ML | Gini Impurity and Entropy in Decision Tree
Last Updated :
24 Feb, 2023
Gini Index
- The Gini Index is the additional approach to dividing a decision tree.
- Purity and impurity in a junction are the primary focus of the Entropy and Information Gain framework.
- The Gini Index, also known as Impurity, calculates the likelihood that somehow a randomly picked instance would be erroneously cataloged.
Machine Learning is a Computer Science domain that provides the ability for computers to learn without being explicitly programmed. Machine Learning is one of the most highly demanded technologies that everybody wants to learn and most companies require highly skilled Machine Learning engineers. In this domain, there are various machine learning algorithms developed to solve complex problems with ease. These algorithms are highly automated and self-modifying, as they continue to improve over time with the addition of an increased amount of data and with minimum human intervention required. To learn about top Machine Learning algorithms that every ML engineer should know click here.
In this article, we will be focusing more on Gini Impurity and Entropy methods in the Decision Tree algorithm and which is better among them.
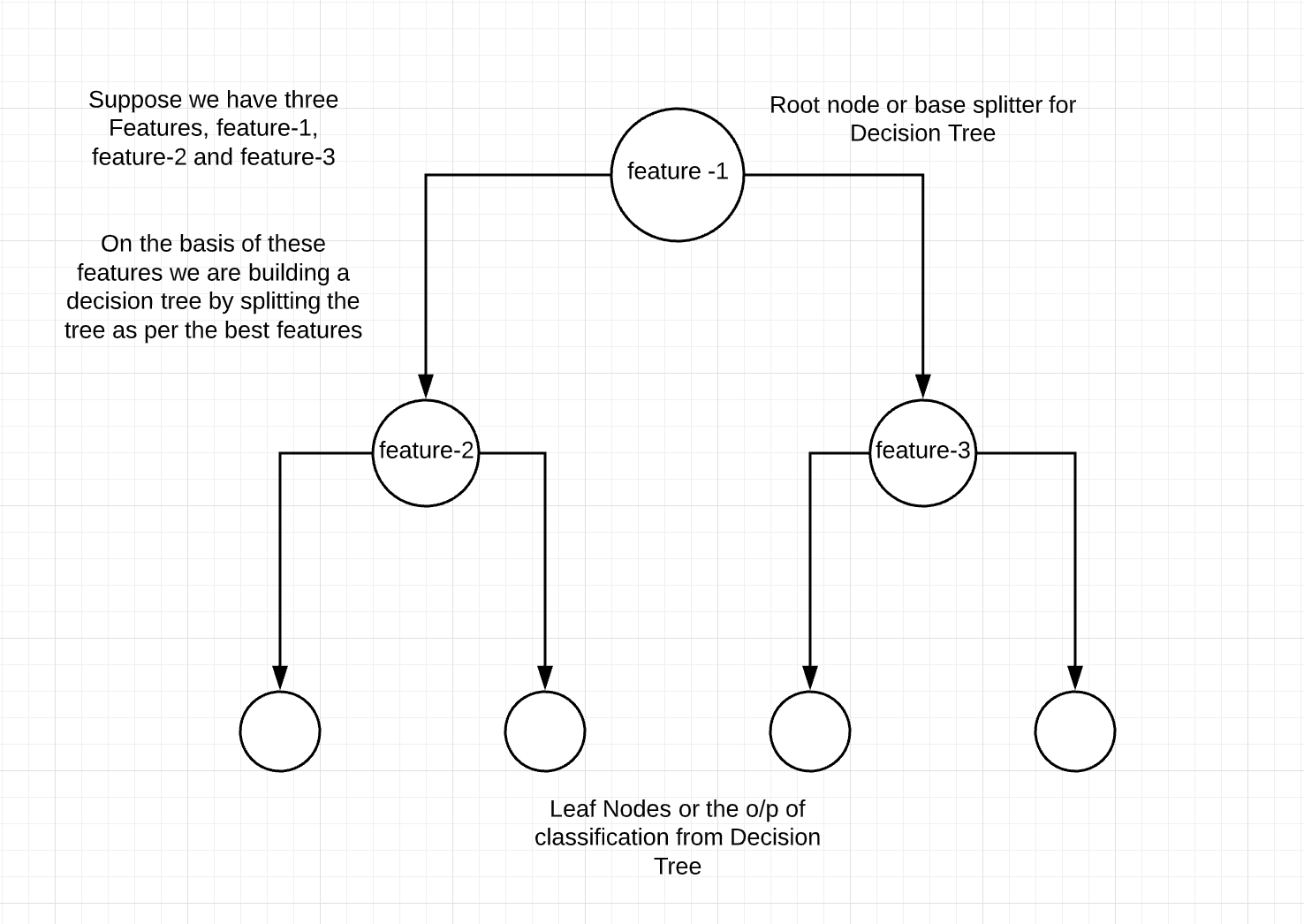
Decision Tree is one of the most popular and powerful classification algorithms that we use in machine learning. The decision tree from the name itself signifies that it is used for making decisions from the given dataset. The concept behind the decision tree is that it helps to select appropriate features for splitting the tree into subparts and the algorithm used behind the splitting is ID3. If the decision tree build is appropriate then the depth of the tree will be less or else the depth will be more. To build the decision tree in an efficient way we use the concept of Entropy. To learn more about the Decision Tree click here. In this article, we will be more focused on the difference between Gini Impurity and Entropy.
Entropy:
- The word “entropy,” is hails from physics, and refers to an indicator of the disorder. The expected volume of “information,” “surprise,” or “uncertainty” associated with a randomly chosen variable’s potential outcomes is characterized as the entropy of the variable in information theory.
- Entropy is a quantifiable and measurable physical attribute and a scientific notion that is frequently associated with a circumstance of disorder, unpredictability, or uncertainty.
- From classical thermodynamics, where it was originally identified, through the macroscopic portrayal of existence in statistical physics, to the principles of information theory, the terminology, and notion are widely used in a variety of fields of study
As discussed above entropy helps us to build an appropriate decision tree for selecting the best splitter. Entropy can be defined as a measure of the purity of the sub-split. Entropy always lies between 0 to 1. The entropy of any split can be calculated by this formula.

The algorithm calculates the entropy of each feature after every split and as the splitting continues on, it selects the best feature and starts splitting according to it. For a detailed calculation of entropy with an example, you can refer to this article.
Gini Impurity: The internal working of Gini impurity is also somewhat similar to the working of entropy in the Decision Tree. In the Decision Tree algorithm, both are used for building the tree by splitting as per the appropriate features but there is quite a difference in the computation of both methods. Gini Impurity of features after splitting can be calculated by using this formula.
![$G I=1-\sum_{i=1}^{n}(p)^{2}$ $\left.\left.G I=1-\left[\left(P_{(}+\right)\right)^{2}+\left(P_{(}-\right)\right)^{2}\right]$](https://www.geeksforgeeks.org/wp-content/ql-cache/quicklatex.com-8b6524e1f842c8bc8122dd2703ffbdf0_l3.png "Rendered by QuickLaTeX.com")
For the detailed computation of the Gini Impurity with examples, you can refer to this article. By using the above formula gini Impurity of feature/split is calculated.
Entropy v/s Gini Impurity: Now we have learned about Gini Impurity and Entropy and how it actually works. Also, we have seen how we can calculate Gini Impurity/Entropy for a split/feature. But the major question that arises here is why do we need to have both methods for computation and which is better.
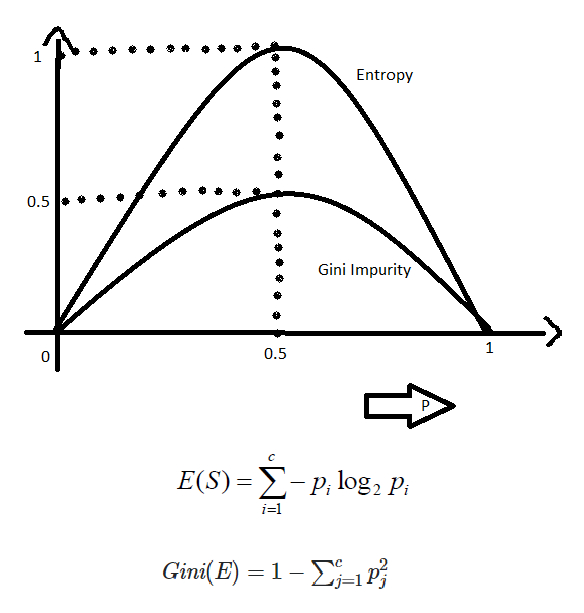
The internal working of both methods is very similar and both are used for computing the feature/split after every new splitting. But if we compare both methods then Gini Impurity is more efficient than entropy in terms of computing power. As you can see in the graph for entropy, it first increases up to 1 and then starts decreasing, but in the case of Gini impurity it only goes up to 0.5 and then it starts decreasing, hence it requires less computational power. The range of Entropy lies in between 0 to 1 and the range of Gini Impurity lies between 0 to 0.5. Hence we can conclude that Gini Impurity is better as compared to entropy for selecting the best features.
Difference between Gini Index and Entropy
| It is the probability of misclassifying a randomly chosen element in a set. | While entropy measures the amount of uncertainty or randomness in a set. |
| The range of the Gini index is [0, 1], where 0 indicates perfect purity and 1 indicates maximum impurity. | The range of entropy is [0, log(c)], where c is the number of classes. |
| Gini index is a linear measure. | Entropy is a logarithmic measure. |
| It can be interpreted as the expected error rate in a classifier. | It can be interpreted as the average amount of information needed to specify the class of an instance. |
| It is sensitive to the distribution of classes in a set. | It is sensitive to the number of classes. |
| The computational complexity of the Gini index is O(c). | Computational complexity of entropy is O(c * log(c)). |
| It is less robust than entropy. | It is more robust than Gini index. |
| It is sensitive. | It is comparatively less sensitive. |
|
Formula for the Gini index is Gini(P) = 1 – ∑(Px)^2 , where Pi is
the proportion of the instances of class x in a set.
| Formula for entropy is Entropy(P) = -∑(Px)log(Px),
where pi is the proportion of the instances of class x in a set. |
| It has a bias toward selecting splits that result in a more balanced distribution of classes. | It has a bias toward selecting splits that result in a higher reduction of uncertainty. |
| Gini index is typically used in CART (Classification and Regression Trees) algorithms | Entropy is typically used in ID3 and C4.5 algorithms |
Conclusion: It ought to be emphasized that there is no one appropriate approach for evaluating unpredictability or impurities, and that the decision between the Gini index and entropy varies significantly on the particular circumstance and methodology being employed.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...