Data Mining Process
Last Updated :
06 May, 2023
INTRODUCTION:
The data mining process typically involves the following steps:
Business Understanding: This step involves understanding the problem that needs to be solved and defining the objectives of the data mining project. This includes identifying the business problem, understanding the goals and objectives of the project, and defining the KPIs that will be used to measure success. This step is important because it helps ensure that the data mining project is aligned with business goals and objectives.
Data Understanding: This step involves collecting and exploring the data to gain a better understanding of its structure, quality, and content. This includes understanding the sources of the data, identifying any data quality issues, and exploring the data to identify patterns and relationships. This step is important because it helps ensure that the data is suitable for analysis.
Data Preparation: This step involves preparing the data for analysis. This includes cleaning the data to remove any errors or inconsistencies, transforming the data to make it suitable for analysis, and integrating the data from different sources to create a single dataset. This step is important because it ensures that the data is in a format that can be used for modeling.
Modeling: This step involves building a predictive model using machine learning algorithms. This includes selecting an appropriate algorithm, training the model on the data, and evaluating its performance. This step is important because it is the heart of the data mining process and involves developing a model that can accurately predict outcomes on new data.
Evaluation: This step involves evaluating the performance of the model. This includes using statistical measures to assess how well the model is able to predict outcomes on new data. This step is important because it helps ensure that the model is accurate and can be used in the real world.
Deployment: This step involves deploying the model into the production environment. This includes integrating the model into existing systems and processes to make predictions in real-time. This step is important because it allows the model to be used in a practical setting and to generate value for the organization.
Data Mining refers to extracting or mining knowledge from large amounts of data. The term is actually a misnomer. Thus, data mining should have been more appropriately named as knowledge mining which emphasis on mining from large amounts of data. It is computational process of discovering patterns in large data sets involving methods at intersection of artificial intelligence, machine learning, statistics, and database systems. The overall goal of data mining process is to extract information from a data set and transform it into an understandable structure for further use. It is also defined as extraction of interesting (non-trivial, implicit, previously unknown and potentially useful) patterns or knowledge from a huge amount of data. Data mining is a rapidly growing field that is concerned with developing techniques to assist managers and decision-makers to make intelligent use of a huge amount of repositories. Alternative names for Data Mining :
1. Knowledge discovery (mining) in databases (KDD)
2. Knowledge extraction
3. Data/pattern analysis
4. Data archaeology
5. Data dredging
6. Information harvesting
7. Business intelligence
Data Mining and Business Intelligence : 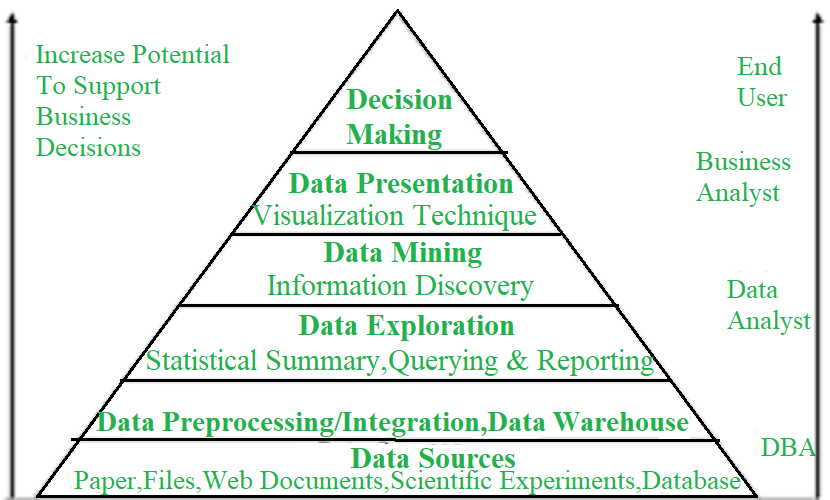 Key properties of Data Mining :
Key properties of Data Mining :
1. Automatic discovery of patterns
2. Prediction of likely outcomes
3. Creation of actionable information
4. Focus on large datasets and databases
Data Mining : Confluence of Multiple Disciplines – 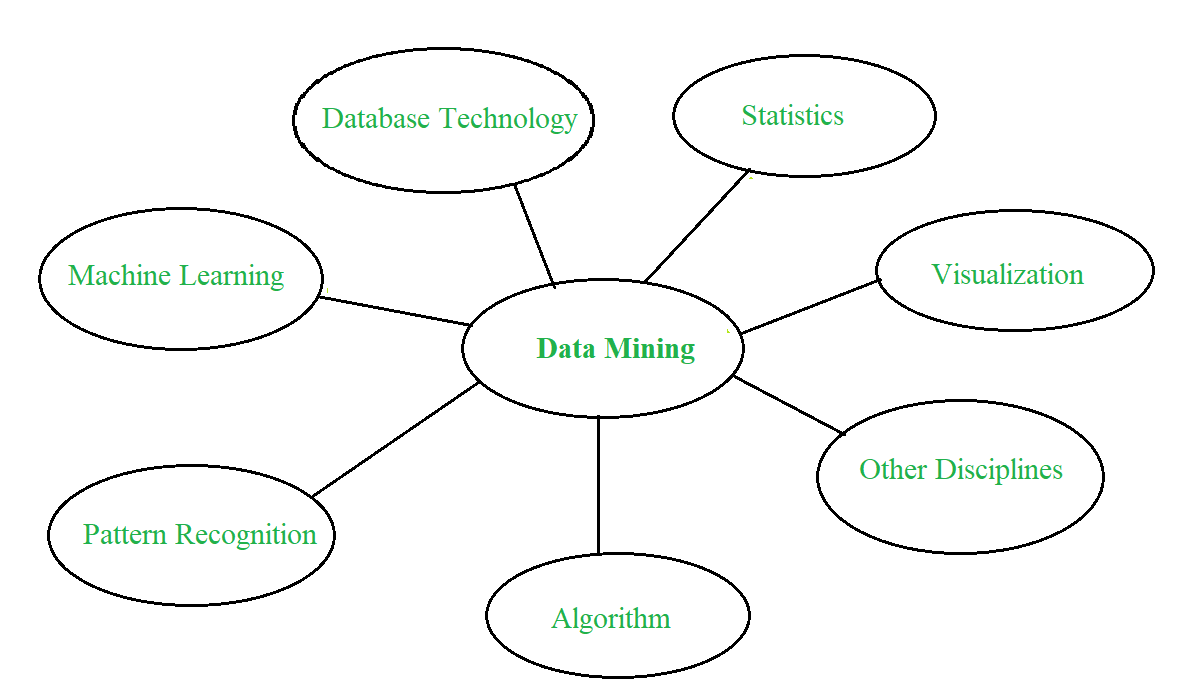 Data Mining Process : Data Mining is a process of discovering various models, summaries, and derived values from a given collection of data. The general experimental procedure adapted to data-mining problem involves following steps :
Data Mining Process : Data Mining is a process of discovering various models, summaries, and derived values from a given collection of data. The general experimental procedure adapted to data-mining problem involves following steps :
- State problem and formulate hypothesis – In this step, a modeler usually specifies a group of variables for unknown dependency and, if possible, a general sort of this dependency as an initial hypothesis. There could also be several hypotheses formulated for one problem at this stage. The primary step requires combined expertise of an application domain and a data-mining model. In practice, it always means an in-depth interaction between data-mining expert and application expert. In successful data-mining applications, this cooperation does not stop within initial phase. It continues during whole data-mining process.
- Collect data – This step cares about how information is generated and picked up. Generally, there are two distinct possibilities. The primary is when data-generation process is under control of an expert (modeler). This approach is understood as a designed experiment. The second possibility is when expert cannot influence data generation process. This is often referred to as observational approach. An observational setting, namely, random data generation, is assumed in most data-mining applications. Typically, sampling distribution is totally unknown after data are collected, or it is partially and implicitly given within data-collection procedure. It is vital, however, to know how data collection affects its theoretical distribution since such a piece of prior knowledge is often useful for modeling and, later, for ultimate interpretation of results. Also, it is important to form sure that information used for estimating a model and therefore data used later for testing and applying a model come from an equivalent, unknown, sampling distribution. If this is often not case, estimated model cannot be successfully utilized in a final application of results.
- Data Preprocessing – In the observational setting, data is usually “collected” from prevailing databases, data warehouses, and data marts. Data preprocessing usually includes a minimum of two common tasks :
- (i) Outlier Detection (and removal) : Outliers are unusual data values that are not according to most observations. Commonly, outliers result from measurement errors, coding, and recording errors, and, sometimes, are natural, abnormal values. Such non-representative samples can seriously affect model produced later. There are two strategies for handling outliers : Detect and eventually remove outliers as a neighborhood of preprocessing phase. And Develop robust modeling methods that are insensitive to outliers.
- (ii) Scaling, encoding, and selecting features : Data preprocessing includes several steps like variable scaling and differing types of encoding. For instance, one feature with range [0, 1] and other with range [100, 1000] will not have an equivalent weight within applied technique. They are going to also influence ultimate data-mining results differently. Therefore, it is recommended to scale them and convey both features to an equivalent weight for further analysis. Also, application-specific encoding methods usually achieve dimensionality reduction by providing a smaller number of informative features for subsequent data modeling.
- Estimate model – The selection and implementation of acceptable data-mining technique is that main task during this phase. This process is not straightforward. Usually, in practice, implementation is predicated on several models, and selecting simplest one is a further task.
- Interpret model and draw conclusions – In most cases, data-mining models should help in deciding. Hence, such models got to be interpretable so as to be useful because humans are not likely to base their decisions on complex “black-box” models. Note that goals of accuracy of model and accuracy of its interpretation are somewhat contradictory. Usually, simple models are more interpretable, but they are also less accurate. Modern data-mining methods are expected to yield highly accurate results using high dimensional models. The matter of interpreting these models, also vital, is taken into account a separate task, with specific techniques to validate results.
 Classification of Data Mining Systems :
Classification of Data Mining Systems :
1. Database Technology
2. Statistics
3. Machine Learning
4. Information Science
5. Visualization
- Major issues in Data Mining :
- Mining different kinds of knowledge in databases – The need for different users is not same. Different users may be interested in different kinds of knowledge. Therefore it is necessary for data mining to cover a broad range of knowledge discovery tasks.
- Interactive mining of knowledge at multiple levels of abstraction – The data mining process needs to be interactive because it allows users to focus on search for patterns, providing and refining data mining requests based on returned results.
- Incorporation of background knowledge – To guide discovery process and to express discovered patterns, background knowledge can be used to express discovered patterns not only in concise terms but at multiple levels of abstraction.
- Data mining query languages and ad-hoc data mining – Data Mining Query language that allows user to describe ad-hoc mining tasks should be integrated with a data warehouse query language and optimized for efficient and flexible data mining.
- Presentation and visualization of data mining results – Once patterns are discovered it needs to be expressed in high-level languages, visual representations. These representations should be easily understandable by users.
- Handling noisy or incomplete data – The data cleaning methods are required that can handle noise, incomplete objects while mining data regularities. If data cleaning methods are not there then accuracy of discovered patterns will be poor.
- Pattern evaluation – It refers to interestingness of problem. The patterns discovered should be interesting because either they represent common knowledge or lack of novelty.
- Efficiency and scalability of data mining algorithms – In order to effectively extract information from huge amount of data in databases, data mining algorithm must be efficient and scalable.
- Parallel, distributed, and incremental mining algorithms – The factors such as huge size of databases, wide distribution of data, and complexity of data mining methods motivate development of parallel and distributed data mining algorithms. These algorithms divide data into partitions that are further processed parallel. Then results from partitions are merged. The incremental algorithms update databases without having mined data again from scratch.
Advantaged or disadvantages:
Advantages of Data Mining:
- Improved decision making: Data mining can help organizations make better decisions by providing them with valuable insights and knowledge about their data.
- Increased efficiency: Data mining can automate repetitive and time-consuming tasks, such as data cleaning and data preparation, which can help organizations save time and money.
- Better customer service: Data mining can help organizations gain a better understanding of their customers’ needs and preferences, which can help them provide better customer service.
- Fraud detection: Data mining can be used to detect fraudulent activities by identifying patterns and anomalies in the data that may indicate fraud.
- Predictive modeling: Data mining can be used to build predictive models that can be used to forecast future trends and patterns.
Disadvantages of Data Mining:
- Privacy concerns: Data mining can raise privacy concerns as it involves collecting and analyzing large amounts of data, which can include sensitive information about individuals.
- Complexity: Data mining can be a complex process that requires specialized skills and knowledge to implement and interpret the results.
- Unintended consequences: Data mining can lead to unintended consequences, such as bias or discrimination, if the data or models are not properly understood or used.
- Data Quality: Data mining process heavily depends on the quality of data, if data is not accurate or consistent, the results can be misleading
- High cost: Data mining can be an expensive process, requiring significant investments in hardware, software, and personnel.
Share your thoughts in the comments
Please Login to comment...