Database replication is a crucial concept in system design, especially for ensuring data availability, reliability, and scalability. It involves creating and maintaining multiple copies of a database across different servers to enhance performance and fault tolerance. In this article, we will delve into the fundamentals of database replication, its various types, and its importance in system design.

Important Topics for the Database Replication in System Design
What is Database Replication?
Database replication involves creating and maintaining duplicate copies of a database on different servers. It is crucial for enhancing data availability, reliability, and scalability in modern systems.
- By replicating data across multiple servers, organizations can ensure that their data remains accessible even if one server fails.
- This redundancy also improves data reliability, as there are multiple copies available to restore data in case of corruption or loss.
- Additionally, database replication can help distribute the workload among servers, improving performance and scalability.
Why do we need Database Replication?
Database replication is important for several reasons:
- High Availability: Replication ensures that data is available even if one or more servers fail. By maintaining copies of data on multiple servers, applications can continue to operate without interruption.
- Disaster Recovery: Replication provides a means to recover data in the event of a disaster. By having copies of data stored in different locations, organizations can quickly restore operations after a disaster.
- Load Balancing: Replication allows for distributing read queries across multiple servers, reducing the load on any single server and improving performance.
- Fault Tolerance: Replication improves fault tolerance by ensuring that if one server fails, another can take over with minimal disruption.
- Scalability: Replication can improve scalability by allowing for the distribution of write operations across multiple servers, reducing the load on any single server.
- Data Locality: Replication can be used to bring data closer to users, reducing latency and improving the user experience.
Database replication is like making copies of your important documents so you have backups in case something happens to the original. There are different ways to make these copies, like having one main copy (master) that gets updated and then making copies (slaves) of that updated version. Another way is to have multiple main copies (masters) that can all be updated and share those updates with each other.
Let’s understand the different types of database replication:
1. Master-Slave Replication
Master-slave replication is a method used to copy and synchronize data from a primary database (the master) to one or more secondary databases (the slaves).
- In this setup, the master database is responsible for receiving all write operations, such as inserts, updates, and deletes.
- The changes made to the master database are then replicated to the slave databases, which maintain a copy of the data.

Real-World Example of Master-Slave Replication
Imagine a library with two branches
- Master branch: This is the main library with the original and constantly updated collection of books.
- Slave branch: This is a smaller branch that receives copies of new books from the master branch at regular intervals. Students can only borrow books that are physically present in the slave branch.
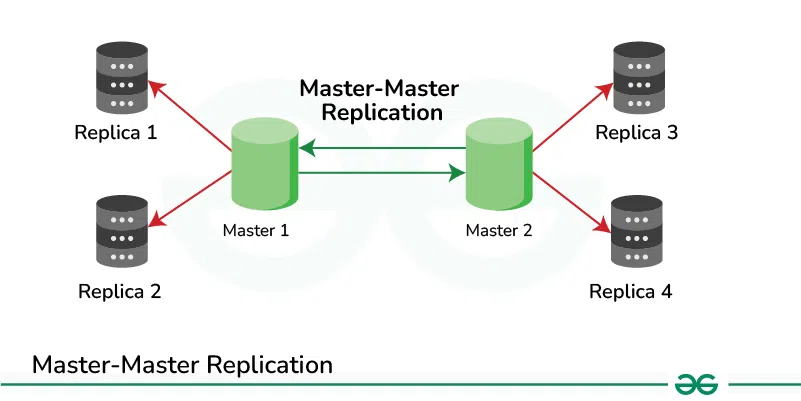
2. Master-Master Replication
Master-master replication, also known as bidirectional replication, is a setup in which two or more databases are configured as master databases, and each master can accept write operations. This means that changes made to any master database are replicated to all other master databases in the configuration.
- In master-master replication, communication occurs bidirectionally between the master databases.
- When a write operation is performed on one master database, that change is replicated to all other master databases.
- If conflicting writes occur on different master databases, conflict resolution mechanisms are needed to ensure data consistency.
Real-World Example of Master-Master Replication
Imagine two highly trained air traffic controllers managing air traffic in a busy airspace
- Each controller has a designated sector and full authority to direct planes within their zone.
- They constantly communicate and share information to ensure flight paths don’t conflict, maintaining overall airspace safety.
- If one controller becomes unavailable, the other can seamlessly take over responsibility for both sectors, guaranteeing uninterrupted traffic flow.
3. Snapshot Replication
Snapshot replication is a method used in database replication to create a copy of the entire database at a specific point in time and then replicate that snapshot to one or more destination servers. This is typically done for reporting, backup, or distributed database purposes.

Real-World Example of Master-Slave Replication
Imagine taking a photo of a messy room (database) at a specific time
- The snapshot captures the state of the room (database) at that exact moment.
- You can use the snapshot to restore the room (database) to its previous state if needed.
4. Transactional Replication
Transactional replication is a method for keeping multiple copies of a database synchronized in real-time.
- This means that any changes made to a specific table (or set of tables) in one database, called the publisher, are immediately replicated to other databases, called subscribers.
- This ensures that all copies of the data are identical at any given moment, providing data consistency across multiple locations.
.webp)
Real-World Example of Transactional Replication
Picture a live stock market with constantly changing prices
- Every price change (transaction) is immediately broadcasted to all connected screens (replicas).
- Everyone sees the same price updates in real-time.
5. Merge Replication
Merge replication is a database synchronization method allowing both the central server (publisher) and its connected devices (subscribers) to make changes to the data, resolving conflicts when necessary.
This definition captures the key essence of merge replication in a concise and accurate way, highlighting its two main characteristics:
- Two-way synchronization: Unlike transactional replication, where updates flow primarily from the publisher to subscribers, merge replication allows bidirectional data flow. This means both the central server and devices can modify the data,even when offline.
- Conflict resolution: With multiple parties editing the same data, conflicts are bound to occur. Merge replication employs pre-defined rules or user interventions to resolve conflicting changes, ensuring data consistency across all copies.

Real-World Example of Master-Slave Replication
Imagine a team working on a shared document (database) in Google Docs
- Team members can edit the document offline (locally) and their changes are saved temporarily.
- When they connect online, their changes are merged with the main document, resolving any conflicts.
Database replication strategies define how data is selected, copied, and distributed across databases to achieve specific goals such as scalability, availability, or efficiency. Here are some common database replication strategies:
1. Full Replication
Full replication, also known as whole database replication, is a strategy where the entire database is replicated to one or more destination servers. This means that all tables, rows, and columns in the database are copied to the destination servers, ensuring that the replicas have an exact copy of the original database.
For Example:
An e-commerce website uses full replication to replicate its entire product catalog and customer database to multiple servers. This ensures that all product information and customer data are available on all servers, providing high availability and fault tolerance.

2. Partial Replication
Partial replication is a strategy where only a subset of the database is replicated, such as specific tables, rows, or columns, rather than replicating the entire database. This approach allows for more efficient use of resources and can be beneficial when only certain data needs to be replicated for reporting, analysis, or other purposes.
For Example:
A financial institution replicates only the most frequently accessed customer account information to a secondary database for reporting purposes. This reduces the resource requirements of replication by replicating only the most critical data.

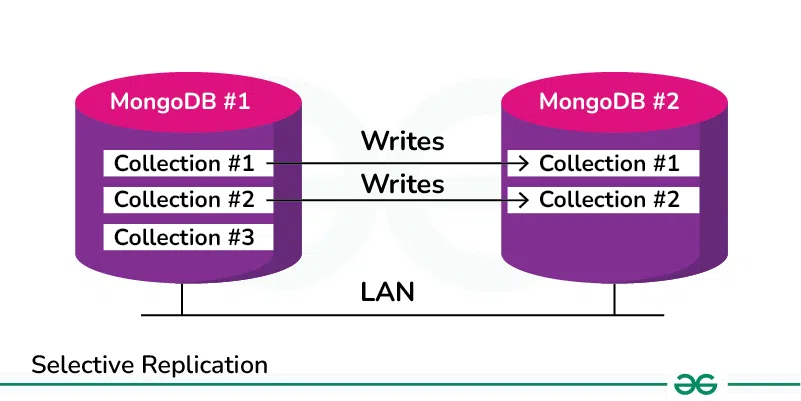
3. Selective Replication
Selective replication is a database replication strategy that involves replicating data based on predefined criteria or conditions. Unlike full replication, which replicates the entire database, or partial replication, which replicates a subset of the database, selective replication allows for more granular control over which data is replicated. This can be useful in scenarios where only specific data needs to be replicated to reduce resource requirements and improve efficiency.
For Example:
A social media platform replicates only the posts and comments that have been liked or shared by a large number of users to a secondary database. This reduces the amount of data transferred and stored on the replicas by replicating only the most relevant or important data.
Sharding is a database scaling technique that involves partitioning data across multiple database instances (shards) based on a key. This approach allows for distributing the workload and data storage across multiple servers, improving scalability and performance. Sharding is commonly used in environments where a single database server is unable to handle the load or storage requirements of the application.
For Example:
An online gaming company shards its user database based on geographic location, with each shard responsible for users in a specific region. This improves scalability by distributing the workload and data storage across multiple servers.

5. Hybrid Replication
Hybrid replication is a database replication strategy that combines multiple replication techniques to achieve specific goals. This approach allows for the customization of replication methods based on the requirements of different parts of the database or application.
For Example:
A healthcare organization uses a hybrid replication approach to replicate patient records. It uses full replication for critical patient data that requires high availability and partial replication for less critical data that is only accessed occasionally.
Database replication can be configured and operated in different modes or configurations to achieve specific goals related to data consistency, availability, and performance.
- Synchronous replication
- Asynchronous replication
- Semi-synchronous replication
1. Synchronous Replication Configuration
Synchronous replication is a database replication method in which data changes are replicated to one or more replicas in real-time, and the transaction is not considered committed until at least one replica has acknowledged receiving the changes. This method ensures that the primary database and its replicas are always in sync, providing a high level of data consistency.
For Example:
Banking application uses synchronous replication to ensure that all transactions are replicated to a secondary database in real-time for data consistency and disaster recovery purposes.

2. Asynchronous Replication Configuration
Asynchronous replication is a database replication method in which data changes are replicated to one or more replicas after they are made on the primary database, without waiting for acknowledgment from the replicas.
- This method allows for faster transaction processing on the primary database, but it can result in a slight delay in data consistency between the primary and replica(s)
- As changes made to the primary database do not always replicate to the replica databases in asynchronous replication, which is a type of database replication.
For Example:
An e-commerce website uses asynchronous replication to replicate product inventory data from the primary database to a secondary database for reporting and analysis purposes.

3. Semi-synchronous Replication Configuration
Semi-synchronous replication is a database replication method that combines aspects of synchronous and asynchronous replication.
- In semi-synchronous replication, data changes are replicated to at least one replica synchronously, ensuring strong data consistency for critical data, while other replicas are updated asynchronously for better performance.
- This approach provides a balance between strong data consistency and improved performance.
For Example :
A financial institution uses semi-synchronous replication for its transaction processing system.
- When a customer initiates a funds transfer transaction, the transaction is processed on the primary database.
- The changes made by the transaction are replicated synchronously to at least one replica to ensure strong data consistency for critical financial data. Other replicas are updated asynchronously to improve performance.

What Factors to consider when choosing a Replication Configuration?
When choosing a replication configuration for your database system, several key factors should be considered to ensure that the selected configuration meets your requirements. Here are some important factors to consider:
- Data Consistency Requirements:
- Consider the level of data consistency required for your application.
- Synchronous replication provides strong consistency but may impact performance
- While asynchronous replication offers better performance but may result in eventual consistency.
- Performance Requirements:
- Evaluate the performance impact of the replication configuration on your database system.
- Synchronous replication may introduce latency due to waiting for acknowledgments, while asynchronous replication can improve performance but may result in data lag.
- Network Bandwidth and Latency:
- Consider the available network bandwidth and latency between the primary database and its replicas.
- Synchronous replication requires more bandwidth and is sensitive to latency, while asynchronous replication is more tolerant of network issues.
- Failover and High Availability:
- Determine how quickly your system needs to recover from failures.
- Synchronous replication provides immediate failover capabilities but may have higher latency, while asynchronous replication may have a delay in failover but can offer better performance.
- Data Loss Tolerance:
- Assess the tolerance for potential data loss in your application.
- Synchronous replication minimizes data loss but may impact performance, while asynchronous replication may result in data loss in case of a failure.
Benefits of Database Replication
Database replication offers numerous benefits, including high availability, improved performance, disaster recovery capabilities, scalability, and load balancing.
- High Availability: Database replication provides redundancy, ensuring that if one database server fails, another can take over, minimizing downtime and ensuring continuous availability of data.
- Improved Performance: By distributing read queries across multiple replicas, database replication can improve read performance, as each replica can handle a portion of the workload.
- Disaster Recovery: Replicated data can be used for disaster recovery purposes, ensuring that data is protected and can be restored in the event of a disaster.
- Scalability: Database replication can help scale read operations by distributing them across multiple replicas, allowing for better performance as the workload increases.
- Load Balancing: Replication can be used for load balancing, distributing write operations across multiple servers to prevent any single server from becoming a bottleneck.
Challenges of Database Replication
Despite its benefits, database replication also poses several challenges, such as ensuring data consistency, managing complexity, addressing cost considerations, resolving conflicts, and dealing with latency.
- Data Consistency: Maintaining consistency between replicas can be challenging, especially in asynchronous replication scenarios where there may be a delay in replicating data.
- Complexity: Database replication adds complexity to the system, requiring careful configuration and management to ensure that data is replicated correctly and efficiently.
- Cost: Setting up and maintaining a replicated database environment can be costly, especially for large-scale deployments with multiple replicas.
- Conflict Resolution: In multi-master replication scenarios, conflicts may arise when the same data is modified on different replicas simultaneously, requiring conflict resolution mechanisms.
- Latency: Synchronous replication, which requires acknowledgment from replicas before committing transactions, can introduce latency and impact the performance of the primary database.
Share your thoughts in the comments
Please Login to comment...