Hadoop – File Blocks and Replication Factor
Last Updated :
09 Mar, 2021
Hadoop Distributed File System i.e. HDFS is used in Hadoop to store the data means all of our data is stored in HDFS. Hadoop is also known for its efficient and reliable storage technique. So have you ever wondered how Hadoop is making its storage so much efficient and reliable? Yes, here what the concept of File blocks is introduced. The Replication Factor is nothing but it is a process of making replicate or duplicate’s of data so let’s discuss them one by one with the example for better understanding.
File Blocks in Hadoop
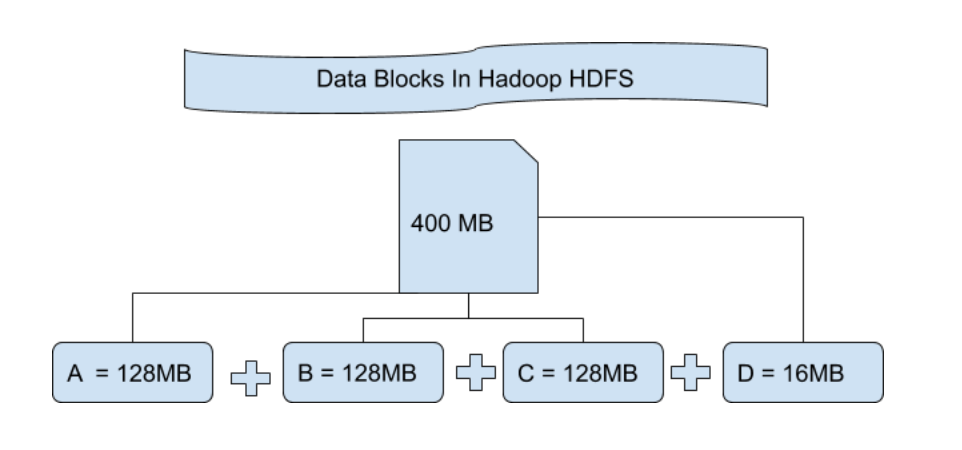
What happens is whenever you import any file to your Hadoop Distributed File System that file got divided into blocks of some size and then these blocks of data are stored in various slave nodes. This is a kind of normal thing that happens in almost all types of file systems. By default in Hadoop1, these blocks are 64MB in size, and in Hadoop2 these blocks are 128MB in size which means all the blocks that are obtained after dividing a file should be 64MB or 128MB in size. You can manually change the size of the file block in hdfs-site.xml file.

Let’s understand this concept of breaking down of file in blocks with an example. Suppose you have uploaded a file of 400MB to your HDFS then what happens is, this file got divided into blocks of 128MB + 128MB + 128MB + 16MB = 400MB size. Means 4 blocks are created each of 128MB except the last one.
Hadoop doesn’t know or it doesn’t care about what data is stored in these blocks so it considers the final file blocks as a partial record. In the Linux file system, the size of a file block is about 4KB which is very much less than the default size of file blocks in the Hadoop file system. As we all know Hadoop is mainly configured for storing large size data which is in petabyte, this is what makes Hadoop file system different from other file systems as it can be scaled, nowadays file blocks of 128MB to 256MB are considered in Hadoop.
Now let’s understand why these blocks are very huge. There are mainly 2 reason’s as discussed below:
- Hadoop File Blocks are bigger because if the file blocks are smaller in size then in that case there will be so many blocks in our Hadoop File system i.e. in HDFS. Storing lots of metadata in these small-size file blocks in a very huge amount becomes messy which can cause network traffic.
- Blocks are made bigger so that we can minimize the cost of seeking or finding. Because sometimes time taken to transfer the data from the disk can be more than the time taken to start these blocks.
Advantages of File Blocks:
- Easy to maintain as the size can be larger than any of the single disk present in our cluster.
- We don’t need to take care of Metadata like any of the permission as they can be handled on different systems. So no need to store this Meta Data with the file blocks.
- Making Replicates of this data is quite easy which provides us fault tolerance and high availability in our Hadoop cluster.
- As the blocks are of a fixed configured size we can easily maintain its record.
Replication and Replication Factor
Replication ensures the availability of the data. Replication is nothing but making a copy of something and the number of times you make a copy of that particular thing can be expressed as its Replication Factor. As we have seen in File blocks that the HDFS stores the data in the form of various blocks at the same time Hadoop is also configured to make a copy of those file blocks. By default the Replication Factor for Hadoop is set to 3 which can be configured means you can change it Manually as per your requirement like in above example we have made 4 file blocks which means that 3 Replica or copy of each file block is made means total of 4×3 = 12 blocks are made for the backup purpose.
Now you might be getting a doubt that why we need this replication for our file blocks this is because for running Hadoop we are using commodity hardware (inexpensive system hardware) which can be crashed at any time. We are not using a supercomputer for our Hadoop setup. That is why we need such a feature in HDFS which can make copies of that file blocks for backup purposes, this is known as fault tolerance.
Now one thing we also need to notice that after making so many replica’s of our file blocks we are wasting so much of our storage but for the big brand organization the data is very much important than the storage. So nobody care for this extra storage.
You can configure the Replication factor in you hdfs-site.xml file.
Here, we have set the replication Factor to one as we have only a single system to work with Hadoop i.e. a single laptop, as we don’t have any Cluster with lots of the nodes. You need to simply change the value in dfs.replication property as per your need.

How does Replication work?
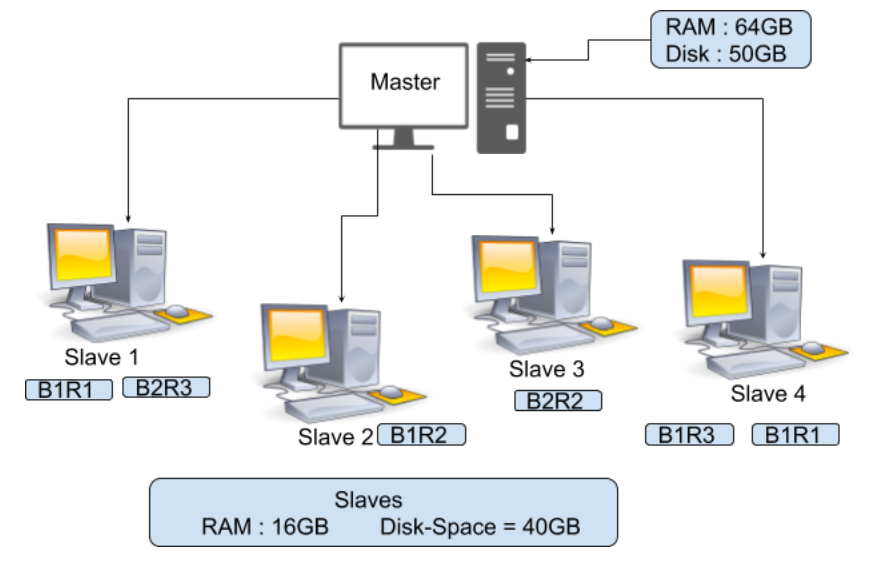
In the above image, you can see that there is a Master with RAM = 64GB and Disk Space = 50GB and 4 Slaves with RAM = 16GB, and disk Space = 40GB. Here you can observe that RAM for Master is more. It needs to be kept more because your Master is the one who is going to guide this slave so your Master has to process fast. Now suppose you have a file of size 150MB then the total file blocks will be 2 shown below.
128MB = Block 1
22MB = Block 2
As the replication factor by-default is 3 so we have 3 copies of this file block
FileBlock1-Replica1(B1R1) FileBlock2-Replica1(B2R1)
FileBlock1-Replica2(B1R2) FileBlock2-Replica2(B2R2)
FileBlock1-Replica3(B1R3) FileBlock2-Replica3(B2R3)
These blocks are going to be stored in our Slave as shown in the above diagram which means if suppose your Slave 1 crashed then in that case B1R1 and B2R3 get lost. But you can recover the B1 and B2 from other slaves as the Replica of this file blocks is already present in other slaves, similarly, if any other Slave got crashed then we can obtain that file block some other slave. Replication is going to increase our storage but Data is More necessary for us.
Share your thoughts in the comments
Please Login to comment...