When it comes to machine learning, model performance depends heavily on feature selection and understanding the significance of each feature. LightGBM, an efficient gradient-boosting framework developed by Microsoft, has gained popularity for its speed and accuracy in handling various machine-learning tasks. LightGBM, with its remarkable speed and memory efficiency, finds practical application in a multitude of fields. Its ability to handle large-scale data processing efficiently makes it indispensable in industries like finance, e-commerce, and healthcare, where massive datasets require swift analysis.
What is LightGBM?
LightGBM, short for Light Gradient Boosting Machine, is a high-performance, distributed, and efficient gradient-boosting framework that focuses on tree-based learning algorithms. It was developed by Microsoft and is widely used for both classification and regression tasks. LightGBM is designed to be memory-efficient and highly optimized, making it a popular choice for machine learning practitioners.
Feature Importance
Feature importance is like your compass, guiding you through the labyrinth of data. By understanding which factors are steering your model’s predictions, you can make informed decisions about which features to prioritize, enhance model interpretability, and fine-tune your model for maximum performance. LightGBM doesn’t just offer feature importance; it offers it in two flavors, making it an even more potent tool.
Understanding LightGBM Feature Importance
LightGBM provides two main types of feature importance scores: “Split” and “Gain.”
- Split Feature Importance: This type measures the number of times a feature is used to split the data across all trees in the model. It is useful for identifying which features are most often involved in the decision-making process.
- Gain Feature Importance: Gain importance, on the other hand, quantifies the improvement in the model’s accuracy achieved by using a particular feature for splitting. It provides a more informative view of feature importance, as it considers the quality of the splits as well.
Choosing the right feature importance type depends on your specific problem and goals. If you want a quick overview of which features are used most often, “Split” importance is suitable. However, if you want a more informative and accurate measure of feature importance, “Gain” importance is recommended, as it considers the quality of splits.
Visualizing LightGBM Feature Importance
First, make sure you have LightGBM installed:
! pip install lightgbm
Let’s break down the provided code step by step:
Step 1: Import Libraries
In this step, we import the necessary libraries that the code will use:
- lightgbm for building the gradiant boosting framework
- matplotlib.pyplot for creating plots
- sklearn.datasets to import breast cancer dataset for classification
- train_test_split, numpy and pandas to perform data pre processing
Python3
import pandas as pd
import numpy as np
import lightgbm as lgb
import matplotlib.pyplot as plt
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
|
Step 2: Create a LightGBM Dataset
Here, a LightGBM dataset named train_data is created. This dataset is specifically formatted for training the LightGBM model. It is constructed using the following inputs:
- X_train: This variable is assumed to contain the training feature data (i.e., the independent variables).
- y_train: This variable is assumed to contain the corresponding target labels (i.e., the dependent variable or the values you want to predict).
Python3
cancer = load_breast_cancer()
df = pd.DataFrame(np.c_[cancer['data'], cancer['target']], columns = np.append(cancer['feature_names'], ['target']))
X = df.drop(['target'], axis =1)
y = df['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 0)
train_data = lgb.Dataset(X_train, label = y_train)
|
Step 3: Define Model Parameters
In this step, a dictionary named `params` is defined. This dictionary holds various configuration parameters that will be used to set up the LightGBM model. Here’s what each parameter means:
- objective specifies the objective of the model
- metric specifies the evaluation metric that the model should optimize during training
- boosting_type indicates the boosting type to be used in LightGBM. gbdt stands for Gradient Boosting Decision Trees, one of the boosting methods available in LightGBM.
These parameters define how the model will be trained and evaluated.
Python
params = {
"objective": "binary",
"metric": "binary_logloss",
"boosting_type": "gbdt",
"learning_rate" : 0.1
}
|
Step 4: Train the LightGBM Model
In this step, the LightGBM model is trained using the lgb.train function. Here’s what’s happening:
- params is the model configuration parameters defined earlier are passed as the first argument.
- train_data is LightGBM training dataset is provided as the second argument.
- num_boost_round=5 specifies the number of boosting rounds or iterations during training. The model is trained for 5 rounds, and each round involves adding a decision tree to the ensemble.
After this step, the model variable contains the trained LightGBM model.
Python3
model = lgb.train(params, train_data, num_boost_round=5)
|
Output:
[LightGBM] [Info] Number of positive: 249, number of negative: 149
[LightGBM] [Warning] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000248 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 3978
[LightGBM] [Info] Number of data points in the train set: 398, number of used features: 30
[LightGBM] [Info] [binary:BoostFromScore]: pavg=0.625628 -> initscore=0.513507
[LightGBM] [Info] Start training from score 0.513507
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
Step 5: Plot Feature Importance
Finally, the code visualizes the feature importance using the lgb.plot_importance function and Matplotlib. Here’s what each part of this step does:
- lgb.plot_importance(model, importance_type=”gain”, figsize=(7,6), title=”LightGBM Feature Importance (Gain)”) generates a feature importance plot based on the trained LightGBM model. It specifies the importance type as “gain,” which calculates feature importance based on the gain in accuracy achieved by using each feature for splitting in the decision trees. It also sets the figure size and provides a title for the plot.
- lgb.plot_importance(model, importance_type=”split”, figsize=(7, 6), title=”LightGBM Feature Importance (Split)”) creates a feature importance plot based on the ‘split’ metric. This metric measures how often a feature is used to split the data in decision trees during training, which helps assess the feature’s importance in making decisions.
Plot feature importance using Gain
Python3
lgb.plot_importance(model, importance_type="gain", figsize=(7,6), title="LightGBM Feature Importance (Gain)")
plt.show()
|
Output:
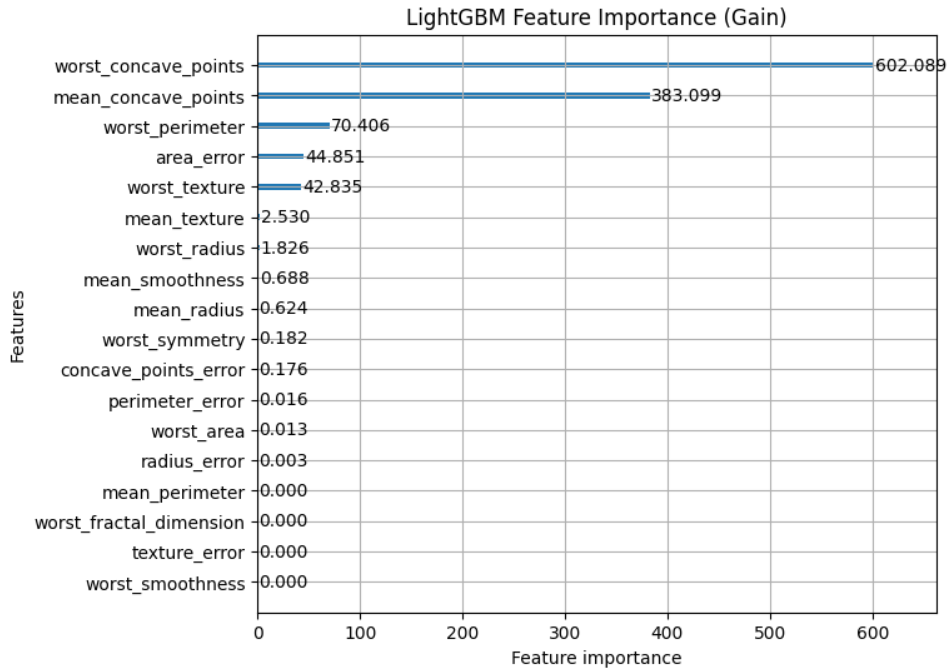
Gain Feature Importance Graph
Plot feature importance using Gain
Python3
lgb.plot_importance(model, importance_type="split", figsize=(7,6), title="LightGBM Feature Importance (Split)")
plt.show()
|
Output:
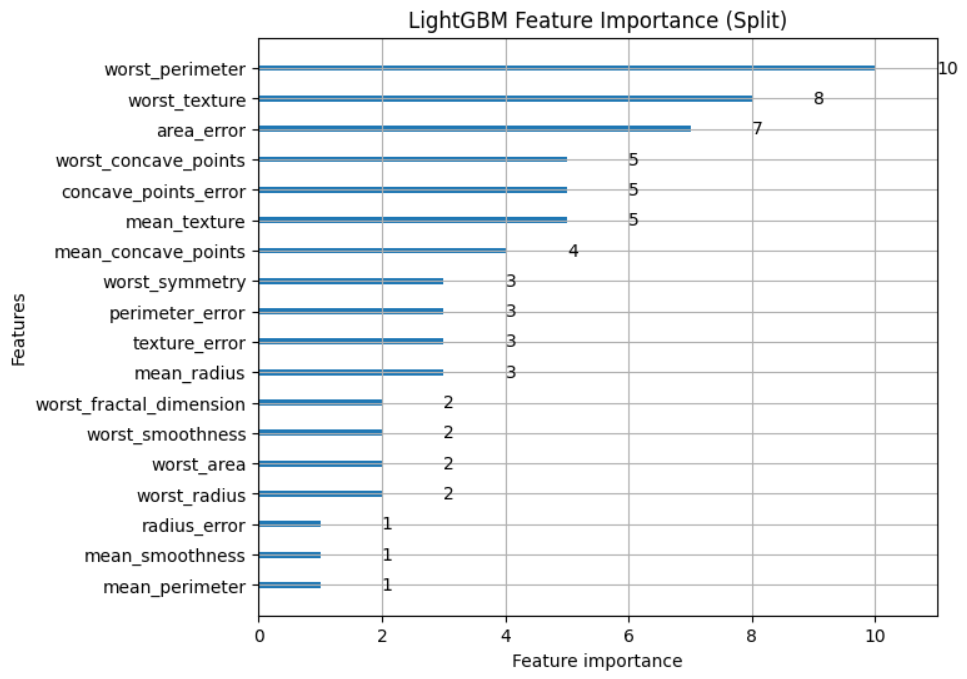
Split Feature Importance Graph
The resulting plot provides insights into which features were most influential in the LightGBM model’s predictions, helping in feature selection and model interpretation.
The code demonstrates the complete process of importing libraries, preparing a LightGBM dataset, defining model parameters, training a LightGBM regression model, and visualizing feature importance using the “gain” method.
Advantages of Using LightGBM
LightGBM offers several advantages for machine learning tasks:
- Speed: LightGBM is exceptionally fast and memory-efficient, making it suitable for large datasets.
- Accuracy: It often achieves state-of-the-art results in various machine learning competitions and real-world applications.
- Parallel and Distributed Training: LightGBM supports parallel and distributed training, enabling faster model development.
- Regularization: It provides built-in L1 and L2 regularization to prevent overfitting.
- Feature Importance: Comprehensive feature importance analysis helps in better model understanding and feature selection.
Additionally, LightGBM’s high prediction accuracy is highly sought after in applications such as fraud detection, credit scoring, and recommendation systems, where precision is paramount. In healthcare, LightGBM aids in disease prediction and patient risk stratification, while it excels in natural language processing tasks like sentiment analysis and text classification. Beyond these, it proves valuable in image classification, anomaly detection, and even optimizing search engine rankings. With its versatility and speed, LightGBM continues to make a significant impact across diverse domains and data-driven applications.
Conclusion
LightGBM’s feature importance tools provide valuable insights into your model’s behavior and help in making informed decisions. Effective visualization and interpretation of feature importance can be instrumental in model debugging, feature selection, and gaining a deeper understanding of your data.
Understanding and visualizing feature importance can greatly enhance your machine learning projects, and LightGBM’s speed and accuracy make it a valuable tool in your data science toolkit. However, it’s essential to be aware of multicollinearity and choose the appropriate type of feature importance for your specific problem to harness the full potential of LightGBM.
Happy modeling and interpreting!
Share your thoughts in the comments
Please Login to comment...