Design Distributed Job Scheduler | System Design
Last Updated :
02 Apr, 2024
In today’s technology-driven world, it’s critical to handle computing tasks across different systems efficiently. A Distributed Job Scheduler system helps coordinate the running of tasks across multiple computers in a distributed computing environment. It manages the scheduling, distributing, and tracking of these tasks, including data processing, analysis, batch job runs, and resource assignment.
Important Topics for Distributed Job Scheduler
Requirements Gathering for Distributed Job Scheduler
- Job Scheduling: Enable users to submit jobs to the system for execution at specified times or intervals.
- Distributed Execution: Distribute jobs across multiple worker nodes in a distributed environment for parallel execution.
- Monitoring and Reporting: Provide monitoring capabilities to track job execution status, system health, and resource utilization.
- Reliability: Jobs should be executed accurately and on time, ensuring high reliability of the system.
- Performance: Jobs should be executed efficiently with minimal latency and overhead to meet performance requirements.
- Scalability: The system should be able to scale horizontally to handle a large number of concurrent jobs effectively.
- Fault Tolerance: Implement mechanisms to handle node failures and job retries to ensure fault tolerance and high availability.
- Security: Ensure data confidentiality and integrity by implementing security measures to prevent unauthorized access to the system.
Capacity Estimations for Distributed Job Scheduler
1. Traffic Estimate
- Job Submissions: Estimate the number of job submissions per unit of time.
- For example, if the system is expected to receive 1000 job submissions per hour during peak periods, the traffic estimate would be 1000 jobs/hour.
2. Storage Estimate
- Job Metadata: Estimate the amount of storage required for job metadata. If each job metadata entry consumes 1 KB of storage and the system is expected to handle 1 million jobs, the storage estimate would be 1 GB.
- Logs and Configuration: Estimate additional storage for logs and configuration data based on expected usage patterns and retention policies.
3. Bandwidth Estimate
- Communication Overhead: Estimate the bandwidth required for communication between the scheduler and worker nodes.
- For example, if each message sent between nodes is 1 KB in size and there are 1000 messages exchanged per second, the bandwidth estimate would be 1 MB/s.
4. Memory Estimate
- Job Queues: Estimate the memory required for storing job queues. If each job queue entry consumes 100 bytes of memory and the system is expected to handle 10,000 concurrent jobs, the memory estimate would be 1 MB.
- Execution Context: Estimate memory for storing execution contexts and system state based on the complexity of job execution and concurrency levels.

1. Job Submission Interfaces
- Users submit jobs through a web portal, which interfaces with an API Gateway.
- The API Gateway acts as a centralized entry point for job submissions, providing a unified interface for users to interact with the system.
- Once a job is submitted, it is passed to the Scheduler component for processing.
2. Scheduling Algorithms
- The Scheduler component receives job submissions from the API Gateway.
- It employs scheduling algorithms to determine the optimal assignment of resources and timing for job execution.
- Scheduling decisions are made based on factors such as job priority, resource requirements, and current system load.
3. Resource Management
- The system includes a Resource Management module responsible for overseeing the allocation and utilization of resources within the cluster.
- This module includes a Cluster Manager component, which coordinates resource allocation across the cluster based on directives from the Scheduler.
- Additionally, specific Resource Managers may handle the allocation of individual resource types, such as CPU, memory, and storage.
4. Worker Nodes
- Worker nodes are responsible for executing the tasks associated with the scheduled jobs.
- These nodes include Compute Node 1, Compute Node 2, and Compute Node 3.
- Each worker node is connected to the Cluster Manager and receives job assignments and resource alocations from it.
5. Monitoring Services
- The Monitoring Services component collects and analyzes data related to job execution and system performance.
- It consists of three main components: Alerts, Logging, and Metrics.
- Alerts provide real-time notifications of critical events or system failures.
- Logging captures detailed information about job execution, errors, and system events for auditing and troubleshooting.
- Metrics track performance metrics such as job completion times, resource utilization, and cluster health, enabling performance optimization and capacity planning.
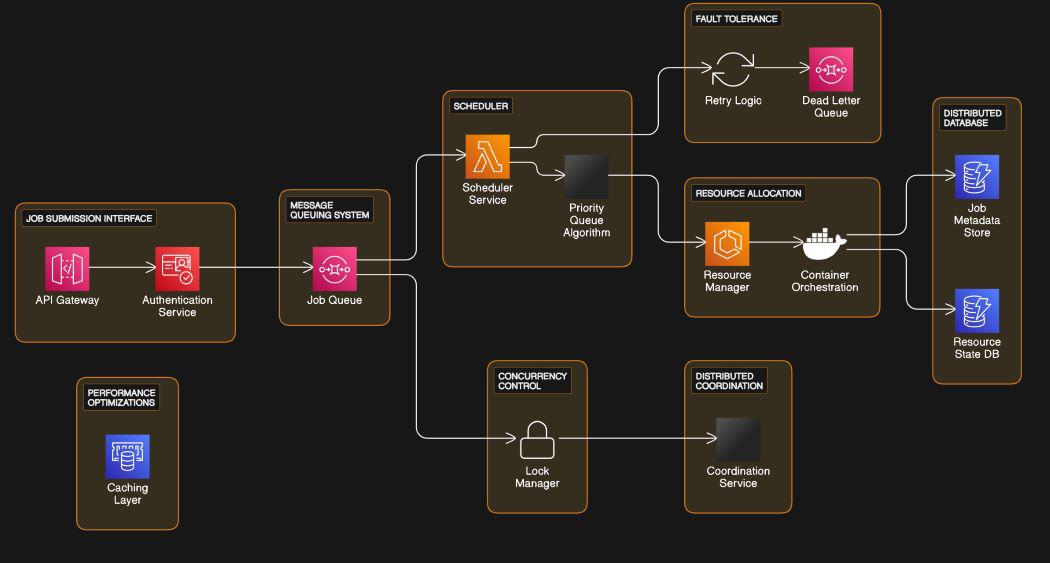
1. Job Submission Interface
- The API Gateway serves as the entry point for job submissions.
- It connects to the Authentication Service for user authentication.
- The Authentication Service verifies user credentials and passes authenticated requests to the Job Queue.
2. Message Queuing System
- The Job Queue, part of the Message Queuing System, receives authenticated job submissions.
- It holds incoming job requests until they are processed by the Scheduler Service.
3. Scheduler and Lock Manager
- The Scheduler Service manages the scheduling of jobs based on priority and retry logic.
- It utilizes a Lock Manager for concurrency control, ensuring that jobs are processed safely in a multi-threaded environment.
4. Concurrency Control
The Lock Manager handles concurrency control by coordinating access to shared resources among multiple threads or processes.
5. Distributed Coordination
- The Coordination Service, part of Distributed Coordination, facilitates communication and synchronization between distributed components.
- It ensures consistency and coherence in the distributed system’s operation.
- The Retry Logic component within Fault Tolerance handles job retries in case of failures or errors during processing.
- It is connected to a Dead Letter Queue, where failed job messages are stored for later analysis or processing.
7. Resource Allocation
- The Resource Manager component manages the allocation of resources needed for job execution.
- It interacts with a Container Orchestration system to provision and manage containers for executing jobs.
- The Resource Manager also interfaces with a Job Metadata Store and a Resource State Database for tracking job and resource information.
8. Distributed Database
- The Job Metadata Store and Resource State Database are part of a Distributed Database system.
- They store and manage job metadata, resource states, and other relevant information needed for job scheduling and resource allocation.
9. Performance Optimizations
- The system includes a caching layer for performance optimizations.
- This caching layer helps improve system responsiveness and reduce latency by storing frequently accessed data in memory for faster retrieval.
Database Design for Distributed Job Scheduler

1. Job Definition Table
- This table stores information about each job definition submitted to the system.
- It includes details such as the job ID, user ID (who submitted the job), job name, description, parameters, status (pending, scheduled, completed, failed), and timestamps for various events related to the job (created time, scheduled time, completed time, etc.).
- For example, when a user submits a job to the system, the details of that job, such as its name, parameters, and status, are stored in this table.
2. Job Schedule Table
- This table stores information about scheduled jobs and their execution times.
- It includes the job ID (which references the Job Definition Table), scheduled execution time, and status (scheduled, canceled).
- For example, when a job is scheduled to run at a specific time, its details are recorded in this table.
3. Execution Node Table
- This table stores information about available execution nodes where jobs can be executed.
- It includes details such as the node ID, node name, IP address, node status (available, busy), and any other relevant metadata.
- For example, when a new execution node is added to the system or an existing node’s status changes, the details are updated in this table.
4. Job Execution Log Table
- This table stores logs of job execution events and statuses.
- It includes the execution log ID, job ID (which references the Job Definition Table), execution node ID (which references the Execution Node Table), execution status (started, completed, failed), start time, end time, and any other relevant metadata or logs.
- For example, when a job execution starts, completes, or fails, the details of that execution are recorded in this table.
5. Resource Allocation Table
- This table stores information about resource allocations for each job execution.
- It includes details such as the allocation ID, job ID (which references the Job Definition Table), execution node ID (which references the Execution Node Table), start time, end time, and any other relevant metadata.
- For example, when resources are allocated to execute a job on a specific node, the details of that allocation are recorded in this table.
6. Job Retry Table
- This table stores information about job retries and retry attempts.
- It includes details such as the retry ID, job ID (which references the Job Definition Table), retry attempt number, retry status (success, failed), retry time, and any other relevant metadata.
- For example, when a job fails and needs to be retried, the details of the retry attempt are recorded in this table.
7. User Table
- This table stores information about system users who submit jobs.
- It includes details such as the user ID, username, email, hashed password, and any other relevant user details.
- For example, when a new user is registered in the system or an existing user’s details are updated, the information is stored in this table
Microservices and API Used for Distributed Job Scheduler
In a job scheduler designed for distributed systems, a microservices architecture offers scalability, flexibility, and modularity. It achieves this by splitting the system into independent, smaller services, each handling specific tasks. These services communicate through clearly defined APIs (Application Programming Interfaces). Here’s a rundown of the microservices and APIs in such a system:
1. Job Management Microservice:
- Responsible for managing job definitions, scheduling, and execution.
- Exposes APIs for creating, updating, and deleting job definitions, scheduling jobs, and monitoring job execution.
Example APIs:
/jobs/create: Create a new job definition.
/jobs/schedule: Schedule a job for execution.
/jobs/status: Get the status of a job.
2. Execution Node Microservice:
Manages the registration, status, and availability of execution nodes.
Exposes APIs for registering new nodes, updating node status, and querying node information.
Example APIs:
/nodes/register: Register a new execution node.
/nodes/update-status: Update the status of an execution node.
/nodes/list: Get a list of all registered nodes.
3. Resource Management Microservice:
Handles resource allocation and deallocation for job execution.
Exposes APIs for allocating resources to jobs, releasing resources, and monitoring resource usage.
Example APIs:
/resources/allocate: Allocate resources for job execution.
/resources/release: Release allocated resources.
/resources/usage: Get resource usage statistics.
4. Authentication and Authorization Microservice:
- Manages user authentication and authorization.
- Handles user authentication, authorization checks for accessing protected resources, and token generation.
Example APIs:
/auth/login: Authenticate a user and generate an access token.
/auth/authorize: Authorize user access to protected resources.
/auth/logout: Log out a user and invalidate the access token.
5. Logging and Monitoring Microservice:
- Collects and aggregates logs and metrics from various components of the system.
- Provides APIs for querying logs, retrieving metrics, and setting up monitoring alerts.
Example APIs:
/logs/query: Query system logs based on filters.
/metrics/get: Get system performance metrics.
/alerts/setup: Set up monitoring alerts based on predefined conditions.
Scalability for Distributed Job Scheduler
- Adds more machines to handle increased workload.
- In a job scheduler system, this means deploying more nodes to manage more jobs.
- Load balancers distribute job requests evenly across nodes to prevent bottlenecks.
- Allows the system to process more jobs using multiple nodes’ computing power.
- Increase the power of individual servers (nodes) by upgrading hardware (e.g., CPU, memory, storage).
- Focuses on boosting the capacity of existing nodes, unlike horizontal scaling which adds more nodes.
- Suitable for handling demanding jobs in a job scheduler system that need a lot of processing or memory.
- Execution nodes can be upgraded with faster processors, more memory, or quicker storage to enhance job performance.
3. Elasticity
- Elasticity allows a system to adjust its resources (e.g., servers) based on changes in workload.
- In cloud computing, auto-scaling features can automatically add or remove servers according to specific rules.
- For instance, if the system has too many pending tasks, it can automatically add more servers to handle the workload. Similarly, when the workload is low, it can remove unused servers to reduce costs.
- Elasticity helps systems respond to changing workload patterns in real-time, making them more efficient and cost-effective.
4. Database Scaling
As the system expands, the database can become an obstacle to scaling. This is particularly true if it manages a substantial amount of job descriptions, scheduling details, and execution records. To enhance database scalability, techniques like sharding, replication, and partitioning can be used. These approaches help distribute data across various database instances or clusters.
- Partitioning the database into smaller shards is what sharding involves. Storing a subset of data, each shard does.
- This subdivides the workload for the database. Improved read throughput, it yields. Write throughput also increases.
- Replication involves creating copies of the database across multiple servers to improve fault tolerance and read scalability. Read operations can be distributed among replicas to handle read-heavy workloads efficiently.
- Partitioning involves dividing large tables into smaller partitions based on certain criteria (e.g., range-based or hash-based partitioning). This can improve query performance and reduce contention on individual database partitions.
- Storing commonly used data in a temporary storage container (cache) helps lighten the workload on the main systems and improves the system’s overall performance.
- In job scheduling systems, caches can store job definitions, scheduling information, and results.
- Caches can be built using tools like Redis or Memcached, which quickly retrieve frequently requested data when needed.
- By storing data in caches at different levels within the system (like the app or database), the system can reduce delays and handle more requests without overwhelming the main parts of the system.
Share your thoughts in the comments
Please Login to comment...