Data Science VS Machine Learning
Last Updated :
03 Jan, 2024
In the 21st Century, two terms “Data Science” and “Machine Learning” are some of the most searched terms in the technology world. From 1st-year Computer Science students to big Organizations like Netflix, Amazon, etc are running behind these two techniques. And they also got the reason. In the world of data space, the era of Big Data emerged when organizations were dealing with petabytes and exabytes of data. It became very tough for industries to store the data until 2010. When popular frameworks like Hadoop and others solve the problem of storage, the focus is on processing the data. And here Data Science and Machine Learning play a big role. But How much data is Big Data?

- Google processes 20 Petabytes(PB) per day (2008)
- Facebook has 2.5 PB of user data + 15 TB per day (2009)
- eBay has 6.5 PB of user data + 50 TB per day (2009)
- CERN’s Large Hadron Collider(LHC) generates 15 PB a year
But in general what makes these two terms different? What are the big differences between these two techniques? So let’s erase the confusion with a simple Venn diagram which is very popular and known as Drew Conway’s Venn Diagram. Before that let’s have a look at the definition of these two terms.
In this article, we will discuss about the difference between Data Science & ML
Data Science
It is the complex study of the large amounts of data in a company or organization’s repository. This study includes where the data has originated from, the actual study of its content matter, and how this data can be useful for the growth of the company in the future. The data relating to an organization is always in two forms: Structured or unstructured. When we study this data, we get valuable information about business or market patterns which helps the business have an edge over the other competitors since they’ve increased their effectiveness by recognizing patterns in the data set.
Data scientists are specialists who excel in converting raw data into critical business matters. These scientists are skilled in algorithmic coding along with concepts like data mining, machine learning, and statistics. Data science is used extensively by companies like Amazon, Netflix, the healthcare sector, in the fraud detection sector, internet search, airlines, etc.
Machine Learning
Machine Learning is a field of study that gives computers the capability to learn without being explicitly programmed. Machine Learning is applied using Algorithms to process the data and get trained for delivering future predictions without human intervention. The inputs for Machine Learning are the set of instructions or data or observations. Machine Learning is used extensively by companies like Facebook, Google, etc.
What Makes These Two Techniques Different?
Below is the Drew Conway’s Venn Diagram. Let’s have a look at the Venn Diagram.
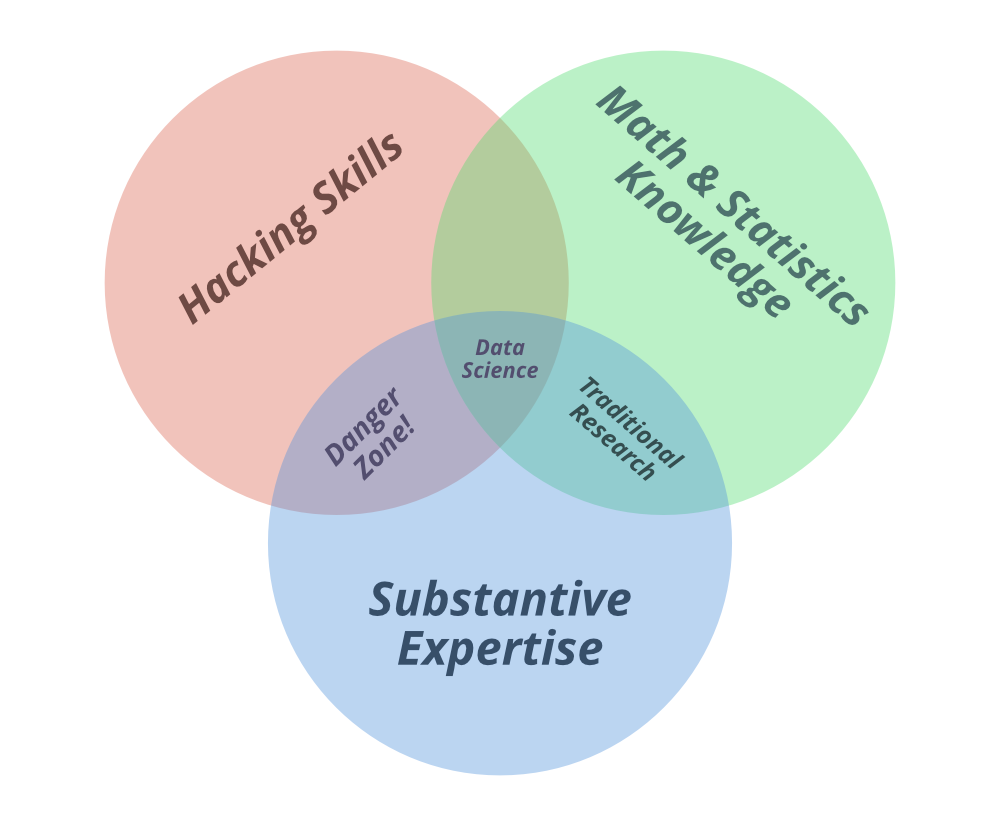
You can see the two terms “Data Science” and “Machine Learning” in the above Venn diagram. So let’s understand the diagram. In Drew Conway’s Venn Diagram of Data Science, the primary colors of data are
- Hacking Skills,
- Math and Statistics Knowledge, and
- Substantive Expertise
But the question is why has he highlighted these three? So let’s understand the term why!!
Hacking Skills: It is known to everyone that data is the key part of data science. And data is a commodity traded electronically; so, in order to be in this market, “one needs to speak hacker”. So what does this line means? Being able to manage text files at the command-line, learning vectorized operations, thinking algorithmically; are the hacking skills that make for a successful data hacker.
Math and Statistics Knowledge: Once you have collected and cleaned the data, the next step is to actually obtain insight from it. In order to do this, you need to use appropriate mathematical and statistical methods, that demand at least a baseline familiarity with these tools. This is not to say that a Ph.D. in statistics is required to be a skilled data scientist, but it does need understanding what an ordinary least squares regression is and how to explain it.
Substantive Expertise: The third important part is Substantive expertise. And this is where our confusion erases. Yes!!
According to Drew Conway, “Data plus Math and Statistics Knowledge only gets you Machine Learning”, which is excellent if that is what you are interested in, but not if you are doing Data Science. Science is about experimentation and building knowledge, which demands some motivating questions about the world and hypotheses that can be brought to data and tested with statistical methods.
And this is the main difference point between these two terms. If you want to a Data Scientist then you must have knowledge in that Domain Area. But Why? The foremost objective of data science is to extract useful insights from that data so that it can be profitable to the company’s business. If you are not aware of the business side of the company that how the business model of the company works and how you can’t build it better than you are of no use to this company. You need to know how to ask the right questions from the right people so that you can perceive the appropriate information you need to obtain the information you need. Below is a complete table of differences between Data Science and Machine Learning.
Difference Between Data Science and Machine Learning
| 1. |
Data Science is a field about processes and systems to extract data from structured and semi-structured data. |
Machine Learning is a field of study that gives computers the capability to learn without being explicitly programmed. |
| 2. |
Need the entire analytics universe. |
Combination of Machine and Data Science. |
| 3. |
Branch that deals with data. |
Machines utilize data science techniques to learn about the data. |
| 4. |
Data in Data Science maybe or maybe not evolved from a machine or mechanical process. |
It uses various techniques like regression and supervised clustering.
|
| 5. |
Data Science as a broader term not only focuses on algorithms statistics but also takes care of the data processing. |
But it is only focused on algorithm statistics. |
| 6. |
It is a broad term for multiple disciplines. |
It fits within data science. |
| 7. |
Many operations of data science that is, data gathering, data cleaning, data manipulation, etc. |
It is three types: Unsupervised learning, Reinforcement learning, Supervised learning. |
| 8. |
Example: Netflix uses Data Science technology. |
Example: Facebook uses Machine Learning technology. |
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...