How to Group By and Count in MongoDB
Last Updated :
15 Apr, 2024
MongoDB’s aggregation framework provides powerful tools for grouping and counting data. Understanding how to use group by and count operations can help us to perform complex data analysis tasks efficiently.
In this article, we will learn about How to Group By and Count in MongoDB by understanding various examples in detail and so on.
How to Use Group By and Count in MongoDB?
In MongoDB, group by and count is used to count the number of documents in a collection, we can use the $group stage or aggregate in the pipeline. The $group stage allows the developer to group the documents in a particular group by a specified regular expression and apply an accumulator operator to each group to calculate a result.
Syntax:
db.collection.aggregate([
{
$group: {
_id: {
// Field(s) to group by
field1: "$field1",
field2: "$field2",
// Add more fields as needed
},
count: {
$sum: 1
}
}
}
])
Explanation:
- db.collection.aggregate([…]): This is the overall structure for running an aggregation pipeline on a MongoDB collection.
- { $group: { … } }: This is the `$group` stage of the aggregation pipeline, where the actual grouping operation is defined.
- _id: { … }: This is where you specify the field(s) to group the documents by. You can group by one or more fields.
- field1: This groups by the value of the `field1` field.
- field2: This groups by the value of the `field2` field.
- You can add more fields as needed, depending on your data structure.
- count: { $sum: 1 }: This is where you define the aggregation operation to perform on the grouped documents. In this case, we’re using the `$sum` operator to count the number of documents in each group by adding 1 for each document.
Let’s set up an Environment:
To understand How to Group By and Count in MongoDB we need a collection and some documents on which we will perform various queries. Here we will consider a collection called courses which contains information like course name, Instructore name, fees and duration.of the courses in various documents.
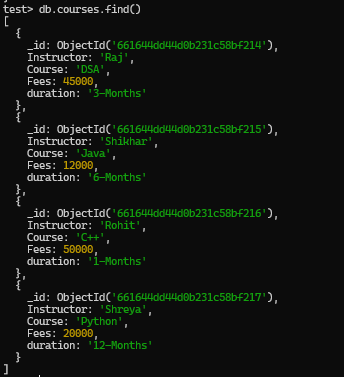
courses Collection
Example 1: To count the number of courses in each group, using the aggregation pipeline
Query:
db.courses.aggregate([
{
$group: {
_id: null,
totalCourses: { $sum: 1 }
}
}
])
Output:

total_courses
Explanation: In the above aggregation query we groups all documents into a single group and calculates the total count of documents in the collection then assigning it to the totalCourses field.
Example 2: To count the number of documents grouped by both the “Title” and “Fees” fields using the aggregation pipeline
Query:
db.courses.aggregate([
{
$group: {
_id: {
title: "$Title",
fees: "$Fees"
},
count: { $sum: 1 }
}
}
])
Output:

totally
Explanation: In the above aggregation query groups documents based on the combination of Title and Fees fields and then calculates the count of documents in each group.
Example 3: Let’s Create a report showing the total number of courses taught by each instructor then sorted in descending order based on the count of courses.
db.courses.aggregate([
{
$group: {
_id: "$Instructor",
totalCourses: { $sum: 1 }
}
},
{
$sort: {
totalCourses: -1
}
}
])
Output:

Explanation:
- The
$group stage groups the documents by the Instructor field and calculates the total number of courses taught by each instructor using the $sum operator.
- The
$sort stage sorts the grouped results in descending order based on the totalCourses field.
Conclusion
Overall, the $group and $count stages in the MongoDB aggregation pipeline provide powerful tools for grouping and counting data, which are suitable for data analysis and reporting tasks.
Share your thoughts in the comments
Please Login to comment...