C-SCAN Disk Scheduling Algorithm
Last Updated :
20 Sep, 2023
Given an array of disk track numbers and initial head position, our task is to find the total number of seek operations to access all the requested tracks if a C-SCAN Disk Scheduling algorithm is used.
The Circular SCAN (C-SCAN) Scheduling Algorithm is a modified version of the SCAN Disk Scheduling Algorithm that deals with the inefficiency of the SCAN algorithm by servicing the requests more uniformly. Like SCAN (Elevator Algorithm), C-SCAN moves the head from one end servicing all the requests to the other end. However, as soon as the head reaches the other end, it immediately returns to the beginning of the disk without servicing any requests on the return trip (see chart below) and starts servicing again once reaches the beginning. This is also known as the “Circular Elevator Algorithm” as it essentially treats the cylinders as a circular list that wraps around from the final cylinder to the first one.
Advantages of C-SCAN (Circular Elevator) Disk Scheduling Algorithm
- Works well with moderate to heavy loads.
- It provides better response time and uniform waiting time.
Disadvantages of C-SCAN (Circular Elevator) Disk Scheduling Algorithm
- May not be fair to service requests for tracks at the extreme end.
- It has more seek movements as compared to the SCAN Algorithm.
Algorithm
Step 1: Let the Request array represents an array storing indexes of tracks that have been requested in ascending order of their time of arrival. ‘head’ is the position of the disk head.
Step 2: The head services only in the right direction from 0 to the disk size.
Step 3: While moving in the left direction do not service any of the tracks.
Step 4: When we reach the beginning(left end) reverse the direction.
Step 5: While moving in the right direction it services all tracks one by one.
Step 6: While moving in the right direction calculate the absolute distance of the track from the head.
Step 7: Increment the total seek count with this distance.
Step 8: Currently serviced track position now becomes the new head position.
Step 9: Go to step 6 until we reach the right end of the disk.
Step 9: If we reach the right end of the disk reverse the direction and go to step 3 until all tracks in the request array have not been serviced.
Example:
Input:
Request sequence = {176, 79, 34, 60, 92, 11, 41, 114}
Initial head position = 50
Direction = right(We are moving from left to right)
Output:
Initial position of head: 50
Total number of seek operations = 389
Seek Sequence: 60, 79, 92, 114, 176, 199, 0, 11, 34, 41
The following chart shows the sequence in which requested tracks are serviced using SCAN.
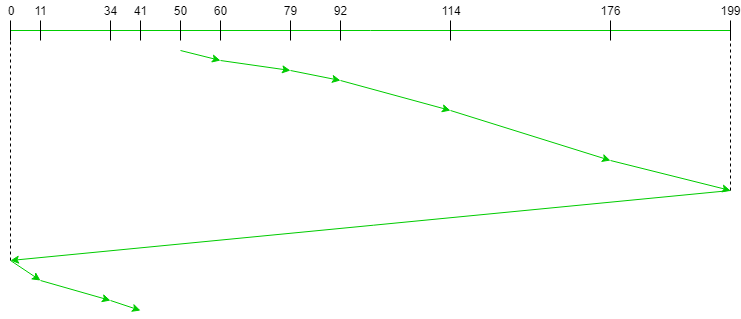
C-SCAN Disk Scheduling Algorithm
Therefore, the total seek count is calculated as:
= (60-50) + (79-60) + (92-79) + (114-92) + (176-114) + (199-176) + (199-0) + (11-0) + (34-11) + (41-34)
= 389
Implementation
The implementation of the C-SCAN algorithm is given below.
Note: The distance variable is used to store the absolute distance between the head and the current track position. disk_size is the size of the disk. Vectors left and right store all the request tracks on the left-hand side and the right-hand side of the initial head position respectively.
C++
#include <bits/stdc++.h>
using namespace std;
int size = 8;
int disk_size = 200;
void CSCAN(int arr[], int head)
{
int seek_count = 0;
int distance, cur_track;
vector<int> left, right;
vector<int> seek_sequence;
left.push_back(0);
right.push_back(disk_size - 1);
for (int i = 0; i < size; i++) {
if (arr[i] < head)
left.push_back(arr[i]);
if (arr[i] > head)
right.push_back(arr[i]);
}
std::sort(left.begin(), left.end());
std::sort(right.begin(), right.end());
for (int i = 0; i < right.size(); i++) {
cur_track = right[i];
seek_sequence.push_back(cur_track);
distance = abs(cur_track - head);
seek_count += distance;
head = cur_track;
}
head = 0;
seek_count += (disk_size - 1);
for (int i = 0; i < left.size(); i++) {
cur_track = left[i];
seek_sequence.push_back(cur_track);
distance = abs(cur_track - head);
seek_count += distance;
head = cur_track;
}
cout << "Total number of seek operations = "
<< seek_count << endl;
cout << "Seek Sequence is" << endl;
for (int i = 0; i < seek_sequence.size(); i++) {
cout << seek_sequence[i] << endl;
}
}
int main()
{
int arr[size] = { 176, 79, 34, 60, 92, 11, 41, 114 };
int head = 50;
cout << "Initial position of head: " << head << endl;
CSCAN(arr, head);
return 0;
}
|
Java
import java.util.*;
class GFG {
static int size = 8;
static int disk_size = 200;
public static void CSCAN(int arr[], int head)
{
int seek_count = 0;
int distance, cur_track;
Vector<Integer> left = new Vector<Integer>();
Vector<Integer> right = new Vector<Integer>();
Vector<Integer> seek_sequence
= new Vector<Integer>();
left.add(0);
right.add(disk_size - 1);
for (int i = 0; i < size; i++) {
if (arr[i] < head)
left.add(arr[i]);
if (arr[i] > head)
right.add(arr[i]);
}
Collections.sort(left);
Collections.sort(right);
for (int i = 0; i < right.size(); i++) {
cur_track = right.get(i);
seek_sequence.add(cur_track);
distance = Math.abs(cur_track - head);
seek_count += distance;
head = cur_track;
}
head = 0;
seek_count += (disk_size - 1);
for (int i = 0; i < left.size(); i++) {
cur_track = left.get(i);
seek_sequence.add(cur_track);
distance = Math.abs(cur_track - head);
seek_count += distance;
head = cur_track;
}
System.out.println("Total number of seek "
+ "operations = " + seek_count);
System.out.println("Seek Sequence is");
for (int i = 0; i < seek_sequence.size(); i++) {
System.out.println(seek_sequence.get(i));
}
}
public static void main(String[] args) throws Exception
{
int arr[] = { 176, 79, 34, 60, 92, 11, 41, 114 };
int head = 50;
System.out.println("Initial position of head: "
+ head);
CSCAN(arr, head);
}
}
|
Python3
size = 8
disk_size = 200
def CSCAN(arr, head):
seek_count = 0
distance = 0
cur_track = 0
left = []
right = []
seek_sequence = []
left.append(0)
right.append(disk_size - 1)
for i in range(size):
if (arr[i] < head):
left.append(arr[i])
if (arr[i] > head):
right.append(arr[i])
left.sort()
right.sort()
for i in range(len(right)):
cur_track = right[i]
seek_sequence.append(cur_track)
distance = abs(cur_track - head)
seek_count += distance
head = cur_track
head = 0
seek_count += (disk_size - 1)
for i in range(len(left)):
cur_track = left[i]
seek_sequence.append(cur_track)
distance = abs(cur_track - head)
seek_count += distance
head = cur_track
print("Total number of seek operations =",
seek_count)
print("Seek Sequence is")
print(*seek_sequence, sep="\n")
arr = [176, 79, 34, 60,
92, 11, 41, 114]
head = 50
print("Initial position of head:", head)
CSCAN(arr, head)
|
C#
using System;
using System.Collections.Generic;
class GFG {
static int size = 8;
static int disk_size = 200;
static void CSCAN(int[] arr, int head)
{
int seek_count = 0;
int distance, cur_track;
List<int> left = new List<int>();
List<int> right = new List<int>();
List<int> seek_sequence = new List<int>();
left.Add(0);
right.Add(disk_size - 1);
for (int i = 0; i < size; i++) {
if (arr[i] < head)
left.Add(arr[i]);
if (arr[i] > head)
right.Add(arr[i]);
}
left.Sort();
right.Sort();
for (int i = 0; i < right.Count; i++) {
cur_track = right[i];
seek_sequence.Add(cur_track);
distance = Math.Abs(cur_track - head);
seek_count += distance;
head = cur_track;
}
head = 0;
seek_count += (disk_size - 1);
for (int i = 0; i < left.Count; i++) {
cur_track = left[i];
seek_sequence.Add(cur_track);
distance = Math.Abs(cur_track - head);
seek_count += distance;
head = cur_track;
}
Console.WriteLine("Total number of seek "
+ "operations = " + seek_count);
Console.WriteLine("Seek Sequence is");
for (int i = 0; i < seek_sequence.Count; i++) {
Console.WriteLine(seek_sequence[i]);
}
}
static void Main()
{
int[] arr = { 176, 79, 34, 60, 92, 11, 41, 114 };
int head = 50;
Console.WriteLine("Initial position of head: "
+ head);
CSCAN(arr, head);
}
}
|
Javascript
<script>
let size = 8;
let disk_size = 200;
function CSCAN(arr, head)
{
let seek_count = 0;
let distance, cur_track;
let left = [], right = [];
let seek_sequence = [];
left.push(0);
right.push(disk_size - 1);
for (let i = 0; i < size; i++) {
if (arr[i] < head)
left.push(arr[i]);
if (arr[i] > head)
right.push(arr[i]);
}
left.sort(function(a, b){return a - b});
right.sort(function(a, b){return a - b});
for (let i = 0; i < right.length; i++)
{
cur_track = right[i];
seek_sequence.push(cur_track);
distance = Math.abs(cur_track - head);
seek_count += distance;
head = cur_track;
}
head = 0;
seek_count += (disk_size - 1);
for (let i = 0; i < left.length; i++) {
cur_track = left[i];
seek_sequence.push(cur_track);
distance = Math.abs(cur_track - head);
seek_count += distance;
head = cur_track;
}
document.write("Total number of seek operations = " + seek_count + "</br>");
document.write("Seek Sequence is" + "</br>");
for (let i = 0; i < seek_sequence.length; i++)
{
document.write(seek_sequence[i] + "</br>");
}
}
let arr = [ 176, 79, 34, 60, 92, 11, 41, 114 ];
let head = 50;
document.write("Initial position of head: " + head + "</br>");
CSCAN(arr, head);
</script>
|
Output
Initial Position of Head: 50
Total Number of Seek Operations = 389
Seek Sequence: 60, 79, 92, 114, 176, 199, 0, 11, 34, 41
FAQs on C-SCAN Disk Scheduling Algorithm
1. Can C-SCAN Algorithm helps in preventing Starvation?
Answer:
Yes, C-SCAN Algorithm helps in preventing algorithm because it gives guarantee that all requests will be serviced.
2. Is there any characteristic to decide which disk scheduling algorithm we have to use for my device?
Answer:
The choice of Disk Scheduling Algorithm basically depends on the workload of the Disk. For a regular or usual workload, we use SCAN or C-SCAN Algorithm, but for a heavy workload, we use SSTF or LOOK for better performance.
Share your thoughts in the comments
Please Login to comment...