According to the Harvard Business Review, Data Scientist is “The Sexiest Job of the 21st Century”. Is this not enough to know more about data science!
Course Objectives:
1. To provide the students with the basic knowledge of Data Science.
2. To make the students develop solutions using Data Science tools.
3. To introduce them to Python packages and their usability.
Course Outcomes:
1. Study basics of data science and its scope.
2. Describe basics of data science process and recognize common tools used for Data Science application development.
3. Explore functions of Python libraries & packages.
4. Apply data science concepts and methods to find solution to real-world problems and will communicate these solutions effectively.
Introduction
In the world of data space, the era of Big Data emerged when organizations are dealing with petabytes and exabytes of data. It became very tough for industries for the storage of data until 2010. Now when the popular frameworks like Hadoop and others solved the problem of storage, the focus is on processing the data. And here Data Science plays a big role. Nowadays the growth of data science has been increased in various ways and so on should be ready for the future by learning what data science is and how can we add value to it.
What is Data Science?
So now the very first question arises is, “What is Data Science?” Data science means different things for different people, but at its gist, data science is using data to answer questions. This definition is a moderately broad definition, and that’s because one must say data science is a moderately broad field!
Data science is the science of analyzing raw data using statistics and machine learning techniques with the purpose of drawing conclusions about that information.
So briefly it can be said that Data Science involves:
- Statistics, computer science, mathematics
- Data cleaning and formatting
- Data visualization
Key Pillars of Data Science
Usually, data scientists come from various educational and work experience backgrounds, most should be proficient in, or in an ideal case be masters in four key areas.
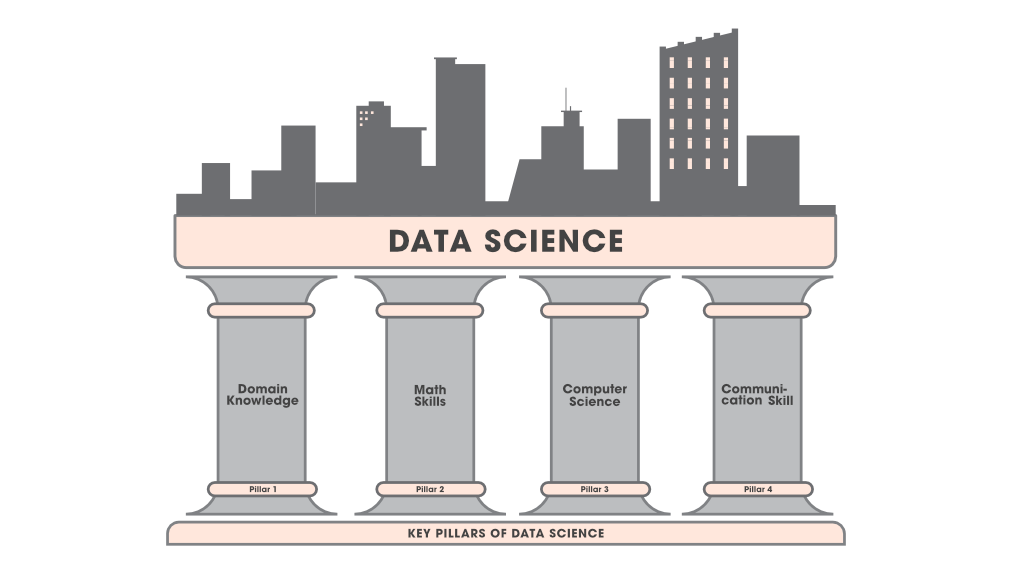
Pillar of data science
- Domain Knowledge:
- Most people thinking that domain knowledge is not important in data science but it is essential. The foremost objective of data science is to extract useful insights from that data so that it can be profitable to the company’s business. If you are not aware of the business side of the company that how the business model of the company works and how you can’t build it better than you are of no use for this company.
- You need to know how to ask the right questions from the right people so that you can perceive the appropriate information you need to obtain the information you need. There are some visualization tools used on the business end like Tableau that help you display your valuable results or insights in a proper non-technical format such as graphs or pie charts that business people can understand.
- Math Skills:
- Linear Algebra, Multivariable Calculus & Optimization Technique: These three things are very important as they help us in understanding various machine learning algorithms that play an important role in Data Science.
- Statistics & Probability: Understanding of Statistics is very significant as this is a part of Data analysis. Probability is also significant to statistics and it is considered a prerequisite for mastering machine learning.
- Computer Science:
- Programming Knowledge: One needs to have a good grasp of programming concepts such as Data structures and Algorithms. The programming languages used are Python, R, Java, Scala. C++ is also useful in some places where performance is very important.
- Relational Databases: One needs to know databases such as SQL or Oracle so that he/she can retrieve the necessary data from them whenever required.
- Non-Relational Databases: There are many types of non-relational databases but mostly used types are Cassandra, HBase, MongoDB, CouchDB, Redis, Dynamo.
- Machine Learning: It is one of the most vital parts of data science and the hottest subject of research among researchers so each year new advancements are made in this. One at least needs to understand basic algorithms of Supervised and Unsupervised Learning. There are multiple libraries available in Python and R for implementing these algorithms.
- Distributed Computing: It is also one of the most important skills to handle a large amount of data because one can’t process this much data on a single system. The tools that mostly used are Apache Hadoop and Spark. The two major parts of these tolls are HDFS(Hadoop Distributed File System) that is used for collecting data over a distributed file system. Another part is map-reduce, by which we manipulate the data. One can write map-reduce in programs in Java or Python. There are various other tools such as PIG, HIVE, etc.
- Communication Skill:
- It includes both written and verbal communication. What happens in a data science project is after drawing conclusions from the analysis, the project has to be communicated to others. Sometimes this may be a report you send to your boss or team at work. Other times it may be a blog post. Often it may be a presentation to a group of colleagues. Regardless, a data science project always involves some form of communication of the projects’ findings. So it’s necessary to have communication skills for becoming a data scientist.
Who is a Data Scientist?
So we’ve discussed what data science is and the key pillars of data science, but something else we need to talk about is who precisely a data scientist is? An Economist Special Report says that a data scientist is defined as someone:
“who integrates the skills of software programmer, statistician and storyteller slash artist to extract the nuggets of gold hidden under mountains of data”
But now the question arises, what skills do a data scientist embody? And to answer this, let’s discuss the popular Venn diagram Drew Conway’s Venn diagram of data science in which data science is the intersection of three sectors – Substantive expertise, hacking skills, and math & statistics knowledge.
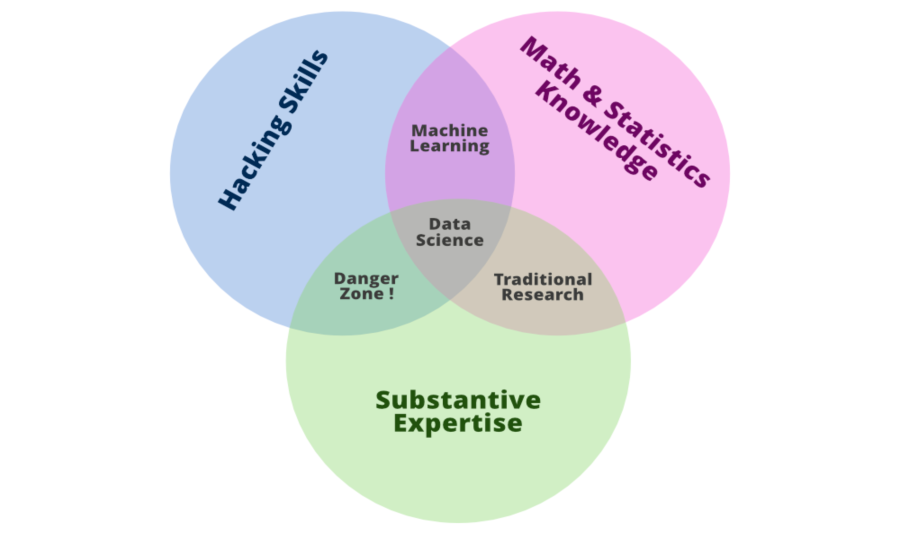
Let’s explain a little what we mean by this Venn diagram, we know that we use data science to answer questions – so first, we need to have enough experience in the area that we desire to ask about in order to express the questions and to understand what kinds of data are relevant to reply that question. Once we have our question and relevant data, we understand from the kinds of data that data science operates with, often times it needs to undergo significant cleaning and formatting – and this often takes computer programming skills. Finally, once we have the data, we need to analyze it, and this often takes math and stats knowledge.
Roles & Responsibilities of a Data Scientist:
- Management: The Data Scientist plays an insignificant managerial role where he supports the construction of the base of futuristic and technical abilities within the Data and Analytics field in order to assist various planned and continuing data analytics projects.
- Analytics: The Data Scientist represents a scientific role where he plans, implements, and assesses high-level statistical models and strategies for application in the business’s most complex issues. The Data Scientist develops econometric and statistical models for various problems including projections, classification, clustering, pattern analysis, sampling, simulations, and so forth.
- Strategy/Design: The Data Scientist performs a vital role in the advancement of innovative strategies to understand the business’s consumer trends and management as well as ways to solve difficult business problems, for instance, the optimization of product fulfillment and entire profit.
- Collaboration: The role of the Data Scientist is not a solitary role and in this position, he collaborates with superior data scientists to communicate obstacles and findings to relevant stakeholders in an effort to enhance drive business performance and decision-making.
- Knowledge: The Data Scientist also takes leadership to explore different technologies and tools with the vision of creating innovative data-driven insights for the business at the most agile pace feasible. In this situation, the Data Scientist also uses initiative in assessing and utilizing new and enhanced data science methods for the business, which he delivers to senior management of approval.
- Other Duties: A Data Scientist also performs related tasks and tasks as assigned by the Senior Data Scientist, Head of Data Science, Chief Data Officer, or the Employer.
Difference between Data Scientist, Data Analyst, and Data Engineer:
Data Scientist, Data Engineer, and Data Analyst are the three most common careers in data science. So let’s understand who’s a data scientist by comparing it with its similar jobs.
|
Data Scientist
|
Data Analyst
|
Data Engineer
|
| The focus will be on the futuristic display of data. |
The main focus of a data analyst is on optimization of scenarios, for example how an employee can enhance the company’s product growth. |
Data Engineers focus on optimization techniques and the construction of data in a conventional manner. The purpose of a data engineer is continuously advancing data consumption. |
| Data scientists present both supervised and unsupervised learning of data, say regression and classification of data, Neural networks, etc. |
Data formation and cleaning of raw data, interpreting and visualization of data to perform the analysis and to perform the technical summary of data. |
Frequently data engineers operate at the back end. Optimized machine learning algorithms were used for keeping data and making data to be prepared most accurately. |
| Skills required for Data Scientist are Python, R, SQL, Pig, SAS, Apache Hadoop, Java, Perl, Spark. |
Skills required for Data Analyst are Python, R, SQL, SAS. |
Skills required for Data Engineer are MapReduce, Hive, Pig Hadoop, techniques. |
Some Inspiring Data Scientists
The variety of areas in which data science is used is embodied by looking at examples of data scientists.
- Hilary Mason: She is the co-founder of FastForward labs, a machine learning company recently owned by Cloudera, a data science company. She is a Data Scientist at Accel. Broadly, she works with data to solve questions about mining the web and also learning the method that how people communicate with each other through social media.
- Nate Silver: He is one of the most prominent data scientists or statisticians in the world today. He is the founder of FiveThirtyEight. FiveThirtyEight is a website that applies statistical analysis to tell compelling stories about elections, politics, sports, science, and lifestyle. He utilizes huge amounts of public data to predict a diversity of topics; most prominently he predicts who will win elections in the U.S. and has an extraordinary track record for accuracy in doing so.
- Daryl Morey: He is the general manager of a US basketball team, the Houston Rockets. He was awarded the job as GM based on his bachelor’s degree in computer science and his M.B.A. from M.I.T.
Data science is about extracting knowledge and insights from data. The tools and techniques of data science are used to drive business and process decisions.
Data Science Processes:
1.Setting the Research Goal
2.Retrieving Data
3.Data Preparation
4.Data Exploration
5.Data Modeling
6.Presentation and Automation
1.Setting the research goal:
Data science is mostly applied in the context of an organization. When the business asks you to perform a data science project, you’ll first prepare a project charter. This charter contains information such as what you’re going to research, how the company benefits from that, what data and resources you need, a timetable, and deliverables.
2. Retrieving data:
The second step is to collect data. You’ve stated in the project charter which data you need and where you can find it. In this step you ensure that you can use the data in your program, which means checking the existence of, quality, and access to the data. Data can also be delivered by third-party companies and takes many forms ranging from Excel spreadsheets to different types of databases.
3. Data preparation:
Data collection is an error-prone process; in this phase you enhance the quality of the data and prepare it for use in subsequent steps. This phase consists of three subphases: data cleansing removes false values from a data source and inconsistencies across data sources, data integration enriches data sources by combining information from multiple data sources, and data transformation ensures that the data is in a suitable format for use in your models.
4. Data exploration:
Data exploration is concerned with building a deeper understanding of your data. You try to understand how variables interact with each other, the distribution of the data, and whether there are outliers. To achieve this, you mainly use descriptive statistics, visual techniques, and simple modeling. This step often goes by the abbreviation EDA, for Exploratory Data Analysis.
5. Data modeling or model building:
In this phase you use models, domain knowledge, and insights about the data you found in the previous steps to answer the research question. You select a technique from the fields of statistics, machine learning, operations research, and so on. Building a model is an iterative process that involves selecting the variables for the model, executing the model, and model diagnostics.
6.Presentation and automation:
Finally, you present the results to your business. These results can take many forms, ranging from presentations to research reports. Sometimes you’ll need to automate the execution of the process because the business will want to use the insights you gained in another project or enable an operational process to use the outcome from your model.
Knowledge and Skills for Data Science Professionals:
• Statistical / mathematical reasoning.
• Business communication/leadership.
• Programming.
1. Statistics:
Wikipedia defines it as the study of the collection, analysis, interpretation, presentation, and organization of data. Therefore, it shouldn’t be a surprise that data scientists need to know statistics.
For example, data analysis requires descriptive statistics and probability theory, at a minimum. These concepts will help you make better business decisions from data.
2. Programming Language R/ Python:
Python and R are one of the most widely used languages by Data Scientists. The primary reason is the number of packages available for Numeric and Scientific computing.
3. Data Extraction, Transformation, and Loading:
Suppose we have multiple data sources like MySQL DB, MongoDB, Google Analytics. You have to Extract data from such sources, and then transform it for storing in a proper format or structure for the purposes of querying and analysis. Finally, you have to load the data in the Data Warehouse, where you will analyze the data. So, for people from ETL (Extract Transform and Load) background Data Science can be a good career option.
4. Data Wrangling and Data Exploration:
Cleaning and unify the messy and complex data sets for easy access and analysis this is termed as Data Wrangling. Exploratory Data Analysis (EDA) is the first step in your data analysis process. Here, you make sense of the data you have and then figure out what questions you want to ask and how to frame them, as well as how best to manipulate your available data sources to get the answers you need.
5. Machine Learning:
Machine Learning, as the name suggests, is the process of making machines intelligent, that have the power to think, analyze and make decisions. By building precise Machine Learning models, an organization has a better chance of identifying profitable opportunities or avoiding unknown risks.
You should have good hands-on knowledge of various Supervised and Unsupervised algorithms.
6. Big Data Processing Frameworks:
Nowadays, most of the organizations are using Big Data analytics to gain hidden business insights. It is, therefore, a must-have skill for a Data Scientist.
Therefore, we require frameworks like Hadoop and Spark to handle Big Data.
Facets of data:
1.Structured
2.Semi structured
3. Unstructured
• Natural language
• Machine-generated
• Graph-based
• Audio, video, and images
• Streaming
1.Structured Data:
1.It concerns all data which can be stored in database SQL in table with rows and columns.
2.They have relational key and can be easily mapped into pre-designed fields.
3.Today, those data are the most processed in development and the simplest way to manage information.
4. But structured data represent only 5 to 10% of all informatics data.
2.Semi Structured Data:
1. Semi-structured data is information that doesn’t reside in a relational database but that does have some organizational properties that make it easier to analyze.
2. With some process you can store them in relation database (it could be very hard for some kind of semi structured data), but the semi structure exists to ease space, clarity or compute…
3.But as Structured data, semi structured data represents a few parts of data (5 to 10%).
Examples of semi-structured: JSON, CSV , XML documents are semi structured documents.
3.Unstructured data:
1.Unstructured data represent around 80% of data.
2. It often include text and multimedia content.
3.Examples include e-mail messages, word processing documents, videos, photos, audio files, presentations, webpages and many other kinds of business documents.
4.Unstructured data is everywhere.
5.In fact, most individuals and organizations conduct their lives around unstructured data.
6.Just as with structured data, unstructured data is either machine generated or human generated.
- Here are some examples of machine-generated unstructured data:
Satellite images: This includes weather data or the data that the government captures in its satellite surveillance imagery. Just think about Google Earth, and you get the picture.
Photographs and video: This include security, surveillance, and traffic video.
Radar or sonar data: This includes vehicular, meteorological, and Seismic oceanography.
- The following list shows a few examples of human-generated unstructured data:
Social media data: This data is generated from the social media platforms such as YouTube, Facebook, Twitter, LinkedIn, and Flickr.
Mobile data: This includes data such as text messages and location information.
website content: This comes from any site delivering unstructured content, like YouTube, Flickr, or Instagram.
i)Natural Language:
Natural language is a special type of unstructured data; it’s challenging to process because it requires knowledge of specific data science techniques and linguistics.
The natural language processing community has had success in entity recognition, topic recognition, summarization, and sentiment analysis, but models trained in one domain don’t generalize well to other domains.
ii)Graph based or Network Data:
In graph theory, a graph is a mathematical structure to model pair-wise relationships between objects.
Graph or network data is, in short, data that focuses on the relationship or adjacency of objects.
The graph structures use nodes, edges, and properties to represent and store graphical data. Graph-based data is a natural way to represent social networks.
iii)Audio, Image & Video:
Audio, image, and video are data types that pose specific challenges to a data scientist.
MLBAM (Major League Baseball Advanced Media) announced in 2014 that they’ll increase video capture to approximately 7 TB per game for the purpose of live, in-game analytics. High-speed cameras at stadiums will capture ball and athlete movements to calculate in real time, for example, the path taken by a defender relative to two baselines.
iv)Streaming Data:
Streaming data is data that is generated continuously by thousands of data sources, which typically send in the data records simultaneously, and in small sizes (order of Kilobytes).
Examples are the-Log files generated by customers using your mobile or web applications, online game activity, “What’s trending” on Twitter, live sporting or music events, and the stock market.
Why do we need data science?
One of the reasons for the acceleration of data science in recent years is the enormous volume of data currently available and being generated. Not only are huge amounts of data being collected about many aspects of the world and our lives, but we concurrently have the rise of inexpensive computing. This has formed the perfect storm in which we have rich data and the tools to analyze it. Advancing computer memory capacities, more enhanced software, more competent processors, and now, more numerous data scientists with the skills to put this to use and solve questions using the data!
What is big data?
We frequently hear the term Big Data. So it deserves an introduction here – since it has been so integral to the rise of data science.
What does big data mean?
Big Data literally means large amounts of data. Big data is the pillar behind the idea that one can make useful inferences with a large body of data that wasn’t possible before with smaller datasets. So extremely large data sets may be analyzed computationally to reveal patterns, trends, and associations that are not transparent or easy to identify.
Why is everyone interested in Big Data?
Big data is everywhere!
Every time you go to the web and do something that data is collected, every time you buy something from one of the e-commerce your data is collected. Whenever you go to store data is collected at the point of sale, when you do Bank transactions that data is there, when you go to Social networks like Facebook, Twitter that data is collected. Now, these are more social data, but the same thing is starting to happen with real engineering plants. Real-time data is collected from plants all over the world. Not only these if you are doing much more sophisticated simulation, molecular simulations, which generates tons of data that is also collected and stored.
How much data is Big Data?
- Google processes 20 Petabytes(PB) per day (2008)
- Facebook has 2.5 PB of user data + 15 TB per day (2009)
- eBay has 6.5 PB of user data + 50 TB per day (2009)
- CERN’s Large Hadron Collider(LHC) generates 15 PB a year
Why do data science?
Speaking of demand, there is an immense need for individuals with data science skills. According to LinkedIn U.S. Emerging Jobs Report, 2020 Data Scientist ranked #3 with 37% annual growth. This field has topped the Emerging Jobs list for three years running.
Moreover, according to Glassdoor, in which they listed the top 50 most satisfying jobs in America, Data Scientist is #3 job in the US in 2020, based on job satisfaction(4.0/5), salary($107,801), and demand.
So this is a great time to be getting into data science – not only do we have more numerous data, and more numerous tools for gathering, warehousing, and interpreting it, but the need for data scientists is growing frequently and perceived as essential in many diverse sectors, not just business and academia.
Data science in action!
One famous example of data science in action is from 2009, in which some researchers at Google analyzed 50 million commonly searched words over a five year period and compared them against CDC(Centers for Disease Control and Prevention) data on flu outbreaks. Their aim was to understand if some particular searches harmonized with outbreaks of the flu.
One of the advantages of data science and working with big data is that it can distinguish correlations; in this case, they distinguished 45 words that had a strong correlation with the CDC flu outbreak data. And using this data, they were able to predict flu outbreaks based only on usual Google searches! Without this mass amount of data, these 45 words could not have been predicted beforehand.
What is data?
As we have used some time discussing what data science is, it’s necessary to spend some time looking at what exactly data is. Wikipedia defines data as,
A set of values of qualitative or quantitative variables.
This definition focuses more on what data entails. And although it is a reasonably short definition. Let’s take a second to parse this and focus on each component individually.
- A set of values: The first term to concentrate on is “a set of values” – to have data, we require a set of values to include. In statistics, this set of values is known as the population. For example, that set of values needed to answer your question might be all websites or applications or it might be the set of all people getting a particular drug or set of people visiting a particular website. But generally, it’s a set of things that you’re going to make measurements on.
- Variables: The next thing to focus on is “variables” – variables are measurements or characteristics of an item. For example, you could be measuring the weight of a person, or you are estimating the amount of time a person visits on a website or app. Or it may be a further qualitative characteristic you are trying to measure, like what a person clicks on a website, or whether you think the person visiting is male or female.
- Qualitative and quantitative variables: Finally, we have both “qualitative and quantitative variables“. Qualitative variables are information about qualities. They are things like country of origin, gender, religion, etc. They’re usually represented by words, not numbers, and they are not indexed or ordered. On the other hand, quantitative variables are information regarding quantities. Quantitative measurements are normally represented by numbers and are estimated on a constant ordered scale; they’re something like weight, height, age, and blood pressure.
The Process of Data Science
The parts involved in a complete data science project are,

- Forming the question: Every Data Science Project starts with a question that is to be answered with data. That means that ‘forming the question’ is an important first step in the process. When beginning with a data science project, it’s good to have your question is clearly defined. Further questions may arise as you perform the analysis, but understanding what you need to answer with your analysis is a very significant first step.
- Finding or generating the data: The second step is “finding or generating the data” you’re going to use to answer that question. The generation of data can be obtained in any random format. So, according to the approach chosen and the output to be obtained, the data collected should be validated. Thus, if required one can gather more data or discard the irrelevant data.
- Data are then analyzed: With the question solidified and data in hand, the “data are then analyzed“. This can be done in two parts.
- Exploring the data: In this step, you study and preprocess data for modeling. You’ll be capable to perform data cleaning and visualization. This will aid to find the differences and establish a connection among the factors. Once you have completed the step it’s time to perform exploratory analytics on it.
- Modelling the data: In this step, you will generate datasets for training and testing purposes. You may interpret various learning methods like classification and clustering and at last, complete the most excellent fit technique to build the show. In short, that means using some statistical or machine learning techniques to analyze the data and answer your question.
- Communicated to others: After drawing conclusions from this analysis, the project has to be “communicated to others”. A significant component of any data science project is adequately describing the output of the project. Sometimes this is a report you send to your boss or it may be a blog post.
Some Cool Data Science Projects:
The following are some cool data science projects. In each project, the author had a question, and they wanted to solve the question. And they utilized data to solve that question. They analyzed and visualized the data. Then, they wrote blog posts to communicate their results. Have a look to know more about the topics and to see how others work through the data science project and deliver their results!
Some Important Statistical Insights
Stackoverflow Developer Survey, 2020 – Developer Roles
According to StackOverflow developer survey, 2020 – developer roles, about 8.1% of respondents identify as Data scientists or machine learning specialists.
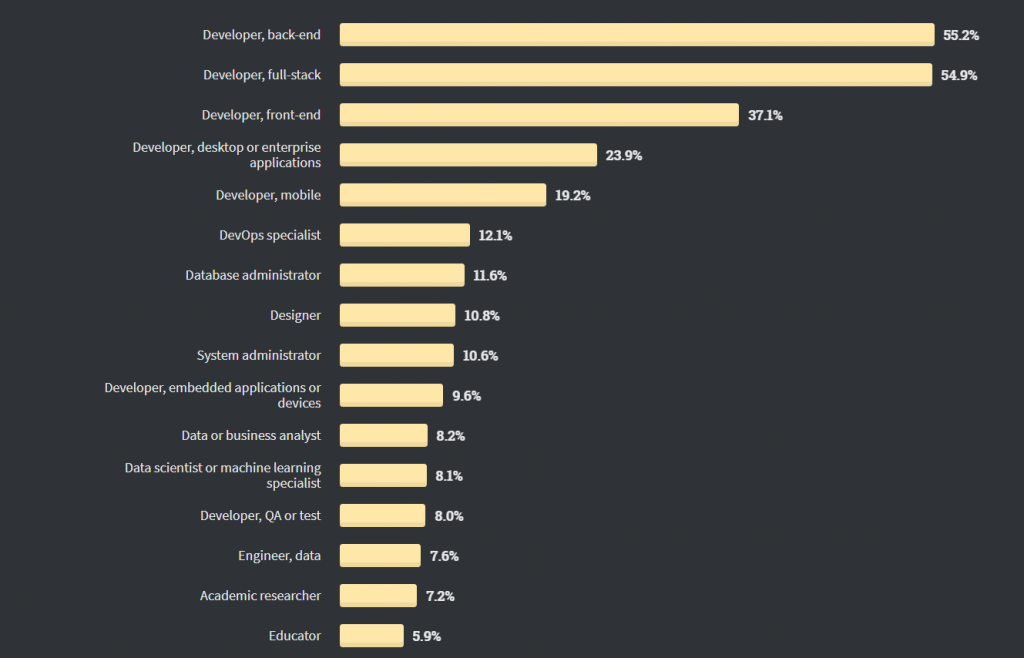
Stackoverflow Developer Survey, 2020 – Developer Roles
The most in-demand data science skills of 2019

How to Become More Marketable as a Data Scientist
Share your thoughts in the comments
Please Login to comment...