Introduction to XPath
Last Updated :
27 Oct, 2023
XPath(XML Path) is an expression that is used to find the element or say node in the XML document. In Selenium it is commonly used to find the web elements.
What is XPath?
XPath stands for XML Path Language. It’s an expression language that is used to query or transform. We use it to traverse among elements and attributes in an XML document. The World Wide Web Consortium (W3C) defined XPath in 1999.
XPath is used to:
- Query or transform XML documents
- Traverse elements, attributes, and text through an XML document
- Find particular elements or attributes with matching patterns
- Uniquely identify or address parts of an XML document
- Extract information from any part of an XML document
- Test addressed nodes within a document to determine whether they match a pattern
Syntax:
//tagname[@attribute = ‘value’]
XPath Expressions:
| // |
Selects nodes in the document from the current node that match the selection no matter where they are |
| / |
Selects the root node |
| tagname |
Tag name of the current node |
| @ |
Select the attribute |
| attribute |
Attribute name of the node |
| value |
Value of the attribute |
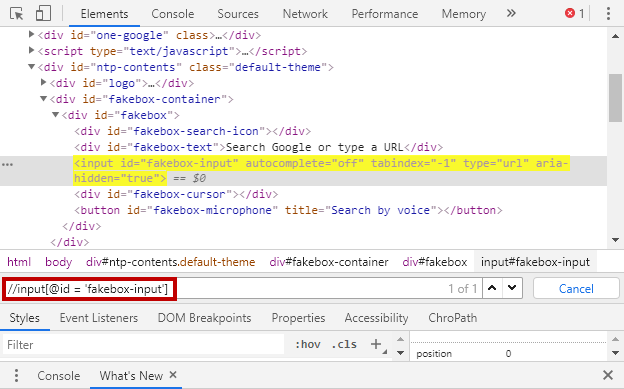
Example: In this example, We are locating the ‘input‘ element whose ‘id‘ is equal to ‘fakebox-input‘
//input[@id = 'fakebox-input']
 XML Code:
XML Code:
XML
<?xml version="1.0" encoding="UTF-8"?>
<bookstore>
<book category = "Math">
<title lang="en">IIT Mathematics</title>
<author>A Das Gupta</author>
</book>
<book category = "Chemistry">
<title lang="en"> Inorganic chemistry for JEE</title>
<author>V K Jaiswal</author>
</book>
</bookstore>
|
The XML Code is a tree like structure as we can see in the above XML, the code starts with the bookstore node that has a child node book and it is followed by an attribute category whose value is ‘Math’. The book node has 2 child node i.e. title and author. To select the author element of the chemistry book, the following XPath will be used:
/bookstore/book[@category='Chemistry']/author
Types of XPath:
- Absolute XPath
- Relative Xpath
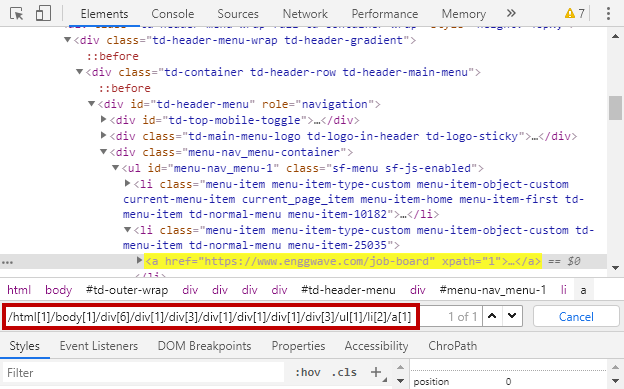
1. Absolute XPath: Absolute XPath uses the root element of the HTML/XML code and followed by all the elements which are necessary to reach the desired element. It starts with the forward slash ‘/’ . Generally, Absolute XPath is not recommended because in future any of the web element when added or removed then Absolute XPath changes.
Example:
/html[1]/body[1]/div[6]/div[1]/div[3]/div[1]/div[1]/div[1]/div[3]/ul[1]/li[2]/a[1]
2. Relative XPath; In this, XPath begins with the double forward slash ‘//’ which means it can search the element anywhere in the Webpage. Generally Relative Xpath is preferred as they are not complete path from Root node.
Example:
//input[@id = 'fakebox-input']
If you want to learn how to make XPath identify webelements, Then open the webpage in chrome browser and inspect the element by right click on the webpage and after that press ‘ctrl+f’ to find the webelements using XPath. You can also use the chrome extension like ‘chropath’ to find the xpath for a webelement. Commonly Used XPath Functions:
- contains()
- Start-With()
- Text()
1. contains(): This Function is used to select the node whose specified attribute value contains the specified string provided in the function argument.
Example:
//input[contains(@id, 'fakebox')]
 2. Starts-with(): This function is used to select the node whose specified attribute value starts with the specified string value provided in the function arguments.
2. Starts-with(): This function is used to select the node whose specified attribute value starts with the specified string value provided in the function arguments.
Example:
//input[starts-with(@id, 'fakebox')]
 3. text(): This function is used to find the node having the exact match with the specified string value in the function.
3. text(): This function is used to find the node having the exact match with the specified string value in the function.
Example:
//div
 Uses of AND and OR in XPath AND and OR are used to combine two or more conditions to find the node.
Uses of AND and OR in XPath AND and OR are used to combine two or more conditions to find the node.
Example:
//input[@value = 'Log In' or @type = 'submit']
 Similarly, We can apply AND operator in XPath.
Similarly, We can apply AND operator in XPath.
Share your thoughts in the comments
Please Login to comment...