Date’s Twelve Rules for Distributed Database Systems
Last Updated :
24 Dec, 2021
Distributed databases brings advantages of distributed computing which consists huge number of processing elements, elements may be heterogeneous. Elements are connected with network which help in performing the assigned task. Basically, it is used to solve problem by distributing it into number of smaller problems and solve smaller problems in coordinated way.
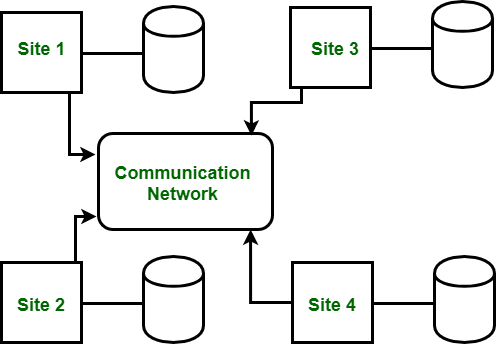
Distributed DBMS is single logical database which is spread physically across computers in multiple computers that are connected by various data communication links. It can defined as the database which is consist of collection of data with different parts which is under control of separate Database which is running on independent computer and connected by data communication links.
It is kind of virtual database because in this component parts are physically stored in number of distinct databases at number of distinct locations. In this database, distribution and transaction both are transparent. By transparent distribution we mean, user can access data anywhere over network if it’s data is stored at it’s own location. By transparent transaction we mean, transaction are divided into sub-transactions must maintain database integrity under multiple database. Software which help in making distributed database and also provides access which help in making distribution transparent to user is called Distributed Database Management System.
Date’s Twelve Rules for Distributed Database Systems :
The discussion about DDBMS is incomplete without discussing DATE’S TWELVE RULES. DBMS which follows that rules is purely distributed DBMS.
The rules are as follows :
- Local Autonomy or Local Site Independence –
Each site has its own operations and also act as independent autonomous, centralized DBMS. For security, concurrency control, backup and recovery there is responsibility of each site..
- Central Site Independence –
All the sites are equal and no site is dependent on central site to perform any service. We can say there is no such site which cannot which system cannot operate. There are some services for which central server is not required they are transaction management, query optimization, deadlock detection and management of global system catalog.
- Continuous Operation –
There is no affect of site failure to system. System continue it’s operation even in case of site failure or any expansion in network.
- Local Independence –
To retrieve any data in system, there is need to know about the storage of data i.e where the data is stored in system.
- Fragmentation Independence –
The user is able to see only one single logical database. There is transparency to data fragmentation to user. To retrieve any fragments of database, there is no need to know about name of database fragments.
- Replication Independence –
Data can be replicate and stored in different sites. The DDBMS is manages all fragments transparently the user.
- Distributed Query Independence –
To execute single query at different location, does not able to satisfy transparent request. So, query optimization is crucial and performed transparently by DDBMS.
- Distributed Transaction Independence –
Transaction is able to update data at different sites transparently, but control of recovery and concurrency is achieved by using agents.
- Hardware Independence –
It should be possible for DDBMS to run on different hardware platforms.
- Operating System Independence –
It should be possible for DDBMS to run on different Operating system platforms.
- Network Independence –
The DDBMS system is able to run on any network platform.
- Database Independence –
The system must support any vendor of the database product.
Share your thoughts in the comments
Please Login to comment...