Big Data Analytics Life Cycle
Last Updated :
06 Sep, 2021
In this article, we will discuss the life cycle phases of Big Data Analytics. It differs from traditional data analysis, mainly due to the fact that in big data, volume, variety, and velocity form the basis of data.
The Big Data Analytics Life cycle is divided into nine phases, named as :
- Business Case/Problem Definition
- Data Identification
- Data Acquisition and filtration
- Data Extraction
- Data Munging(Validation and Cleaning)
- Data Aggregation & Representation(Storage)
- Exploratory Data Analysis
- Data Visualization(Preparation for Modeling and Assessment)
- Utilization of analysis results.
Let us discuss each phase :
- Phase I Business Problem Definition –
In this stage, the team learns about the business domain, which presents the motivation and goals for carrying out the analysis. In this stage, the problem is identified, and assumptions are made that how much potential gain a company will make after carrying out the analysis. Important activities in this step include framing the business problem as an analytics challenge that can be addressed in subsequent phases. It helps the decision-makers understand the business resources that will be required to be utilized thereby determining the underlying budget required to carry out the project.
Moreover, it can be determined, whether the problem identified, is a Big Data problem or not, based on the business requirements in the business case. To qualify as a big data problem, the business case should be directly related to one(or more) of the characteristics of volume, velocity, or variety.
- Phase II Data Definition –
Once the business case is identified, now it’s time to find the appropriate datasets to work with. In this stage, analysis is done to see what other companies have done for a similar case.
Depending on the business case and the scope of analysis of the project being addressed, the sources of datasets can be either external or internal to the company. In the case of internal datasets, the datasets can include data collected from internal sources, such as feedback forms, from existing software, On the other hand, for external datasets, the list includes datasets from third-party providers.
- Phase III Data Acquisition and filtration –
Once the source of data is identified, now it is time to gather the data from such sources. This kind of data is mostly unstructured.Then it is subjected to filtration, such as removal of the corrupt data or irrelevant data, which is of no scope to the analysis objective. Here corrupt data means data that may have missing records, or the ones, which include incompatible data types.
After filtration, a copy of the filtered data is stored and compressed, as it can be of use in the future, for some other analysis.
- Phase IV Data Extraction –
Now the data is filtered, but there might be a possibility that some of the entries of the data might be incompatible, to rectify this issue, a separate phase is created, known as the data extraction phase. In this phase, the data, which don’t match with the underlying scope of the analysis, are extracted and transformed in such a form.
- Phase V Data Munging –
As mentioned in phase III, the data is collected from various sources, which results in the data being unstructured. There might be a possibility, that the data might have constraints, that are unsuitable, which can lead to false results. Hence there is a need to clean and validate the data.
It includes removing any invalid data and establishing complex validation rules. There are many ways to validate and clean the data. For example, a dataset might contain few rows, with null entries. If a similar dataset is present, then those entries are copied from that dataset, else those rows are dropped.
- Phase VI Data Aggregation & Representation –
The data is cleansed and validates, against certain rules set by the enterprise. But the data might be spread across multiple datasets, and it is not advisable to work with multiple datasets. Hence, the datasets are joined together. For example: If there are two datasets, namely that of a Student Academic section and Student Personal Details section, then both can be joined together via common fields, i.e. roll number.
This phase calls for intensive operation since the amount of data can be very large. Automation can be brought into consideration, so that these things are executed, without any human intervention.
- Phase VII Exploratory Data Analysis –
Here comes the actual step, the analysis task. Depending on the nature of the big data problem, analysis is carried out. Data analysis can be classified as Confirmatory analysis and Exploratory analysis. In confirmatory analysis, the cause of a phenomenon is analyzed before. The assumption is called the hypothesis. The data is analyzed to approve or disapprove the hypothesis.
This kind of analysis provides definitive answers to some specific questions and confirms whether an assumption was true or not.In an exploratory analysis, the data is explored to obtain information, why a phenomenon occurred. This type of analysis answers “why” a phenomenon occurred. This kind of analysis doesn’t provide definitive, meanwhile, it provides discovery of patterns.
- Phase VIII Data Visualization –
Now we have the answer to some questions, using the information from the data in the datasets. But these answers are still in a form that can’t be presented to business users. A sort of representation is required to obtains value or some conclusion from the analysis. Hence, various tools are used to visualize the data in graphic form, which can easily be interpreted by business users.
Visualization is said to influence the interpretation of the results. Moreover, it allows the users to discover answers to questions that are yet to be formulated.
- Phase IX Utilization of analysis results –
The analysis is done, the results are visualized, now it’s time for the business users to make decisions to utilize the results. The results can be used for optimization, to refine the business process. It can also be used as an input for the systems to enhance performance.
The block diagram of the life cycle is given below :
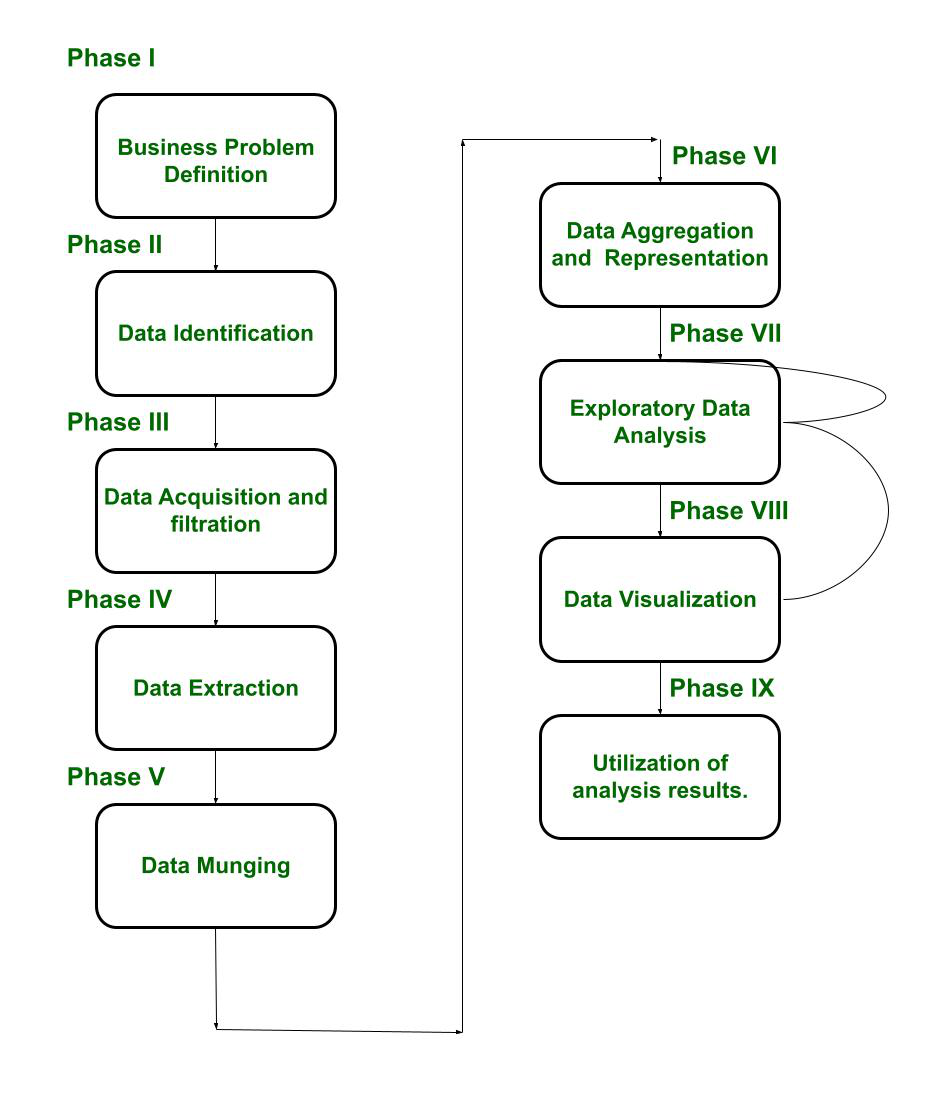
It is evident from the block diagram that Phase VII, i.e. exploratory Data analysis, is modified successively until it is performed satisfactorily. Emphasis is put on error correction. Moreover, one can move back from Phase VIII to Phase VII, if a satisfactory result is not achieved. In this manner, it is ensured that the data is analyzed properly.
Share your thoughts in the comments
Please Login to comment...