High Availability Mechanism in Cassandra
Last Updated :
11 Oct, 2019
In this article we will learn about mechanism of high availability in Cassandra by using the following key terminology.
1. Seed Node
2. Gossip Communication Protocol
3. Failure Detection
4. Hinted Handoff
lets discuss one by one.
1. Seed Node:
In Apache Cassandra it is first nodes to start in cluster. If we want to Configured seed node, then we can Configured in Cassandra.yaml file which is main file in Cassandra for changing any configuration setting.seed node helps in Bootstrapping for new nodes joining the cluster in Cassandra.
Seed node also helpful to provide information about another node. When a new node comes online then it will gossip the seed node to obtain information about the other nodes in cluster.
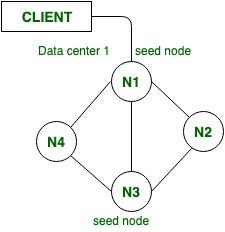
Figure – Seed Node
Start sequence:
In Cassandra start sequence is play an important role. start sequence gives initial sequence so, start seed nodes one by one, and then the other nodes.
Best practice: In Cassandra it is always a good practice to set more than one seed node per data center in a cluster.
Listener address and storage port:
In inter-node communication we used the listener_address and storage port for communication in Cassandra. The default port id for Cassandra is 7000. In Cassandra port id must be same for every node in the cluster.
listener_address= ip address of node
storage_port = 7000 (by default)
2. Gossip Communication Protocol:
In Cassandra Nodes are periodically (every second) exchanging state information (e.g., dead or alive) about themselves and then about other nodes they know about. In Cassandra Gossip Communication Protocol is also known as epidemic protocol. It is a quick, decentralized automatic way to learn about itself for the cluster which is very helpful about nodes information in cluster.
In Gossip Communication Protocol to allow fast restart then Gossip Information Persisted locally by each node. Understanding the meaning of persistence is important for evaluating different data store systems.
Persistence is “the continuance of an effect after its cause is removed”. In the context of storing data in a computer system, this means that the data survives after the process with which it was created has ended. In other words, for a data store to be considered persistent, it must write to non-volatile storage.
Critical:
It is one of the important task that list of seed nodes in any data center must be the same on each node in the cluster
3. Failure Detection:
In case of Failure detection, a node locally determining from gossip state and history and adjusting routes accordingly in a cluster. Phi Accrual is important algorithm for Failure detection algorithm. It state that a continuous suspicion level between dead and alive state of a node of how confident a node has failed. It can be Network performance, workload issue it must take on priority and so on taken into account.
In case of failure detection of a node then other nodes will periodically try to gossip with the failed node to see if it comes back online.
Now, lets have a look with CQL query to check the status of a node. It is by default, cqlsh connects to 127.0.0.1. To get the information such that host id, release version etc. used the following CQL query.
SELECT peer, data_center, host_id,
preferred_ip, rack, release_version,
rpc_address, schema_version
FROM system.peers;
To get the information of a node used the following CQL command in Cassandra.
nodetool gossipinfo
To Terminate node by executing:
nodetool stopdaemon
Check the gossipinfo on node1. Notice node2’s gossip information is still present as it is part of the cluster, but its STATUS state is shutdown.
4. Hinted handoff:
In Cassandra it is one of the important aspects for high availability mechanism . It help to Reduce restoration time of a failed node rejoining the cluster and to ensure absolute write availability by tolerating inconsistent reads. As shown in diagram if replica is down at the time a write occurs another healthy replica stores a hint and if all relevant replicas are down the coordinator or locally stores the hint.
Hint = location [failed replica]
+ affected [row key]
+ actual data being written
Note:
In Cassandra the hint will be handed off, when a node responsible for that token range is up again.
Anti-Entropy:
In case of high availability mechanism Anti-entropy is replica synchronization mechanism to ensure up to date data on all nodes.
Example:
In general, the recommendation is to have enough nodes in the cluster and a replication factor sufficient to avoid write request failures. For example, consider a cluster consisting of three nodes, Node 1, Node 2, and Node 3, with a replication factor of 2. When a row K is written to the coordinator (node A in this case), even if Node 3 is down, the consistency level of ONE or QUORUM can be met. Why? Both Node 1 and Node 2 will receive the data, so the consistency level requirement is met. Node 1 hint is stored for Node 3 and written when Node 3 comes up. In the meantime, the coordinator can acknowledge that the write succeeded.
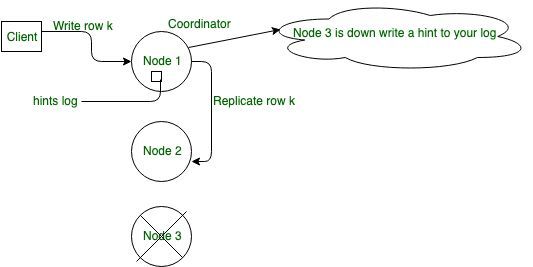
Figure – Hinted Handoff: Repair during write path
Share your thoughts in the comments
Please Login to comment...