Crawpy – Yet Another Content Discovery Tool
Last Updated :
04 Jan, 2022
Crawpy is a free and open-source tool available on GitHub. This tool is a free and open-source tool this means you can download and install this tool free of cost. This tool is also called yet another content discovery tool written in python language. Crawpy is developed to work asynchronously this means that the tool can reach maximum limits which makes it fast than any other content discovery tool. This tool filter codes and filter words of the domain which the user provide. Crawly has many flags which make its user perform fuzzing in depth. Crawpy also generates reports after performing functioning over the domain. These reports can be used to check results. Crawpy can be used to scan multiple URLs simultaneously.
What makes this tool different than others:
- Crawpy can scan multiple URL’s.
- Crawpy can generate reports after the scanning. You can generate reports of URL scanning.
- Crawpy has a recursive scan mode which can give the status code in depth after the scanning.
- Crawpy has many flags which can help its user in fuzzing.
- Crawpy has a calibration mode that can apply the filter automatically during the scanning of a URL.
- Crawpy can work asynchronously.
Installation
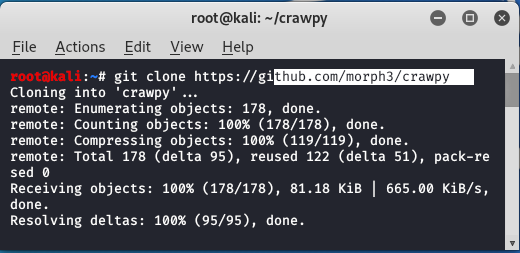
Step 1: Open your kali Linux operating system and use the following command to install the tool.
git clone https://github.com/morph3/crawpy
Step 2: Now use the following command to install dependencies of the tool.
pip3 install -r requirements.txt
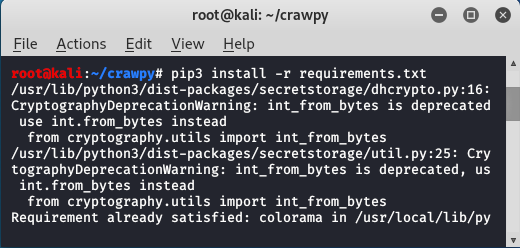
All the dependencies has been installed. Now we will see examples to use the tool.
Usage
Example 1: Use the Crawpy tool to perform fuzzing on a domain.
python3 crawpy.py -u https://facebook.com/FUZZ -w ./common.txt -k -ac -e .php,.html
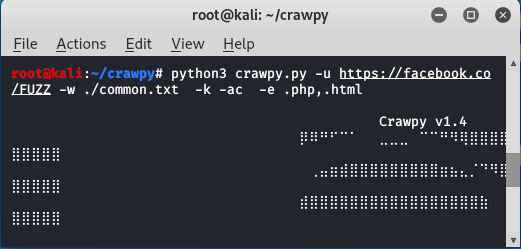
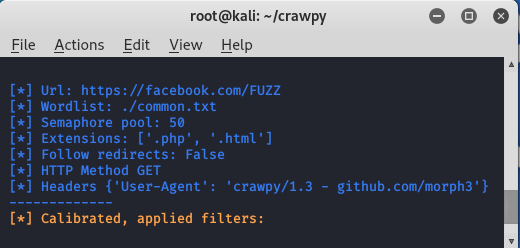
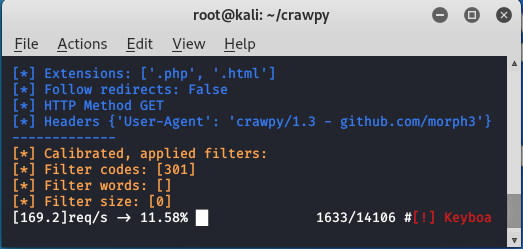
The tool started fuzzing.
Example 2: Use the Crawpy tool to perform fuzzing/content discovery on a domain,
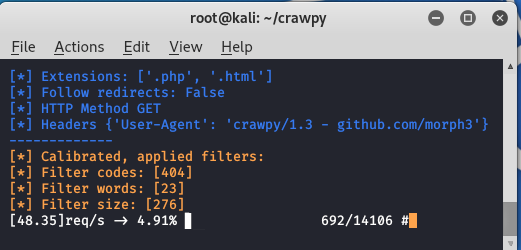
python3 crawpy.py -u https://morph3sec.com/FUZZ -w ./common.txt -e .php,.html -t 20 -ac -k
Share your thoughts in the comments
Please Login to comment...