CatBoost is a high-performance, open-source gradient boosting library developed by Yandex, a Russian multinational IT company. It is designed for categorical feature support, making it particularly powerful for structured data like those often encountered in real-world datasets. In this article, we will explore CatBoost in detail, from understanding how it works to performing binary classification using a real-world dataset.
What is CatBoost
CatBoost stands for “Categorical Boosting,” and it is a machine learning algorithm that falls under the gradient boosting framework. As its name suggests, CatBoost has two main features, it works with categorical data and it uses gradient-boosting algorithms for inferences. Gradient boosting is an ensemble technique that combines the predictions from multiple weak learners (typically decision trees) to create a strong predictive model. What sets CatBoost apart is its ability to handle categorical features efficiently, without the need for preprocessing, and its strong performance out of the box.
How CatBoost Works
To increase gradient boosting’s precision and effectiveness, CatBoost employs a variety of strategies, such as feature engineering, decision tree optimization, and an innovative algorithm known as ordered boosting. CatBoost computes the loss function’s negative gradient in relation to the current predictions at every algorithm iteration. Next, by appending a scaled version of the gradient to the existing predictions, we utilize this gradient to update the predictions. An approach based on line search that minimizes the loss function is used to determine the scaling factor.
Using a method known as gradient-based optimization, CatBoost constructs the decision trees by fitting the trees to the negative gradient of the loss function. Predictions made using this method are more accurate since the trees are able to concentrate on the areas of feature space that have the biggest effects on the loss function. Lastly, ordered boosting, a brand-new technique introduced by CatBoost, permutes the features in a certain order to optimize the learning objective function. Particularly for data sets with a lot of features, this method can lead to faster convergence and improved model correctness.
CatBoost Parameters
Lets dicuss few import parameter in CatBoost model:
- learning_rate: This parameter controls the step size or the rate at which the model updates its predictions during each boosting iteration. A smaller learning rate leads to slower convergence but can help the model generalize better. A common range for learning rates is between 0.01 and 0.3.
- iterations: It specifies the number of boosting iterations or trees to build. Each iteration adds a new tree to the ensemble, and the model’s predictions are updated based on the combined predictions of all the trees. Increasing the number of iterations may improve the model’s performance but can also lead to overfitting.
- depth: This parameter sets the maximum depth of the individual trees in the ensemble. A deeper tree can capture more complex patterns but may also lead to overfitting. You should experiment with different depth values to find the optimal balance between model complexity and performance.
- loss_function: The loss_function parameter allows you to specify the loss function used to optimize the model during training. CatBoost supports a variety of loss functions, including ‘Logloss’ (binary classification), ‘RMSE’ (regression), and custom loss functions that you can define based on your specific problem.
- custom_metric: You can use this parameter to specify custom evaluation metrics that are not available in the default set of metrics provided by CatBoost. For example, if you have a specific metric that’s important for your problem, you can define it here for model evaluation.
- l2_leaf_reg: L2 regularisation term applied to leaf values. It helps control the smoothness of the learned leaf values. Higher values of l2_leaf_reg lead to smoother leaf values, which can prevent overfitting.
- max_leaves: This parameter specifies the maximum number of leaves (terminal nodes) in each tree. Limiting the maximum number of leaves can help control the complexity of individual trees and reduce overfitting.
Implementation Binary classification using CatBoost
To get started with CatBoost, we typically need to define a problem (classification or regression), prepare the data, create a CatBoost model, train the model, and use it to make predictions.
Define a problem :
The code example provided is a binary classification problem. Specifically, it’s aimed at predicting whether a passenger survived (1) or did not survive (0) based on various features provided in the dataset. The problem can be summarised as follows:
Problem Type: Binary Classification
Target Variable:
- 0: The did not survive
- 1: The passenger survived
We use sns.load_dataset to load the titanic dataset.
Installing necessary libraries
!pip install catboost
Importing necessary libraries
Python3
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
from catboost import CatBoostClassifier
|
The pandas, matplotlib, seaborn, numpy, and catBoost libraries are imported in this code sample in order to facilitate data analysis and machine learning. The methodology for data analysis and classification is common and includes the following steps: dividing the data into training and testing sets; training a CatBoost classifier; assessing the model’s accuracy; generating a confusion matrix and classification report; and using Seaborn to visualize the confusion matrix.
Loading Dataset
Python3
titanic = sns.load_dataset('titanic')
target = 'survived'
|
This code loads the built-in Seaborn dataset, which is the Titanic dataset. It describes the machine learning task’s target variable, “survived.”
Preparing Data
Python3
categories = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'Unknown']
titanic['deck'] = pd.Categorical(
titanic['deck'], categories=categories, ordered=True)
titanic['deck'] = titanic['deck'].fillna('Unknown')
age_mean = titanic['age'].fillna(0).mean()
titanic['age'] = titanic['age'].fillna(age_mean)
titanic = titanic.dropna()
titanic = titanic.drop('alive', axis=1)
|
This code is a component of the Titanic dataset’s data preparation. The ‘deck’ column has missing values that are initially filled in by making a new category called ‘Unknown’ and assigning it to the missing data. The ‘deck’ column is also transformed into a category variable with predefined categories. Next, it computes the mean age and uses it for imputation to fill in the missing values in the ‘age’ column. From there, the code eliminates entries in the ’embark’ column that have missing values because there are only two of them. At last, it removes the ‘alive’ column from the dataset, presumably due to the fact that it is superfluous or adds complexity to the problem.
Creating CatBoost Pool object
Python3
X = titanic.drop(target, axis=1)
y = titanic[target]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
|
The Titanic dataset’s feature matrix (X) and target vector (y) are ready thanks to this code. It designates ‘survived’ to y and removes the ‘survived’ column to produce X. Next, utilizing a random seed for reproducibility, it divides the data into training and testing sets, allocating 80% of the data for training and 20% for testing.
Model Training
Python3
categorical_features = ['sex', 'pclass', 'sibsp', 'parch', 'embarked',
'class', 'who', 'adult_male', 'embark_town', 'alone', 'deck']
model = CatBoostClassifier(iterations=100, depth=8, learning_rate=0.1, cat_features=categorical_features,
loss_function='Logloss', custom_metric=['AUC'], random_seed=42)
model.fit(X_train, y_train)
|
Output:
0: learn: 0.6571312 total: 8.15ms remaining: 807ms
1: learn: 0.6221910 total: 15.5ms remaining: 761ms
2: learn: 0.5939753 total: 20.7ms remaining: 668ms
3: learn: 0.5702463 total: 39.9ms remaining: 958ms
4: learn: 0.5494485 total: 41.5ms remaining: 789ms
5: learn: 0.5318808 total: 46.7ms remaining: 731ms
6: learn: 0.5166735 total: 56.9ms remaining: 756ms
7: learn: 0.5034372 total: 58.3ms remaining: 671ms
8: learn: 0.4912526 total: 63.5ms remaining: 642ms
9: learn: 0.4836415 total: 64.4ms remaining: 580ms
10: learn: 0.4743785 total: 72.1ms remaining: 583ms
11: learn: 0.4658533 total: 74.8ms remaining: 548ms
12: learn: 0.4581934 total: 76.1ms remaining: 510ms
13: learn: 0.4502682 total: 79.6ms remaining: 489ms
14: learn: 0.4447627 total: 82.3ms remaining: 466ms
15: learn: 0.4418242 total: 83.8ms remaining: 440ms
16: learn: 0.4361839 total: 92ms remaining: 449ms
17: learn: 0.4321366 total: 105ms remaining: 479ms
18: learn: 0.4272143 total: 115ms remaining: 489ms
19: learn: 0.4222480 total: 121ms remaining: 485ms
20: learn: 0.4186428 total: 128ms remaining: 482ms
21: learn: 0.4160136 total: 131ms remaining: 464ms
22: learn: 0.4120392 total: 150ms remaining: 503ms
23: learn: 0.4084467 total: 159ms remaining: 503ms
24: learn: 0.4061321 total: 170ms remaining: 510ms
25: learn: 0.4032156 total: 186ms remaining: 530ms
26: learn: 0.4005279 total: 196ms remaining: 530ms
27: learn: 0.3976319 total: 208ms remaining: 534ms
28: learn: 0.3950018 total: 219ms remaining: 536ms
29: learn: 0.3924854 total: 230ms remaining: 536ms
30: learn: 0.3909029 total: 232ms remaining: 516ms
31: learn: 0.3882627 total: 243ms remaining: 517ms
32: learn: 0.3868289 total: 247ms remaining: 502ms
33: learn: 0.3846619 total: 258ms remaining: 500ms
34: learn: 0.3824924 total: 271ms remaining: 503ms
35: learn: 0.3803765 total: 281ms remaining: 500ms
36: learn: 0.3791884 total: 288ms remaining: 491ms
37: learn: 0.3784476 total: 294ms remaining: 479ms
38: learn: 0.3771794 total: 302ms remaining: 473ms
39: learn: 0.3756477 total: 307ms remaining: 460ms
40: learn: 0.3744917 total: 317ms remaining: 456ms
41: learn: 0.3731448 total: 331ms remaining: 457ms
42: learn: 0.3719157 total: 339ms remaining: 450ms
43: learn: 0.3712053 total: 341ms remaining: 434ms
44: learn: 0.3708579 total: 342ms remaining: 418ms
45: learn: 0.3696508 total: 349ms remaining: 409ms
46: learn: 0.3696123 total: 349ms remaining: 394ms
47: learn: 0.3681257 total: 366ms remaining: 397ms
48: learn: 0.3669725 total: 373ms remaining: 388ms
49: learn: 0.3659752 total: 379ms remaining: 379ms
50: learn: 0.3647252 total: 383ms remaining: 368ms
51: learn: 0.3643869 total: 385ms remaining: 355ms
52: learn: 0.3626816 total: 389ms remaining: 345ms
53: learn: 0.3612727 total: 393ms remaining: 335ms
54: learn: 0.3606969 total: 397ms remaining: 325ms
55: learn: 0.3595592 total: 401ms remaining: 315ms
56: learn: 0.3589548 total: 405ms remaining: 306ms
57: learn: 0.3579704 total: 409ms remaining: 296ms
58: learn: 0.3566358 total: 413ms remaining: 287ms
59: learn: 0.3544308 total: 417ms remaining: 278ms
60: learn: 0.3537146 total: 422ms remaining: 270ms
61: learn: 0.3532524 total: 426ms remaining: 261ms
62: learn: 0.3529038 total: 428ms remaining: 252ms
63: learn: 0.3522250 total: 432ms remaining: 243ms
64: learn: 0.3512260 total: 438ms remaining: 236ms
65: learn: 0.3512232 total: 439ms remaining: 226ms
66: learn: 0.3503927 total: 443ms remaining: 218ms
67: learn: 0.3493005 total: 448ms remaining: 211ms
68: learn: 0.3482276 total: 452ms remaining: 203ms
69: learn: 0.3473065 total: 456ms remaining: 195ms
70: learn: 0.3466746 total: 460ms remaining: 188ms
71: learn: 0.3453713 total: 464ms remaining: 180ms
72: learn: 0.3444596 total: 468ms remaining: 173ms
73: learn: 0.3438192 total: 472ms remaining: 166ms
74: learn: 0.3428437 total: 477ms remaining: 159ms
75: learn: 0.3419112 total: 481ms remaining: 152ms
76: learn: 0.3417966 total: 483ms remaining: 144ms
77: learn: 0.3414320 total: 487ms remaining: 137ms
78: learn: 0.3404628 total: 493ms remaining: 131ms
79: learn: 0.3397802 total: 497ms remaining: 124ms
80: learn: 0.3389843 total: 501ms remaining: 118ms
81: learn: 0.3381099 total: 505ms remaining: 111ms
82: learn: 0.3368774 total: 510ms remaining: 104ms
83: learn: 0.3359082 total: 514ms remaining: 97.8ms
84: learn: 0.3347115 total: 518ms remaining: 91.4ms
85: learn: 0.3336493 total: 522ms remaining: 85ms
86: learn: 0.3331264 total: 526ms remaining: 78.6ms
87: learn: 0.3330938 total: 527ms remaining: 71.9ms
88: learn: 0.3330462 total: 530ms remaining: 65.5ms
89: learn: 0.3327905 total: 534ms remaining: 59.4ms
90: learn: 0.3322902 total: 538ms remaining: 53.3ms
91: learn: 0.3312277 total: 542ms remaining: 47.2ms
92: learn: 0.3305716 total: 547ms remaining: 41.1ms
93: learn: 0.3301908 total: 551ms remaining: 35.2ms
94: learn: 0.3290290 total: 555ms remaining: 29.2ms
95: learn: 0.3281570 total: 564ms remaining: 23.5ms
96: learn: 0.3281198 total: 565ms remaining: 17.5ms
97: learn: 0.3280096 total: 569ms remaining: 11.6ms
98: learn: 0.3274169 total: 573ms remaining: 5.78ms
99: learn: 0.3268049 total: 576ms remaining: 0us
<catboost.core.CatBoostClassifier at 0x7f7cc569f130>
This code sample trains a CatBoostClassifier, a machine learning model created for handling categorical features, for a binary classification job. Initially, the categorical attributes in the dataset are specified in a list named categorical_features. Initialization of the CatBoostClassifier involves setting certain hyperparameters, such as learning rate of 0.1, tree depth of 8, and number of boosting iterations of 100. For binary classification tasks, the loss function “Logloss” is a suitable choice. To evaluate the performance of the model, a unique assessment metric called “AUC” (Area Under the ROC Curve) is established. To guarantee repeatability, a random seed of 42 is chosen. The model is then trained with the given training data (X_train and y_train), utilizing categorical feature handling and the defined hyperparameters.
Make predictions and Evaluate the Model
Python3
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
|
Output:
Accuracy: 0.80
This code uses the test data (X_test) and the trained CatBoostClassifier model to predict the target variable. Next, using the ground truth labels (y_test), it determines how accurate the model is at predicting outcomes. The accuracy score is printed by the code at the end to assess how well the model performed using the test set.
Confusion Matrix
Python3
plt.figure(figsize=(8, 6))
sns.heatmap(confusion, annot=True, fmt='d', cmap='Blues', xticklabels=[
'Predicted Negative', 'Predicted Positive'], yticklabels=['Actual Negative', 'Actual Positive'])
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.title('Confusion Matrix')
plt.show()
|
Output:
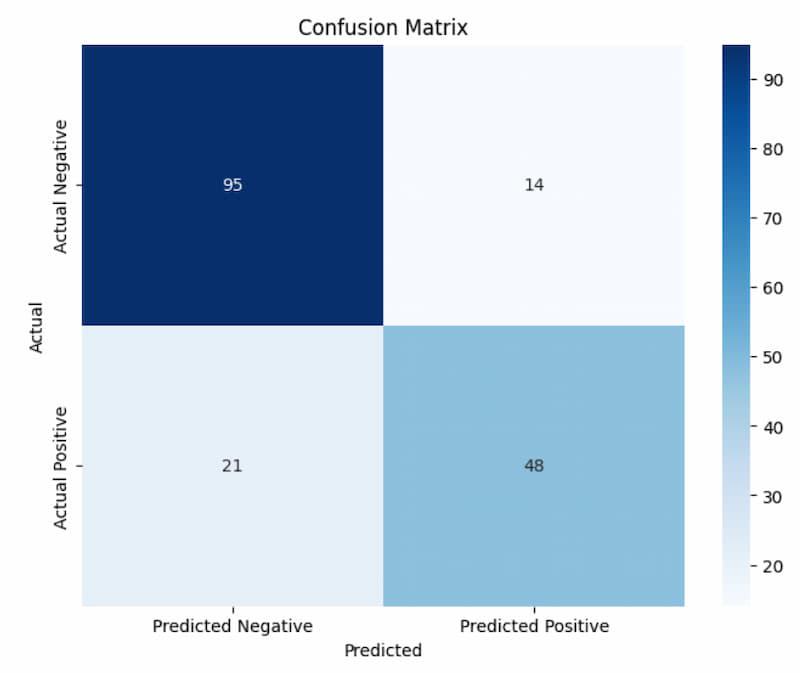
Confusion Matrix
With this code, a heatmap of the confusion matrix is produced in order to assess a classification model. Using a blue color map and annotations to show the values, it plots the confusion matrix (confusion) using the Seaborn library. The plot has a title for clarity, and the labels for the x and y ticks indicate the actual and expected classes.
Visualise Feature Importance
CatBoost provides us with the ability to visualise feature importance via .get_feature_importance method. This method helps us in feature engineering to add/drop new features.
Python3
importances = model.get_feature_importance()
feature_names = X.columns
sorted_indices = np.argsort(importances)[::-1]
plt.figure(figsize=(10, 6))
plt.bar(range(len(feature_names)), importances[sorted_indices])
plt.xticks(range(len(feature_names)), feature_names[sorted_indices], rotation=90)
plt.title("Feature Importance")
plt.show()
|
Output:
.jpg)
The feature importances for a trained CatBoostClassifier model are computed and displayed by this code. First, it uses model.get_feature_importance() to retrieve the feature importances from the model. The feature indices are then arranged in descending order of significance. Lastly, it generates a bar plot with the feature names on the x-axis and rotates them for reading to display the ordered feature importances. The storyline has the designation “Feature Importance.”
Classification Report
Python3
print("Classification Report:")
print(classification_report(y_test, y_pred))
|
Output:
Classification Report:
precision recall f1-score support
0 0.82 0.87 0.84 109
1 0.77 0.70 0.73 69
accuracy 0.80 178
macro avg 0.80 0.78 0.79 178
weighted avg 0.80 0.80 0.80 178
This code generates a text summary of the model’s performance measures, such as precision, recall, F1-score, and support for every class in the test data, and outputs it as the classification report. The output is shown in the terminal and is produced by the scikit-learn classification_report function. Details on the model’s performance on different classification-related fronts are provided in the report.
CatBoost Advantages and Disadvantages
Advantages:
- Predictive Performance: CatBoost often delivers better predictive accuracy compared to other gradient boosting algorithms, making it a powerful choice for various machine learning tasks.
- Categorical Feature Handling: CatBoost can efficiently handle categorical features without the need for extensive preprocessing, simplifying the feature engineering process and reducing the risk of data leakage.
- Robust to Overfitting: CatBoost incorporates techniques like ordered boosting and effectively controls overfitting by managing the depth of trees and the learning rate, improving the model’s generalization.
Disadvantages:
- Prediction Time: CatBoost can be slower during the prediction phase, especially when compared to simpler models like linear regression or decision trees. This can be a limitation in real-time applications where low latency is critical.
- Hyper-parameter Tuning Complexity: CatBoost has a range of hyperparameters that need to be carefully tuned for optimal model performance. The complexity of hyperparameter tuning can be challenging, particularly for users new to the algorithm.
- Resource Intensive: Training CatBoost models with a large number of trees or deep trees can be computationally intensive, and it may require significant memory and computational resources. This can be a limitation for users with limited resources or when working with large datasets.
Share your thoughts in the comments
Please Login to comment...