.MultiIndex(levels=None, codes=None, sortorder=None, names=None, dtype=None, copy=False, name=None, verify_integrity=True)
Parameters
- levels: It is a sequence of arrays that shows the unique labels for each level.
- codes: It is also a sequence of arrays where integers at each level help us to designate the labels in that location.
- sortorder: optional int. It helps us to sort the levels lexicographically.
- dtype:data-type(size of the data which can be of 32 bits or 64 bits)
- copy: It is a boolean type parameter with a default value of False. It helps us to copy the metadata.
- verify_integrity: It is a boolean type parameter with a default value of True. It checks the integrity of the levels and codes i.t if they are valid.
Let us see some examples to understand the concept better.
Example 1: Creating multi-index from arrays
After importing all the important Python libraries, we are creating an array of names along with arrays of marks and age respectively.
Now with the help of MultiIndex.from_arrays, we are combining all three arrays such that elements from all three arrays form multiple indexes together. After that, we show the above result.
Python3
# importing pandas library from
# python
import pandas as pd
# Creating an array of names
arrays = ['Sohom','Suresh','kumkum','subrata']
# Creating an array of ages
age= [10, 11, 12, 13]
# Creating an array of marks
marks=[90,92,23,64]
# Using MultiIndex.from_arrays, we are
# combining the arrays together along
# with their names and creating multi-index
# with each element from the 3 arrays into
# different rows
multi_index = pd.MultiIndex.from_arrays([arrays,age,marks], names=('names', 'age','marks'))
# Showing the above data
print(multi_index)
Output:

Example 2: Creating multi-index from DataFrame using Pandas.
In this example, we are doing the same thing as the previous example. We created a DataFrame using pd.DataFrame and after that, we created multi-index from that DataFrame using multi-index.from_frame() along with the names.
Python3
# importing pandas library from
# python
import pandas as pd
# Creating data
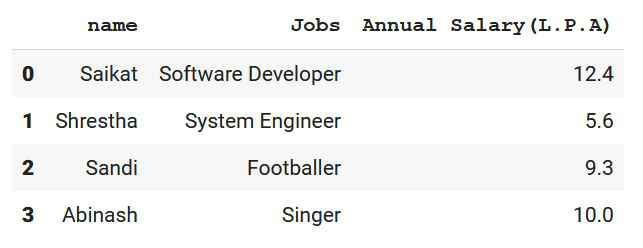
Information = {'name': ["Saikat", "Shrestha", "Sandi", "Abinash"],
'Jobs': ["Software Developer", "System Engineer",
"Footballer", "Singer"],
'Annual Salary(L.P.A)': [12.4, 5.6, 9.3, 10]}
# Dataframing the whole data
df = pd.DataFrame(dict)
# Showing the above data
print(df)
Output:
Now using MultiIndex.from_frame(), we are creating multiple indexes with this DataFrame.
Python3
# creating multiple indexes from
# the dataframe
pd.MultiIndex.from_frame(df)
Output:

Example 3:Using DataFrame.set_index([col1,col2,..])
After importing the Pandas library, we created data and then converted it into tabular form with the help of pandas.DataFrame.
After that using Dataframe.set_index we are setting some columns as the index columns(Multi-Index).
The drop parameter is kept as false which will not drop the columns mentioned as index columns and thereafter append parameter is used for appending passed columns to the already existing index columns.
Python3
# importing the pandas library
import pandas as pd
# making data for dataframing
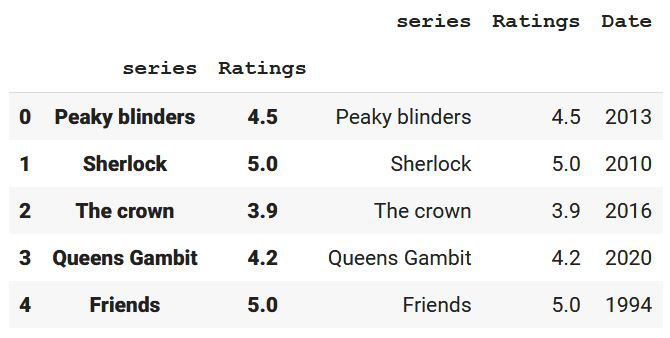
data = {
'series': ['Peaky blinders', 'Sherlock', 'The crown',
'Queens Gambit', 'Friends'],
'Ratings': [4.5, 5, 3.9, 4.2, 5],
'Date': [2013, 2010, 2016, 2020, 1994]
}
# Dataframing the whole data created
df = pd.DataFrame(data)
# setting first and the second name
# as index column
df.set_index(["series", "Ratings"], inplace=True,
append=True, drop=False)
# display the dataframe
print(df)
Output:
Now, we are printing the index of DataFrame in the form of a multi-index.
Python3
Output:

GroupBy in Python Pandas
A groupby operation in Pandas helps us to split the object by applying a function and there-after combine the results.
After grouping the columns according to our choice, we can perform various operations which can eventually help us in the analysis of the data.
Syntax
DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=<object object>, observed=False, dropna=True)
Parameter
- by: It helps us to group by specific or multiple columns in the DataFrame.
- axis: It has a default value of 0 where 0 stands for index and 1 stands for columns.
- level: Let us consider that the DataFrame we are working with has hierarchical indexing. In that case, level helps us to determine the level of the index we are working with.
- as_index: It is a boolean data type with a default value of true. It returns an object with group labels as the index.
- sort: It helps us to sort the key values. It is preferable to keep it as false for better performance.
- group_keys: It is also a boolean value with a default value of true. It adds group keys to indexes to identify pieces
- dropna: It helps to drop the ‘NA‘ values in a dataset
Example 1: Using Groupby with DataFrame
First, let’s create a DataFrame on which we will perform the groupby operation.
Python3
# importing pandas library
import numpy as np
# Creating pandas dataframe
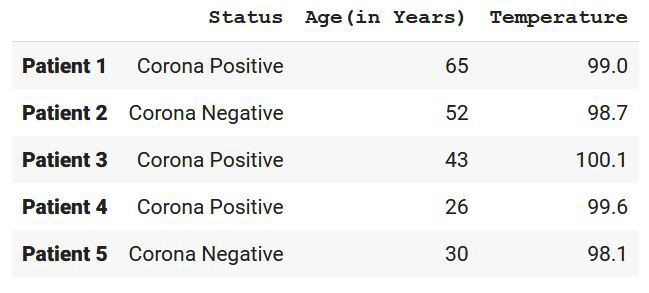
df = pd.DataFrame(
[
("Corona Positive", 65, 99),
("Corona Negative", 52, 98.7),
("Corona Positive", 43, 100.1),
("Corona Positive", 26, 99.6),
("Corona Negative", 30, 98.1),
],
index=["Patient 1", "Patient 2", "Patient 3",
"Patient 4", "Patient 5"],
columns=("Status", "Age(in Years)", "Temperature"),
)
# show dataframe
print(df)
Output:
Now let us group them according to some features:
Python3
# Grouping with only status
grouped1 = df.groupby("Status")
# Grouping with temperature and status
grouped3 = df.groupby(["Temperature", "Status"])
As we can see, we have grouped them according to ‘Status‘ and ‘Temperature and Status‘. Let us perform some functions now:
Example: Finding the mean of a Group
This will create the mean of the numerical values according to the ‘status’.
Python3
# Finding the mean of the
# patients reports according to
# the status
grouped1.mean()
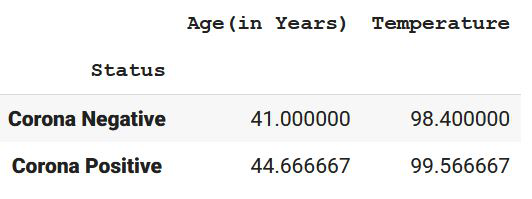
Conclusion
We have covered the concept of Multi index and groupby in Pandas Python in this tutorial. Both these concepts are very crucial in data manipulation while doing data analysis.
Multi-index allows you to create a hierarchal structure in your data structure, while groupby allows you to group similar data to perform analysis on it.
Using both these techniques together will help in better data presentation and provide you with some unseen insights, increasing the quality of your data analysis project.
Share your thoughts in the comments
Please Login to comment...