How Decision Tree Depth Impact on the Accuracy
Last Updated :
26 Feb, 2024
Decision trees are a popular machine learning model due to its simplicity and interpretation. They work by recursively splitting the dataset into subsets based on the feature that provides the most information gain. One key parameter in decision tree models is the maximum depth of the tree, which determines how deep the tree can grow. In this article, we explore how varying the depth of a decision tree affects its prediction accuracy.
What is Decision Tree ?
A decision tree is a flowchart-like tree structure where each internal node denotes the feature, branches denote the rules and leaf nodes denote the result of the algorithm.
Now, we will understand this with an example of whether a student has distinction or not.
What is Decision Tree’s Depth?
The depth of a decision tree is the length of the longest path from the root node to a leaf node. A shallow tree has a lower depth, while a deep tree has a higher depth. A shallow tree may underfit the data, capturing too few patterns, while a deep tree may overfit the data, capturing noise in the training set.
What is Maxdepth?
The maximum depth of the selection tree is a critical parameter that influences the version’s complexity. When set to None, the tree continues to enlarge nodes till all leaves are pure or until each leaf consists of fewer samples than the specified `min_samples_split`. The depth of the tree is a key thing in controlling its complexity: growing intensity usually ends in extra complexity, which may bring about overfitting, even as decreasing intensity decreases complexity, probably causing underfitting. It is critical to strike a balance and choose an appropriate intensity to gain choicest version performance.
What is the impact of depth on Accuracy?
- Underfitting (Shallow Trees): When a decision tree is too shallow, it may not capture enough of the underlying patterns in the data. This can lead to high bias and low variance, resulting in poor accuracy on both the training and test sets. In such cases, increasing the tree depth can improve accuracy by allowing the tree to capture more complex patterns in the data.
- Overfitting (Deep Trees): On the other hand, when a decision tree is too deep, it may memorize the training data instead of learning general patterns. This can lead to high variance and low bias, resulting in high accuracy on the training set but poor performance on the test set. In this case, reducing the tree depth can improve generalization and hence improve accuracy on unseen data.
Implementation to Show impact of depth on Accuracy
Dataset Link : Weather Dataset
Importing the necessary libraries
Python3
import opendatasets as od
import matplotlib.pyplot as plt
import plotly.express as px
import seaborn as sns
import numpy as np
import pandas as pd
import matplotlib
import os
%matplotlib inline
|
Load the dataset
Python3
os.listdir('weather-dataset-rattle-package')
download_dir = 'weather-dataset-rattle-package/weatherAUS.csv'
raw_df = pd.read_csv(download_dir)
print(df)
|
Output:
Date Location MinTemp MaxTemp Rainfall Evaporation Sunshine WindGustDir WindGustSpeed WindDir9am WindDir3pm WindSpeed9am WindSpeed3pm Humidity9am Humidity3pm Pressure9am Pressure3pm Cloud9am Cloud3pm Temp9am Temp3pm RainToday RainTomorrow
0 2008-12-01 Albury 13.4 22.9 0.6 NaN NaN W 44.0 W WNW 20.0 24.0 71.0 22.0 1007.7 1007.1 8.0 NaN 16.9 21.8 No No
1 2008-12-02 Albury 7.4 25.1 0.0 NaN NaN WNW 44.0 NNW WSW 4.0 22.0 44.0 25.0 1010.6 1007.8 NaN NaN 17.2 24.3 No No
2 2008-12-03 Albury 12.9 25.7 0.0 NaN NaN WSW 46.0 W WSW 19.0 26.0 38.0 30.0 1007.6 1008.7 NaN 2.0 21.0 23.2 No No
3 2008-12-04 Albury 9.2 28.0 0.0 NaN NaN NE 24.0 SE E 11.0 9.0 45.0 16.0 1017.6 1012.8 NaN NaN 18.1 26.5 No No
4 2008-12-05 Albury 17.5 32.3 1.0 NaN NaN W 41.0 ENE NW 7.0 20.0 82.0 33.0 1010.8 1006.0 7.0 8.0 17.8 29.7 No No
Splitting the data in Training, Validation and Testing
Since, it is a timeseries data, therefore, taking latest data from the dataset as testing and validation, before that taking data for training.
Python3
year = pd.to_datetime(raw_df.Date).dt.year
train_df = raw_df[year < 2015]
val_df = raw_df[year == 2015]
test_df = raw_df[year > 2015]
|
Seperating input and target cols and input and output data
Python3
input_cols = raw_df.columns[1:-1]
output_cols = raw_df.columns[-1]
|
Training, validation and testing data
Python3
train_inputs = train_df[input_cols]
train_targets = train_df[output_cols]
val_inputs = val_df[input_cols]
val_targets = val_df[output_cols]
test_inputs = test_df[input_cols]
test_targets = test_df[output_cols]
|
Training the Model
Python3
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier(random_state = 42)
model.fit(X_train,train_targets)
|
Evaluating the model
Python3
train_preds = model.predict(X_train)
print(accuracy_score(train_targets,train_preds))
val_preds = model.predict(X_val)
print(accuracy_score(val_targets,val_preds))
|
Output:
0.9999797955307714
0.7921188555510418
Here, we can observer the training_accuracy tends to 100% but, validation accuracy is only 79%, which means, decision tree is overfitted with the data.
Visualizing the impact of depth on accuracy.
- This function initialize DecisionTreeModel for various depths
- Then fit the model on training data
- Then calculates training_error from training_score and validation_error from validation score respectively.
Python3
def max_depth_error(max_depths):
model = DecisionTreeClassifier(max_depth=max_depths, random_state=42)
model.fit(X_train, train_targets)
training_error = 1 - model.score(X_train, train_targets)
validation_error = 1 - model.score(X_val, val_targets)
return {"Max Depth": max_depths, "Training error": training_error, "Validation Error": validation_error}
max_depth_Df = pd.DataFrame([max_depth_error(md) for md in range(1, 20)])
max_depth_Df
|
Output:
Max Depth Training error Validation Error
0 1 0.184315 0.177935
1 2 0.179547 0.172712
2 3 0.170869 0.166560
3 4 0.165707 0.164355
4 5 0.160676 0.159074
5 6 0.156271 0.157275
6 7 0.153312 0.154605
7 8 0.147806 0.158029
8 9 0.140906 0.156578
9 10 0.132945 0.157333
10 11 0.123227 0.159248
11 12 0.113489 0.160815
12 13 0.101750 0.163833
13 14 0.089981 0.167373
14 15 0.078999 0.171261
15 16 0.068180 0.174279
16 17 0.058138 0.176890
17 18 0.048733 0.181243
18 19 0.040025 0.187569
Plotting Accuracy vs Depth
Python3
plt.figure()
plt.plot(max_depth_Df['Max Depth'], max_depth_Df['Training error'])
plt.plot(max_depth_Df['Max Depth'], max_depth_Df['Validation Error'])
plt.title('Training vs. Validation Error')
plt.xticks(range(0,21, 2))
plt.xlabel('Max. Depth')
plt.ylabel('Prediction Error (1 - Accuracy)')
plt.legend(['Training', 'Validation'])
|
Output:
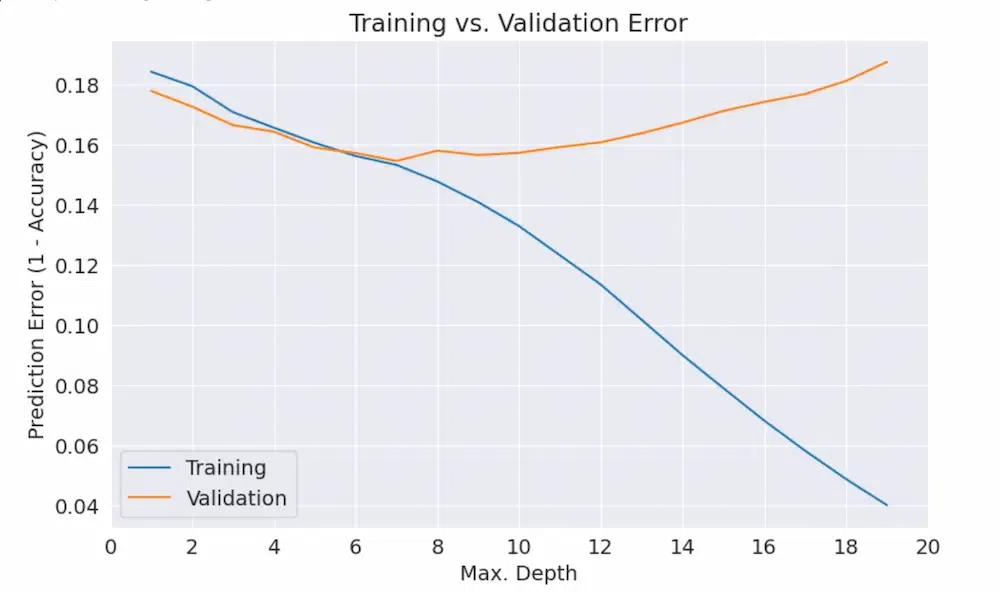
max_depth vs prediction error
- In this example, you can see blue(training set) and orange(validation set).
- As depth increases, training set prediction error(means accuracy) gets better while validation set prediction error(means accuracy) gets worse.
- So, we have to find one optimal point where training and validation accuracy is almost same.
- That depth is 7(by observation).
Finding the Optimal maxDepth:
- Tuning Techniques: Cross-validation and hyperparameter tuning techniques like GridSearchCV help you to find optmial depth. They test out different parameters for you and based on results you can find out optimal depth.
- Dataset Characteristics: If the dataset is smaller then decision tree will overfit and if dataset has more noise not cleaned properly, then there will be not proper results.
- Ensemble Power: Instead of decision tree, you can try out Random Forest powerful ensemble learning technique. Random forest by default takes 100 decision trees also you can change as per your need and find out the best results from dataset.
Now, initialize and fit the model with max_depth = 7 and then fit our model.
Python3
model = DecisionTreeClassifier(max_depth=7,random_state=42)
model.fit(X_train,train_targets)
model.score(X_train,val_train)
model.score(X_val,val_targets)
model.score(X_test,test_targets)
|
Output:
0.8466884874934335
0.8453949277465034
0.8310618310618311
These scores indicate that the model performs similarly on the training and validation sets, suggesting that it is not overfitting. However, there is a slight drop in performance on the test set, which is expected but not significant. Overall, the model seems to generalize well to unseen data.
Share your thoughts in the comments
Please Login to comment...