Introduction of Shared Memory Segment
Last Updated :
15 May, 2023
Introduction of Shared Memory Segment :
The quickest kind of IPC accessible is shared memory. There is no kernel participation in transmitting data between processes after the memory is mapped into the address space of the processes that are sharing the memory region. However, some type of synchronization between the processes that save and retrieve data to and from the shared memory region is usually necessary. Mutexes, condition variables, read-write locks, record locks, and semaphores were all explored in Part 3 of this series.
Consider the typical stages in the client-server file copying application we used to demonstrate the various forms of message passing.
- The input file is read by the server. The kernel reads the data from the file into its memory and then copies it to the process.
- Using a pipe, FIFO, or message queue, the server writes this data to a message.
These types of IPC usually need data transfer from the process to the kernel.
In most cases, four copies of the data are necessary. Furthermore, these four copies are made between the kernel and a process, which is typically a costly copy (costlier than copying data within the kernel or inside a single process). The data transfer between the client and server through the kernel is depicted in Figure 1.
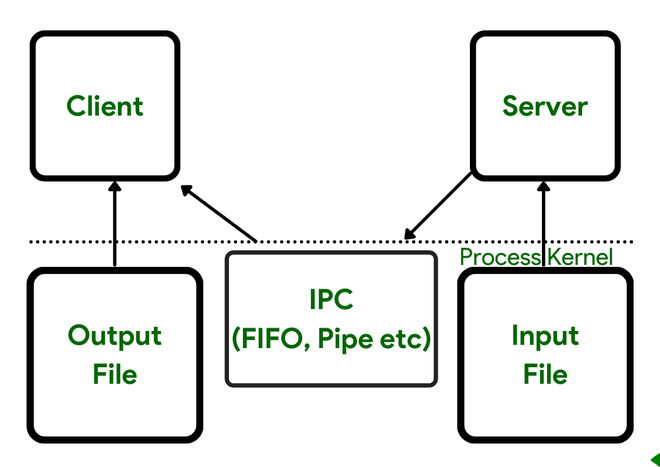
Figure 1.
The difficulty with various types of IPC—pipes, FIFOs, and message queues—is that information must pass through the kernel for two processes to communicate.
By allowing two or more processes to share a memory space, shared memory provides a workaround. Of course, the processes must work together to coordinate or synchronize their use of the shared memory.
This synchronization can be accomplished using any of the strategies and the following are the stages for the client-server example :
- A semaphore is used by the server to get access to a shared memory object.
- The server loads the shared memory object from the input file. The address of the data buffer, which is the second parameter to the read, points to the shared memory object.
- When the read is finished, the server sends a semaphore message to the client.
- The data from the shared memory object is written to the output file by the client.
Create and initialize a semaphore :
We establish and initialize a semaphore to safeguard a variable that we believe is shared (the global count). This semaphore is unnecessary since this assumption is incorrect. Notice how we execute sem unlink to remove the semaphore name from the system; however, while this removes the pathname, it has no effect on the semaphore that is already open. We do this so that even if the program crashes, the pathname is erased from the filesystem.
Set unbuffered standard output and fork :
Because both the parent and the child would be writing to standard output, we left it unbuffered. The output from the two processes is not interleaved as a result of this. Both the parent and the child run a loop that increases the counter for the set number of times, only incrementing the variable while the semaphore is held.
C
#include <stdio.h>
#include <unpipc.h>
#define GEEKSNAME "mysem"
int counter = 0;
int main(int argc, char** argv)
{
int i, nloop;
sem_t* mutex;
if (argc != 2)
err_quit("usage: incr1 <#loops>");
nloop = atoi(argv[1]);
mutex = Sem_open(Px_ipc_name(GEEKSNAME),
O_CREAT | O_EXCL, FILE_MODE, 1);
Sem_unlink(Px_ipc_name(GEEKSNAME));
setbuf(stdout, NULL);
if (Fork() == 0) {
for (i = 0; i < nloop; i++) {
Sem_wait(mutex);
printf("child: %d\n", counter++);
Sem_post(mutex);
}
exit(0);
}
for (i = 0; i < nloop; i++) {
Sem_wait(mutex);
printf("parent: %d\n", counter++);
Sem_post(mutex);
}
exit(0);
}
|
Both processes, as can be seen, have their own copy of the global count. Each starts with a value of 0 for this variable and then increases its own copy of it.
Advantages and Disadvantages of Shared Memory Segment
Advantages of Shared Memory Segment:
1.Fast and productive: Shared memory is one of the quickest ways for between process correspondence as it empowers cycles to share information straightforwardly without including the working framework piece.
2.Low above: Shared memory has a low above contrasted with different types of between process correspondence as it requires no serialization or marshaling of information.
3.Memory-proficient: With shared memory, cycles can share a lot of information without consuming an excess of memory since each interaction just has to designate memory for its own information structures.
4.Easy synchronization: Divided memory considers simple synchronization among processes as it gives worked in systems like semaphores and mutexes to control admittance to shared assets.
Disadvantages of Shared Memory Segment
1.Complexity: Shared memory is more mind boggling than different types of between process correspondence as it requires cautious coordination between cycles to stay away from race conditions and halts.
2.Security dangers: Since shared memory is open to different cycles, there is a gamble of one interaction getting to or changing information having a place with another interaction. This can be moderated by utilizing access control instruments like read-just consents, however it adds an additional layer of intricacy.
3.Limited versatility: Shared memory isn’t effectively convenient between various working frameworks and models since it relies upon the fundamental memory the board components.
4.Debugging troubles: Investigating shared memory can be trying as it requires specific apparatuses and strategies to recognize and determine issues connected with simultaneousness and synchronization.
Conclusion :
Because one copy of the data in shared memory is available to all threads or processes that share the memory, shared memory is the quickest type of IPC accessible. However, to coordinate the numerous threads or processes that share the memory, some type of synchronization is usually necessary.
Because this is one technique to transfer memory across related or unrelated processes, this chapter has focused on the mMap function and the mapping of regular files into memory. We no longer need to read, write, or seek to access a file that has been memory-mapped; instead, we just obtain or save the memory regions that have been mapped to the file by mMap.
Share your thoughts in the comments
Please Login to comment...