What is Map Data Structure?
Map data structure (also known as a dictionary, associative array, or hash map) is defined as a data structure that stores a collection of key-value pairs, where each key is associated with a single value.
Maps provide an efficient way to store and retrieve data based on a unique identifier (the key).
Need for Map Data Structure
The map data structure, also known as a dictionary, is used to store a collection of key-value pairs. It is an essential data structure in computer science because it allows for efficient and fast lookups, inserts, and deletes.
Maps are widely used in many applications, including database indexing, network routing, and web programming. For example, in web programming, a map might be used to store a user’s preferences, where the keys are the preferred names and the values are the preference values. In this case, the map provides a convenient way to store and retrieve user preferences without having to search through a list or array.
Types of Maps in Data Structures:
There are several different types of maps or dictionary data structures used in computer science and data structures:
A hash map is a data structure that uses a hash function to map keys to indices in an array. The hash function takes the key as input and produces an index into the array, where the corresponding value is stored. Hash maps have an average time complexity of O(1) for operations such as insertion and retrieval, making them one of the most efficient map data structures. However, hash collisions can occur when two keys map to the same index, leading to slower performance in the worst case.
A tree map is a type of map that is implemented as a binary search tree. In a tree map, the keys are stored in a sorted order, allowing for efficient searching, insertion, and deletion operations. Tree maps have an average time complexity of O(log n) for operations such as insertion and retrieval, where n is the number of elements in the map.
A linked hash map is a type of map that maintains a doubly-linked list of the entries in the map, in the order in which they were inserted. This allows for fast iteration over the elements in the map, as well as efficient insertion, retrieval, and deletion operations.
A trie map, also known as a prefix tree, is a type of map that is used to store a set of strings, where each node in the tree represents a prefix of one or more strings. Tries are particularly useful for searching for strings that start with a given prefix, as the search can be terminated early once the prefix is not found in the trie.
A bloom filter map is a type of map that uses a bloom filter, a probabilistic data structure, to determine whether a key is present in the map or not. Bloom filter maps are used when it is important to have a fast response time for key existence checks, but where the occasional false positive result is acceptable.
Map Data Structure in Different Languages:
Maps are associative containers that store elements in a mapped fashion. Each element has a key value and a mapped value. No two mapped values can have the same key values.
Types of Maps in C++:
Syntax:
Order Map: map<int, int>mp
Unordered Map: unordered_map<int, int>mp
Multi map: multimap<int, int>mp
The map interface is present in java.util package represents a mapping between a key and a value. The Map interface is not a subtype of the Collection interface. Therefore it behaves a bit differently from the rest of the collection types.
Types of Maps in Java:
Syntax:
HashMap: Map<String, Integer> map = new HashMap<>();
Linked Hash Map: Map<String, Integer> map = new LinkedHashMap<>();
Tree Map: Map<String, Integer> map = new TreeMap<>();
map() function returns a map object(which is an iterator) of the results after applying the given function to each item of a given iterable (list, tuple etc.)
Syntax:
map(fun, iter)
The Dictionary<TKey, TValue> Class in C# is a collection of Keys and Values. It is a generic collection class in the System.Collections.Generic namespace. The Dictionary <TKey, TValue> generic class provides a mapping from a set of keys to a set of values. Each addition to the dictionary consists of a value and its associated key.
Dictionary<string, string> myDict =
new Dictionary<string, string>();
Map is a collection of elements where each element is stored as a Key, value pair. Map object can hold both objects and primitive values as either key or value. When we iterate over the map object it returns the key, value pair in the same order as inserted.
Syntax:
new Map([it])
Difference between Map, Set, and Array Data Structure:
| Features | Array | Set | Map |
|---|
| Duplicate values | Duplicate Values
| Unique Values
| keys are unique, but the values can be duplicated
|
|---|
| Order | Ordered Collection
| Unordered Collection
| Unordered Collection
|
|---|
| Size | Static
| Dynamic
| Dynamic
|
|---|
| Retrieval | Elements in an array can be accessed using their index
| Iterate over the set to retrieve the value.
| Elements can be retrieved using their key
|
|---|
| Operations | Adding, removing, and accessing elements
| Set operations like union, intersection, and difference.
| Maps are used for operations like adding, removing, and accessing key-value pairs.
|
|---|
| Memory | Stored as contiguous blocks of memory
| Implemented using linked lists or trees
| Implemented using linked lists or trees
|
|---|
Internal Implementation of Map Data Structure:
The Map data structure is a collection of key-value pairs that allows fast access to the values based on their corresponding keys. The internal implementation of the Map data structure depends on the programming language or library being used.
Map data structure is typically implemented as an associative array or hash table, which uses a hash function to compute a unique index for each key-value pair. This index is then used to store and retrieve the value associated with that key.
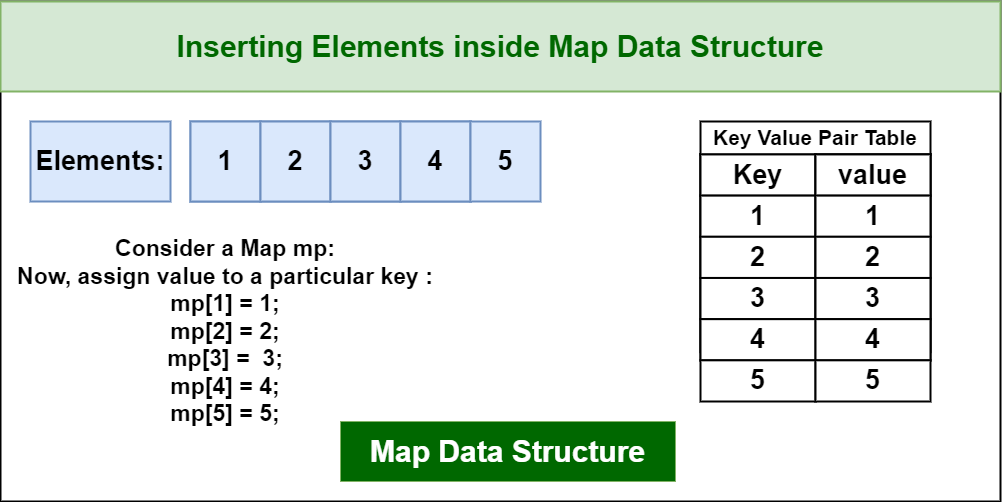
Map Data Structure
When a new key-value pair is added to the Map, the hash function is applied to the key to compute its index, and the value is stored at that index. If there is already a value stored at that index, then the new value replaces the old one.
1. Ordered Map
In C++, an ordered map is implemented using the std::map container provided in the Standard Template Library (STL). The std::map is a templated container that stores key-value pairs in a sorted order based on the keys.
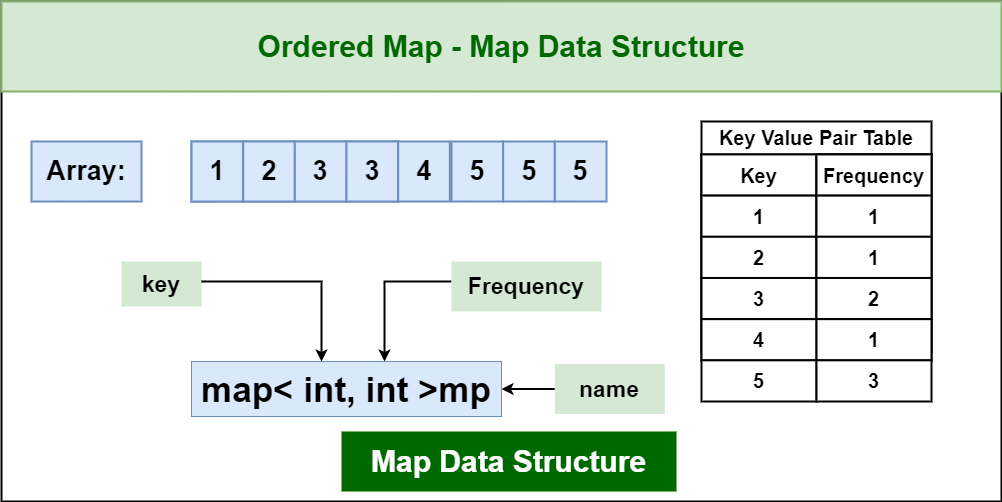
Ordered Map
Here is an example of how to declare an ordered map in C++:
C++
// CPP program to count frequencies of array items
#include <bits/stdc++.h>
using namespace std;
void countFreq(int arr[], int n)
{
map<int, int> mp;
// Traverse through array elements and
// count frequencies
for (int i = 0; i < n; i++)
mp[arr[i]]++;
// Traverse through map and print frequencies
for (auto x : mp)
cout << x.first << " " << x.second << endl;
}
int main()
{
int arr[] = { 1, 2, 3, 3, 4, 5, 5, 5 };
int n = sizeof(arr) / sizeof(arr[0]);
countFreq(arr, n);
return 0;
}
// Java program to count frequencies of array items
import java.io.*;
import java.util.*;
class GFG {
static void countFreq(int[] arr, int n)
{
Map<Integer, Integer> mp = new HashMap<>();
// Traverse through array elements and count
// frequencies
for (int i = 0; i < n; i++)
mp.put(arr[i], mp.getOrDefault(arr[i], 0) + 1);
// Traverse through map and print frequencies
for (Map.Entry<Integer, Integer> entry :
mp.entrySet())
System.out.println(entry.getKey() + " "
+ entry.getValue());
}
public static void main(String[] args)
{
int[] arr = { 1, 2, 3, 3, 4, 5, 5, 5 };
int n = arr.length;
countFreq(arr, n);
}
}
// This code is contributed by karthik.
// C# program to count frequencies of array items
using System;
using System.Collections.Generic;
public class GFG {
static void countFreq(int[] arr, int n)
{
Dictionary<int, int> mp
= new Dictionary<int, int>();
// Traverse through array elements and
// count frequencies
for (int i = 0; i < n; i++)
if (mp.ContainsKey(arr[i]))
mp[arr[i]]++;
else
mp.Add(arr[i], 1);
// Traverse through map and print frequencies
foreach(KeyValuePair<int, int> x in mp)
Console.WriteLine(x.Key + " " + x.Value);
}
public static void Main()
{
int[] arr = { 1, 2, 3, 3, 4, 5, 5, 5 };
int n = arr.Length;
countFreq(arr, n);
}
}
function countFreq(arr) {
let mp = new Map();
// Traverse through array elements and count frequencies
for (let i = 0; i < arr.length; i++) {
if (mp.has(arr[i])) {
mp.set(arr[i], mp.get(arr[i]) + 1);
} else {
mp.set(arr[i], 1);
}
}
// Traverse through map and print frequencies
for (let [key, value] of mp) {
console.log(key + " " + value);
}
}
let arr = [1, 2, 3, 3, 4, 5, 5, 5];
countFreq(arr);
# Python program to count frequencies of array items
from collections import defaultdict
def countFreq(arr):
freq = defaultdict(int)
# Traverse through array elements and count frequencies
for i in arr:
freq[i] += 1
# Traverse through dictionary and print frequencies
for key, value in freq.items():
print(key, value)
# Driver code
if __name__ == "__main__":
arr = [1, 2, 3, 3, 4, 5, 5, 5]
countFreq(arr)
Output1 1
2 1
3 2
4 1
5 3
2. Unordered Map
In C++, an unordered map is implemented using the std::unordered_map container provided in the Standard Template Library (STL). The std::unordered_map is a templated container that stores key-value pairs in an unordered manner based on the hash values of the keys.
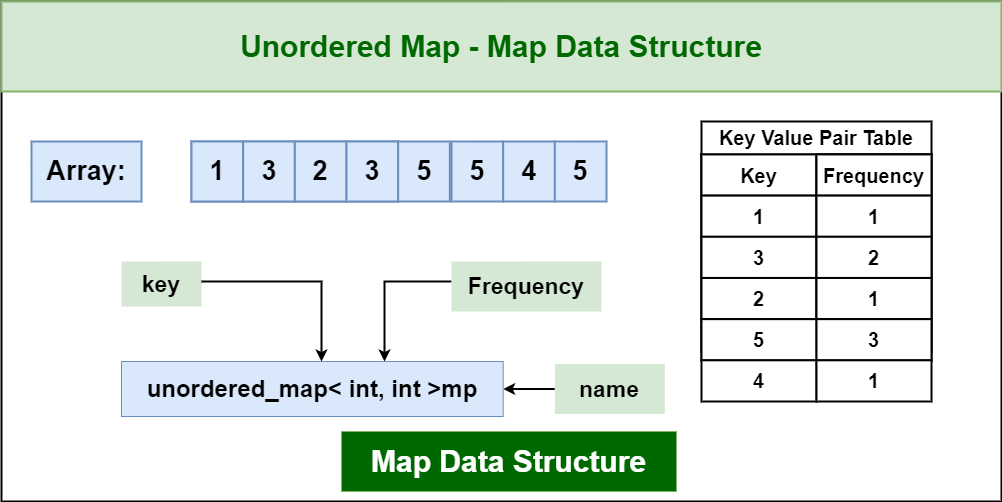
Unordered Map
Here is an example of how to declare an unordered map in C++:
Operations Associated with Map Data Structures:
A map is a data structure that allows you to store key-value pairs. Here are some common operations that you can perform with a map:
- Insert: we can insert a new key-value pair into the map and can assign a value to the key.
- Retrieve: we can retrieve the value associated with a key and can pass in the key as an argument.
- Update: we can update the value associated with a key and can assign a new value to the key.
- Delete: we can delete a key-value pair from the map by using the erase() method and passing in the key as an argument.
- Lookup: we can look up if a key exists in the map by using the count() method or by checking if the value associated with the key is equal to the default value.
- Iteration: we can iterate over the key-value pairs in the map by using a for loop or an iterator.
- Sorting: Depending on the implementation of the map, we can sort the key-value pairs based on either the keys or the values.
Below is the Implementation of the above Operations:
C++
#include <iostream>
#include <map>
int main()
{
// Creating a map
std::map<std::string, int> m;
// Inserting a new key-value pair
m["apple"] = 100;
m["banana"] = 200;
m["cherry"] = 300;
// Retrieving the value associated with a key
int value = m["banana"];
std::cout << "Value for key 'banana': " << value
<< std::endl;
// Updating the value associated with a key
m["banana"] = 250;
value = m["banana"];
std::cout << "Updated value for key 'banana': " << value
<< std::endl;
// Removing a key-value pair
m.erase("cherry");
// Iterating over the key-value pairs in the map
std::cout << "Key-value pairs in the map:" << std::endl;
for (const auto& pair : m) {
std::cout << pair.first << ": " << pair.second
<< std::endl;
}
return 0;
}
import java.util.HashMap;
import java.util.Map;
public class GFG {
public static void main(String[] args)
{
// Creating a map
Map<String, Integer> m = new HashMap<>();
// Inserting a new key-value pair
m.put("apple", 100);
m.put("banana", 200);
m.put("cherry", 300);
// Retrieving the value associated with a key
int value = m.get("banana");
System.out.println("Value for key 'banana': "
+ value);
// Updating the value associated with a key
m.put("banana", 250);
value = m.get("banana");
System.out.println(
"Updated value for key 'banana': " + value);
// Removing a key-value pair
m.remove("cherry");
// Iterating over the key-value pairs in the map
System.out.println("Key-value pairs in the map:");
for (Map.Entry<String, Integer> pair :
m.entrySet()) {
System.out.println(pair.getKey() + ": "
+ pair.getValue());
}
}
}
# Creating a map
d = {'key1': 'value1', 'key2': 'value2', 'key3': 'value3'}
# Adding a new key-value pair
d['key4'] = 'value4'
# Retrieving the value associated with a key
print(d['key2']) # Output: value2
# Updating the value associated with a key
d['key2'] = 'new_value2'
# Removing a key-value pair
del d['key3']
# Iterating over the key-value pairs in the map
for key, value in d.items():
print(key, value)
using System;
using System.Collections.Generic;
public class GFG {
public static void Main(string[] args)
{
// Creating a dictionary
Dictionary<string, int> m
= new Dictionary<string, int>();
// Inserting a new key-value pair
m.Add("apple", 100);
m.Add("banana", 200);
m.Add("cherry", 300);
// Retrieving the value associated with a key
int value = m["banana"];
Console.WriteLine("Value for key 'banana': "
+ value);
// Updating the value associated with a key
m["banana"] = 250;
value = m["banana"];
Console.WriteLine("Updated value for key 'banana': "
+ value);
// Removing a key-value pair
m.Remove("cherry");
// Iterating over the key-value pairs in the map
Console.WriteLine("Key-value pairs in the map:");
foreach(KeyValuePair<string, int> pair in m)
{
Console.WriteLine(pair.Key + ": " + pair.Value);
}
}
}
// This code is contributed by prasad264
// Creating a map
let m = new Map();
// Inserting a new key-value pair
m.set("apple", 100);
m.set("banana", 200);
m.set("cherry", 300);
// Retrieving the value associated with a key
let value = m.get("banana");
console.log("Value for key 'banana': " + value);
// Updating the value associated with a key
m.set("banana", 250);
value = m.get("banana");
console.log("Updated value for key 'banana': " + value);
// Removing a key-value pair
m.delete("cherry");
// Iterating over the key-value pairs in the map
console.log("Key-value pairs in the map:");
for (let pair of m.entries()) {
console.log(pair[0] + ": " + pair[1]);
}
OutputValue for key 'banana': 200
Updated value for key 'banana': 250
Key-value pairs in the map:
apple: 100
banana: 250
Properties of Map Data Structure:
Here are some of the properties of the map data structure:
- Uniqueness: The keys in a map are unique, meaning that each key can only map to one value.
- Mutability: Maps are mutable, meaning that their elements can be changed after they are created.
- Associativity: Maps associate keys with values, meaning that each key is associated with exactly one value.
- Ordering: Maps do not have an inherent ordering, meaning that the order in which elements are inserted into a map does not affect the order in which they are retrieved.
- Hashing: Maps are typically implemented using hash tables, meaning that keys are hashed to indices in an underlying array, and values are stored in the corresponding array elements.
- Complexity: The time complexity for basic operations on a map, such as insert, lookup, and delete, is usually O(1) on average, meaning that these operations take a constant amount of time, on average, regardless of the size of the map. However, the worst-case time complexity can be O(n), where n is the number of elements in the map, in the case of hash collisions.
Applications of Map Data Structure:
1. Indexing and retrieval: Maps are used to index elements in an array and retrieve elements based on their keys.
2. Grouping and categorization: Maps can be used to group elements and categorize them into different buckets.
For example, you can group employees based on their departments, cities, or salary ranges.
3. Network routing: Maps are used in computer networks to store information about routes between nodes.
The information stored in the map can be used to find the shortest path between two nodes.
4. Graph algorithms: Maps can be used to represent graphs and perform graph algorithms, such as depth-first search and breadth-first search.
Complexity Analysis of Map Data Structure:
Time Complexity:
Operations
| Worst Case Scenario | Average Case Scenario | Best Case Scenario |
|---|
| Updating an element | O(N)
| O(1)
| O(1)
|
|---|
| Insertion an element | O(N)
| O(1)
| O(1)
|
|---|
| Deleting an element | O(N)
| O(1)
| O(1)
|
|---|
| Searching an element | O(N)
| O(1)
| O(1)
|
|---|
| Insert(TreeMap) | O(logN)
| O(logN)
| O(1)
|
|---|
| Delete(TreeMap) | O(logN)
| O(logN)
| O(1)
|
|---|
| Search(TreeMap) | O(logN)
| O(logN)
| O(1)
|
|---|
Share your thoughts in the comments
Please Login to comment...