Data Mining: Data Warehouse Process
Last Updated :
25 Apr, 2023
INTRODUCTION:
Data warehousing and data mining are closely related processes that are used to extract valuable insights from large amounts of data. The data warehouse process is a multi-step process that involves the following steps:
- Data Extraction: The first step in the data warehouse process is to extract data from various sources such as transactional systems, spreadsheets, and flat files.
- Data Cleaning: After the data is extracted, it is cleaned to remove any inconsistencies, errors, or duplicates. This step also includes data validation to ensure that the data is accurate and complete.
- Data Transformation: In this step, the extracted and cleaned data is transformed into a format that is suitable for loading into the data warehouse. This may involve converting data types, combining data from multiple sources, or creating new data fields.
- Data Loading: After the data is transformed, it is loaded into the data warehouse. This step involves creating the physical data structures and loading the data into the warehouse.
- Data Indexing: After the data is loaded into the data warehouse, it is indexed to make it easy to search and retrieve the data. This step also involves creating summary tables and materialized views to improve query performance.
- Data Maintenance: The final step in the data warehouse process is to maintain the data and ensure that it is accurate and up-to-date. This may involve periodically refreshing the data, archiving old data, and monitoring the data for errors or inconsistencies.
The data warehouse process is an iterative process that is repeated as new data is added to the warehouse. It is a crucial step for data mining process, as it allows for the storage, management and organization of large amount of data which is needed to be mined. Data mining process can be applied to the data in the data warehouse to uncover hidden patterns, relationships, and insights that can be used to make informed business decisions.
Data Warehouses are information gathered from multiple sources and saved under a schema that is living on the identical site. It is made with the aid of diverse techniques, inclusive of the following processes:
1. Data Cleanup: Data cleaning is the way of preparing statistics for analysis with the help of getting rid of or enhancing incorrect, incomplete, irrelevant, duplicate, or irregularly formatted information. This fact is no longer necessary or beneficial if you want to research the statistics because it is able to interrupt the technique or supply false results.
2. Data Integration: Data integration is the process of integrating data from different assets into a unified view. The integration method starts with a startup and includes steps that include refinement, ETL mapping, and conversion. Data integration ultimately permits analytics tools to create powerful and cheap enterprise intelligence. In a typical data integration procedure, the client sends a request for information to the master server. The master server prepares the vital records for internal and external assets. Extracts facts from sources and then integrates them into a single information set. It is then returned to the client for use.
3. Data Transformation: The process of converting information from one layout or shape to another is referred to as data transformation. Data transformation is critical for features that include data integration and information management. Data transformation has several capabilities: you can change the record types based on the needs of your project; enrich or aggregate the records by removing invalid or duplicate data. Generally, the technique consists of two stages.
In the first step, you should:
- Perform an information search that identifies assets and data types.
- Determine the structure and information changes that occur.
- Mapping data to discover how character fields are mapped, edited, inserted, filtered, and stored.
In the second step, you must:
- Extract data from the original source. The size of the supply can range from a connected tool to a dependable useful resource along with a database or streaming resources, including telemetry or logging files from clients who use your web application.
- Send data to the target site.
- The target may be a database or a data warehouse that manages structured and unstructured records.
4. Loading Data: Data loading is the process of copying and loading data from a report, folder, or application to a database or similar utility. This is usually done via copying digital data from the source and pasting or loading the records into a data warehouse or processing tool. Data-loading is used in data extraction and loading methods. Typically, such information is loaded in a different format than the original location of the source.
5. Data Refreshing: In this process, the data stored in the warehouse is periodically refreshed so that it maintains its integrity. A data warehouse is a model of multidimensional data structures that are known as “Data Cubes” in which every dimension represents an attribute or different set of attributes in the schema of the data and each cell is used to store the value. Data is gathered from various sources such as hospitals, banks, organizations, and many more and goes through a process called ETL (Extract, Transform, Load).
- Extract: This process reads the data from the database of various sources.
- Transform: It transforms the data stored inside the databases into data cubes so that it can be loaded into the warehouse.
- Load: It is a process of writing the transformed data into the data warehouse.
This process can be seen in the illustration below: 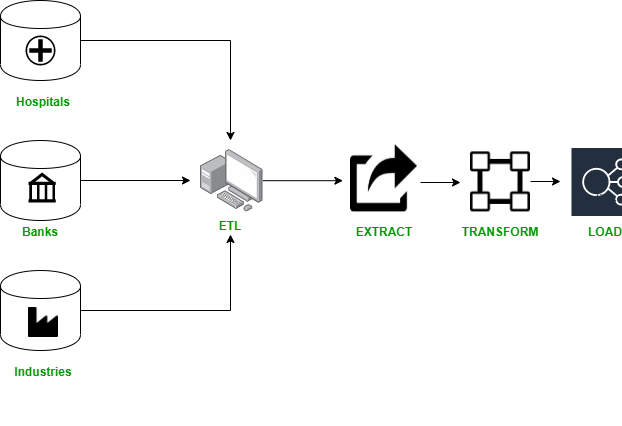
Building and maintaining a data warehouse involves several challenges, including:
Data quality: Ensuring data quality in a data warehouse is a major challenge. The data coming from various sources may have inconsistencies, duplications, and inaccuracies, which can affect the overall quality of the data in the warehouse.
Data integration: Integrating data from various sources into a data warehouse can be challenging, especially when dealing with data that is structured differently or has different formats.
Data consistency: Maintaining data consistency across various data sources and over time is a challenge. Changes in the source systems can affect the consistency of the data in the warehouse.
Data governance: Managing the access, use, and security of the data in the warehouse is another challenge. Ensuring compliance with legal and regulatory requirements can also be challenging.
Performance: Ensuring that the data warehouse performs efficiently and delivers fast query response times can be a challenge, particularly as the volume of data increases over time.
Data modeling: Designing an effective data model that reflects the needs of the organization and optimizes query performance can be a challenge.
Data security: Ensuring the security of the data in the warehouse is a critical challenge, particularly as the data warehouse contains sensitive information.
Resource allocation: Building and maintaining a data warehouse requires significant resources, including skilled personnel, hardware, and software, which can be a challenge to allocate and manage effectively.
ADVANTAGES OR DISADVANTAGES:
Data warehousing and data mining can have both advantages and disadvantages.
Advantages:
- Improved decision making: Data warehousing and data mining can help to improve decision making by providing insights and information that would otherwise be difficult or impossible to obtain.
- Increased efficiency: Data warehousing and data mining can help to increase efficiency by automating the process of extracting, cleaning, and analyzing data.
- Improved data quality: Data warehousing and data mining can help to improve the quality of data by identifying and correcting errors, inconsistencies, and missing data.
- Improved data security: Data warehousing and data mining can help to improve data security by providing a central repository for storing data and controlling access to that data.
- Improved scalability: Data warehousing and data mining can help to improve scalability by providing a way to manage and analyze large amounts of data.
Disadvantages:
- High cost: Data warehousing and data mining can be expensive to implement and maintain, especially for organizations with limited resources.
- Complexity: Data warehousing and data mining can be complex and difficult to implement, especially for organizations that lack the necessary expertise or resources.
- Data privacy concerns: Data warehousing and data mining can raise concerns about data privacy, as large amounts of data are collected, stored, and analyzed.
- Limited flexibility: Data warehousing and data mining can be limited in terms of flexibility, as they are designed to work with structured data and may not be suitable for unstructured data.
- Limited scalability: Data warehousing and data mining can be limited in terms of scalability, as they may not be able to handle very large amounts of data.
Overall, data warehousing and data mining can be powerful tools for organizations that need to extract insights from large amounts of data. However, they also come with their own set of challenges and limitations, and organizations need to carefully consider the costs and benefits before implementing them.
Features of Data Warehouse: Please refer – Features of Data Warehouse.
Share your thoughts in the comments
Please Login to comment...